
一、介绍
通过多种模式获取的医学图像可以捕获身体组织的补充诊断信息,但考虑到相关的经济和劳动力成本,运行多模式协议带来的负担。医学图像翻译是在不提高成本的情况下扩展检查范围的强大框架,其中未获得的目标模态是根据获取的源模态预测的。翻译的重要临床应用包括对目标模式进行估算,以降低协议冗余或避免有害的造影剂/电离辐射,并通过扩大参与者之间的协议范围和同质性来促进回顾性成像研究的参与。也就是说,医学图像翻译是一个严重不适定的问题,因为给定组织的信号水平在不同模式之间表现出非线性变化。因此,擅长逆问题的基于学习的方法最近已成为医学图像翻译事实上的框架。
基于学习的方法通常旨在捕获给定源图像的目标的条件先验,尽管它们学习先验的方式有所不同。在之前的方法中,生成对抗网络(GAN)因其在合成图像中卓越的真实性而被广泛采用,并在包括 MR 对比和 MRI-CT 之间的翻译等多种任务中成功得到报道 。然而,由于 GAN 通过生成器与判别器的相互作用捕获隐式先验,因此它们可能会遭受训练不稳定的影响,从而影响图像保真度。为了提高稳定性,最近的研究采用了去噪扩散模型(DDM)来捕获显式先验。在DDM中,前向过程通过重复添加高斯噪声来逐渐降低目标图像的质量,直到纯噪声的渐近终点(图1a)。从随机噪声图像开始,逆向过程然后通过网络逐步对输入进行降噪以恢复目标图像,而源图像提供固定引导[34]。尽管 DDM 很稳定,但它会学习从噪声到目标图像的与任务无关的去噪转换,这可能会削弱源图像引导。反过来,考虑到学习的去噪变换和所需的源到目标变换之间的差异,DDM 在医学图像翻译中的表现可能不是最佳的。
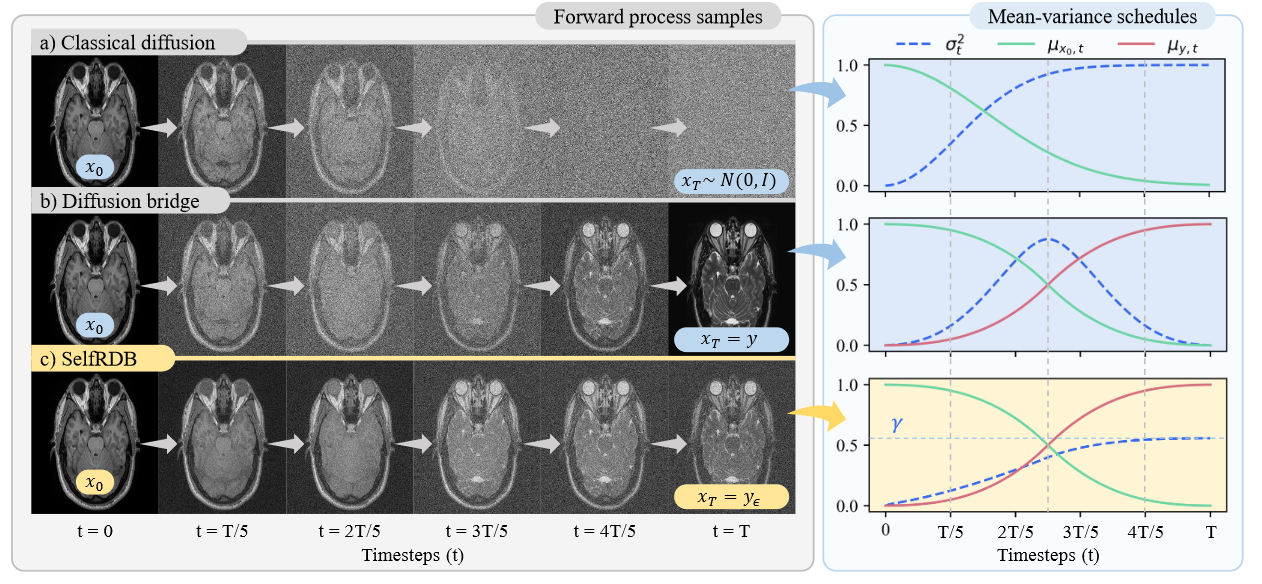
图 1:扩散方法通常将目标图像作为扩散过程的起点\(x_0\),尽管它们在剩余时间步中图像样本的表达可能有所不同。描述了整个前向过程的图像图示以及平均值 \((μ_{x_0},t, μ_y,t)\) 和噪声方差 $(σ^2_t ) $的基础时间表。 (a) 经典扩散:DDM 使用纯噪声图像作为渐近终点 \(x_T\) 。通过将逐渐增加的随机高斯噪声水平添加到目标图像上来获得中间样本。 (b) 扩散桥:常规桥使用源图像作为有限端点。中间样本被视为源-目标图像的凸组合,并被附加噪声破坏。噪声方差在起点和终点为零,在中点达到峰值。 (c) 提议:SelfRDB 是一种新颖的扩散桥,它使用添加噪声的源图像作为端点。中间样本仍然依赖于源-目标图像的凸组合,但 SelfRDB 独特地规定了向终点单调增加的噪声方差。
一种增强基于扩散先验的任务相关性的新兴方法采用了可以直接在两种独立模式之间进行转换的扩散桥。为此,扩散桥分别根据目标图像和源图像定义前向过程的起点和终点(图 1b)。由于连接两种模态的成像算子通常是未知的,中间步骤中的图像样本源自正态分布,其均值是起点和终点的凸组合。启动对源图像的采样,逆过程逐步将源映射到目标图像。最近很少有成像研究成功地利用扩散桥从欠采样或低分辨率测量中重建单模态图像。然而,扩散桥在医学图像翻译中的潜力在很大程度上仍未得到探索,因为现有方法面临着几个关键挑战。常规扩散桥采用在起点处零方差的噪声调度,尽管在扩散过程的中点附近方差较高。终点处的零方差会导致源模态出现硬先验,反映以训练集中的源图像为中心的 Dirac-delta 分布,从而阻碍泛化(图 2a)。同时,中间点的严重噪音会扰乱源到目标的信息传输。此外,扩散桥通常合成中间样本的一次性估计,限制了采样精度。
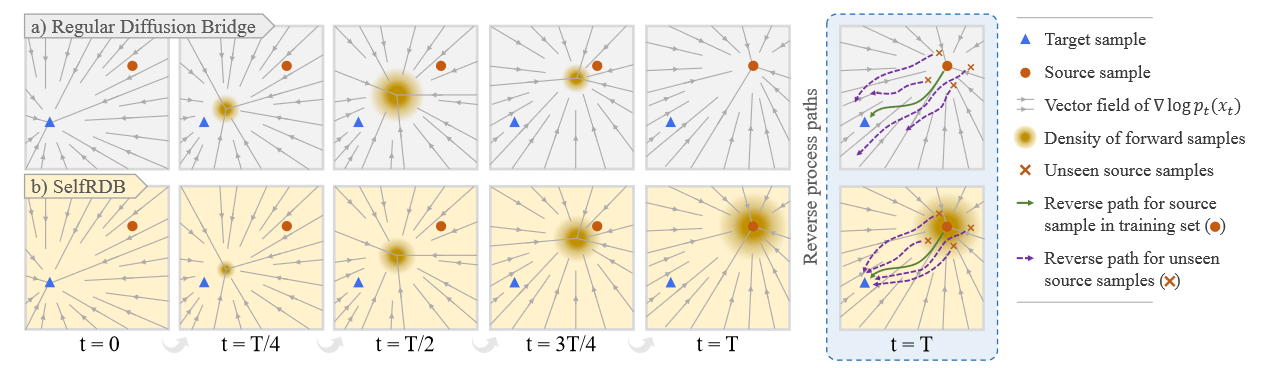
图 2:扩散模型通过基础过程的起点和终点之间的多步转换来学习数据的评分函数。图像样本通常会被高斯噪声破坏,高斯噪声通过掩盖一些原始图像特征来平滑数据分布。平滑可以使数据空间的覆盖更加均匀,从而提高泛化性能。 (a) 常规扩散桥在端点处使用零噪声方差,将其限制为以训练集中的源图像为中心的 Dirac-delta 分布。这可能会损害对训练集之外的源图像的泛化性能(请参见紫色虚线路径)。 (b) SelfRDB 相反使用朝向终点的单调递增方差,因此它是在添加噪声的源图像上进行训练的。这提高了针对训练集和测试集之间源图像变化的鲁棒性(参见紫色虚线路径)。
在这里,我们提出了一种新颖的自洽递归扩散桥 SelfRDB,以提高多模态医学图像翻译的性能。与常规扩散桥不同,SelfRDB 在其前向过程中利用了一种新颖的噪声调度,单调增加方差到对应于添加噪声的源图像的终点(图 1c)。因此,它捕获源模态的软先验以实现改进的泛化,同时它通过在过程中点附近规定较低的噪声来促进模态之间的信息传输(图2b)。为了避免在添加噪声的端点丢失组织信息,SelfRDB 的恢复网络在反向过程中采用来自原始源图像的固定引导。最后,为了提高每个反向步骤的采样精度,SelfRDB对目标图像利用了一种新颖的自洽递归估计过程,并使用这种自洽估计来合成精度更高的中间样本(图3)。对多对比 MRI 和 MRI-CT 翻译进行全面演示。我们的结果清楚地表明 SelfRDB 相对于竞争对手的 GAN 和扩散模型(包括之前的扩散桥)的优越性。
二、方法
三、实验
1.数据集
在两个多对比 MRI 数据集(IXI1、BRATS)和一个多模态 MRI-CT 数据集上进行了实验。在每个数据集中,进行三向分割以创建没有主题重叠的训练集、验证集和测试集。通过仿射变换对受试者的不同体积进行空间记录。每个体积均标准化为平均强度 1,然后体素强度标准化为受试者的 [-1,1] 范围。通过零填充获得一致的 256×256 横截面图像尺寸。
1) IXI 数据集:分析了 40 名健康受试者的 T1-、T2-、PD 加权脑图像,其中 (25,5,10) 名受试者保留用于(训练、验证、测试)。在每卷中,选择了 100 个具有脑组织的轴向横截面。
2) BRATS 数据集:对 55 名神经胶质瘤患者的 T1-、T2-、流体衰减反转恢复 (FLAIR) 加权脑图像进行了分析,其中(25,10,20)名受试者保留用于(训练、验证、测试)。在每一卷中,选择了 100 个含有脑组织的轴向横截面。
3) MRI-CT 数据集:分析了 15 名受试者的骨盆 T1、T2 加权 MRI 和 CT 图像,其中 (9,2,4) 名受试者保留用于(训练、验证、测试)。每卷中选择了 90 个轴向横截面。
2.竞争方法
SelfRDB 是针对最先进的基于扩散和对抗的方法进行论证的。所有竞争方法都是通过配对源和目标模式的监督学习进行训练的。对于每种方法,都执行超参数选择以最大限度地提高验证集的性能。在翻译任务中选择了一组通用参数,包括时期、学习率和损失项权重,这些参数可以实现接近最佳的性能。
1)SelfRDB:SelfRDB由生成器和鉴别器子网络组成。该生成器是通过残差 UNet 主干网实现的,该主干具有 12 个残差阶段,在编码和解码模块之间平均分配。每个残差阶段将编码器中的空间分辨率减半,并将解码器模块中的空间分辨率加倍。可学习时间嵌入是通过多层感知器计算的,该感知器接收 256 维正弦时间编码作为输入。时间嵌入被添加到每个生成器阶段的特征图上。鉴别器是通过 6 个阶段的卷积主干来实现的 。每个阶段将空间分辨率减半,并且时间嵌入也被添加到每个鉴别器阶段的特征图上。交叉验证的超参数为 50 个 epoch,10−4 学习率,T = 1000,γ=2.2,λ1=1,λ2=1。对于 ̃ x* 0 的递归估计,当连续递归之间 ̃ xr 0 的相对变化低于 1% 时,假定收敛。
2)SynDiff:考虑了一种对抗性 DDM 模型,其架构、噪声调度和损失函数均采用。交叉验证的超参数为 50 个 epoch,\(15 \times 10^{−4}\) 学习率,T = 1000,k = 250 步长,对抗性损失权重为 1。
3)DDPM:DDM模型考虑了中采用的架构、噪声调度和损失函数。输入源模态作为反向扩散步骤的固定指导。交叉验证的超参数为 50 个 epoch,\(10^{−4}\) 学习率,T = 1000。
4)\(I^2SB\):考虑了扩散桥模型,其架构、噪声表和损失函数均来自。源模态和目标模态之间映射的前向扩散过程。交叉验证的超参数为 50 个 epoch,\(10^{−4}\) 学习率,T = 1000。
5)pix2pix:考虑采用[27]中采用的架构和损失函数的GAN模型。交叉验证的超参数为 200 个 epoch,学习率为 2x10−4,对抗性损失权重为 1。
3.建模程序
模型通过 PyTorch 框架实现并在 Nvidia RTX 4090 GPU 上执行。训练时,使用 Adam 优化器,\(β_1=0.5\),\(β_2=0.9\)。为了进行评估,从每个横截面的相应源图像合成单个目标图像。通过峰值信噪比 (PSNR) 和结构相似性指数 (SSIM) 指标评估模型性能。在评估之前,所有图像均标准化为 [0,1] 范围。通过非参数 Wilcoxon 符号秩检验检验性能差异的显着性(p<0.05)。
四、实验结果
1. 多对比 MRI 翻译
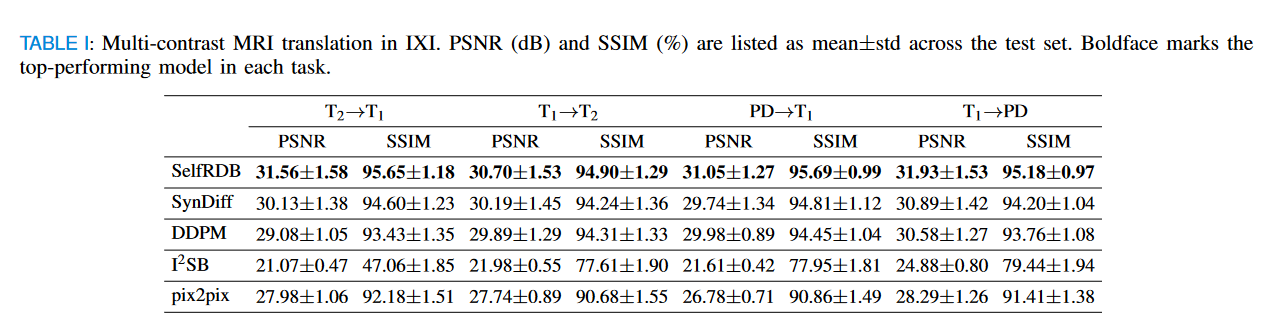
我们首先在多对比 MRI 翻译任务中演示了 SelfRDB。将所提出的方法与 DDM 模型(SynDiff、DDPM)、扩散桥(I2SB)和 GAN 模型(pix2pix)进行比较。首先对包含健康受试者大脑图像的 IXI 数据集进行评估。表 I 列出了 IXI 中的 PSNR 和 SSIM 指标。在每个单独的任务中,SelfRDB 实现的翻译性能明显高于所有基线 (p<0.05)。平均而言,SelfRDB 优于 DDM 1.25dB PSNR、1.13% SSIM,优于扩散桥 8.93dB PSNR、24.77% SSIM,优于 GAN 模型 3.62dB PSNR、4.07% SSIM。由竞争方法合成的代表性目标图像如图 4 所示。在基线中,I2SB 对目标模态的解剖保真度普遍较差,而 pix2pix 则存在明显的结构伪影。同时,DDPM 显示出一定程度的对比度损失和由此导致的组织特征模糊,而 SynDiff 往往会使组织信号过度平坦,从而导致空间分级组织特征的损失。相比之下,SelfRDB 合成的目标图像具有低伪影水平和可靠的精细组织特征描述。
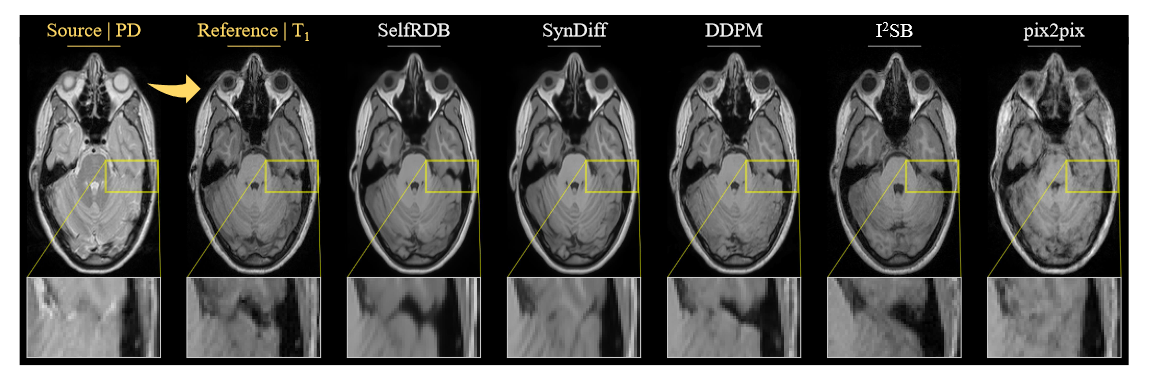
图 4:IXI 数据集中代表性 PD→T1 任务的多对比 MRI 翻译。竞争方法的合成目标图像与参考目标图像(即地面实况)和输入源图像一起显示。放大显示窗口用于突出显示合成性能的差异。

然后,我们在包含神经胶质瘤患者大脑图像的 BRATS 数据集上评估了竞争方法。表 II 列出了 BRATS 中的 PSNR 和 SSIM 指标。我们再次发现,SelfRDB 在每个单独任务的竞争方法中实现了最高的翻译性能 (p<0.05)。平均而言,SelfRDB 优于 DDM 1.49dB PSNR、2.20% SSIM,优于扩散桥 4.39dB PSNR、10.29% SSIM,优于 GAN 模型 1.34dB PSNR、3.35% SSIM。由竞争方法合成的代表性目标图像如图 5 所示。在基线中,I2SB 显示出较差的解剖一致性,pix2pix 存在可见的强度伪影,而 DDPM 显示出一定程度的空间模糊。同时,SynDiff 显示由于信号强度泄漏和源模态图像伪影而导致的总强度误差区域。相比之下,SelfRDB 合成的目标图像具有较低的伪影水平和更准确的解剖描述。
2. 多对比 MRI 翻译