

一、引言
图像超分辨率(ISR)是低级视觉中的一个基本问题。给定低分辨率(LR)输入,ISR旨在恢复其内容高保真度的高分辨率(HR)对应图像,其在数字摄影、高清显示、医疗等领域具有广泛的应用。图像分析、遥感等。从SRCNN开始,各种基于卷积神经网络(CNN)的方法被提出来提高ISR性能,例如残差连接(residual connections)、密集连接(dense connections)和通道注意力(channel-attention)。最近,一些基于transformer的ISR方法也出现并表现出更强大的性能。
早期,研究人员通常采用简单的降级,例如双三次下采样和高斯平滑后的下采样来合成LR-HR训练对,同时重点研究ISR网络设计。然而,现实世界中的图像退化要复杂得多,并且在这些简单的合成数据上训练的 ISR 模型很难推广到现实世界的应用。因此,近年来,人们在真实世界ISR(Real-ISR)方面做了很多工作,旨在在真实场景中的退化图像上获得感知逼真的ISR结果。一些研究人员提出通过使用长短相机焦距来收集真实世界的LR-HR图像对;然而,这是非常昂贵的,并且训练有素的模型只有在使用类似的拍摄设备时才能很好地工作。因此,研究人员建议通过设计更复杂的退化模型来合成更真实的训练数据。著名的作品包括 BSRGAN和 Real-ESRGAN。在 BSRGAN 中,随机洗牌并组合模糊、下采样和噪声降级以形成复杂的降级,而在 Real-ESRGAN 中,开发了一个具有多次重复退化操作的高阶退化模型。最近,研究人员还提出将人类指导引入训练数据生成过程。
考虑到训练数据具有更真实的退化,另一个问题是如何训练网络以实现 Real-ISR 的目标。众所周知,旨在最小化保真度误差的 L1 或 L2 损失通常会导致图像细节过度平滑。为了解决这个问题,在过去几年中,生成对抗网络(GAN)被广泛采用来训练 Real-ISR 模型。借助对抗性损失,GAN 模型可以学习寻找图像重建路径以生成更清晰的细节。尽管已经取得了巨大进步,但基于 GAN 的 Real-ISR 模型仍然存在一个关键限制,即它们倾向于产生视觉上令人不愉快的伪影。最近,随着扩散模型(DM)的快速发展,利用预训练的大规模文本到图像模型(例如稳定扩散(SD))来实现真实ISR。受益于 DM 强大的生成先验,最近的一些工作,例如StableSR展示了令人鼓舞的 Real-ISR 结果,具有精细的尺度和现实的细节。然而,DM 具有较高的随机性,这会导致 Real-ISR 输出不稳定和图像错误的细节。
在本文中,我们的目标是通过提出一种新的训练损失函数来改进基于 GAN 和 DM 的 Real-ISR 方法,减少伪影并产生更真实的细节。众所周知,自然图像在整个图像中呈现出重复的模式。这种自相似性已广泛应用于许多图像恢复算法中,例如 BM3D、NCSR、WNNM 和 NLSN ,其中图像自相似性被用作在规范化恢复图像之前。在这项工作中,作者利用图像自相似性作为强有力的惩罚来监督 Real-ISR 训练进度。所提出的图像自相似性损失(SSL)可以在大多数现有的生成式 Real-ISR 模型中充当即插即用的惩罚,指导它们更有效地利用固有的图像自相似性信息进行细节重建。具体来说,作者计算自相似图(SSG)来描述图像结构依赖性,并最小化真实值(GT)和真实ISR输出的SSG之间的距离以优化模型。为了使训练过程更加高效并关注更多图像边缘/纹理区域,作者通过以离线方式从 GT 图像生成边缘掩模,并且仅在边缘像素上构建 SSG。
本文提出的 SSL 可以很容易地采用到现成的基于 GAN 和基于 DM 的 Real-ISR 模型中,作为增强图像细节和减少令人不快的伪影的额外惩罚。图 1 显示了一个例子。可以看到 SwinIRGAN过度平滑图像纹理并生成错误的细节,而最近基于 DM 的 StableSR 恢复了更清晰的细节,但仍然无法生成一些精细的尺度结构或正确的纹理。相比之下,使用 SSL 训练的 StableSR 模型可以重建清晰的内容和更真实的纹理,并具有更好的感知质量。作者对最先进的 Real-ISR 模型进行了大量实验,验证了作者提出的 SSL 在基于 GAN 或基于 DM 的 ISR 任务中的有效性。

图1:从左到右、从上到下:SwinIRGAN、StableSR、SSL 引导的 StableSR 和ground-truth (GT) 图像生成的 Real-ISR 结果。 SwinIRGAN 产生过度平滑和错误的结果,而 StableSR 产生更多细节,但具有错误的结构和伪影。我们的 SSL 引导的 StableSR 生成更忠实的细节,同时抑制大量伪影。
二、图像自相似性损失
所提出的训练框架如图2所示。除了常用的L1、感知损失、基于GAN的方法中的对抗性损失或基于DM的方法中的高斯噪声预测MSE损失之外,作者还计算 ISR 输出和真实值 (GT)的自相似图(self-similarity graphs SSG),从而在它们之间引入自相似性损失 (SSL),以监督图像细节和结构的重建。
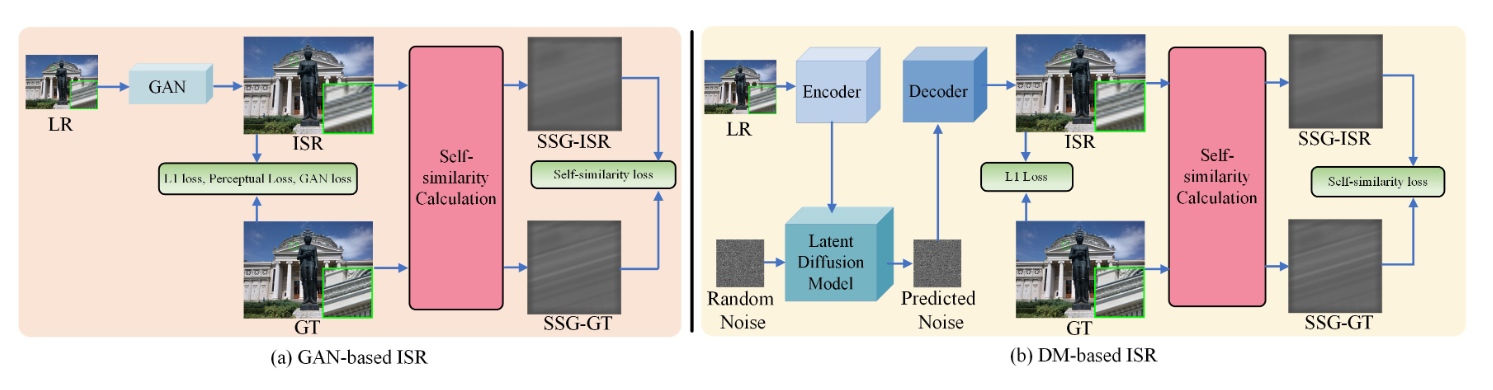
图2:使用我们提出的自相似性损失(SSL)说明(a)基于生成对抗网络(GAN)和(b)基于潜在扩散模型(DM)的 Real-ISR 的训练进度。 GAN 或 DM 网络用于将输入 LR 图像映射到 ISR 输出。我们计算ISR输出和真实图像(GT)的自相似图(SSG),并计算它们之间的SSL以监督图像细节和结构的生成。
1.图像自相似性
对于一幅自然图像,人们可以在观察到该图像许多重复的模式,称为图像自相似性。这种性质长期以来一直被用来提高图像恢复性能。实际上,Transformer 模型中的自注意力机制利用了深层特征空间中的图像自相似性。在本文中,作者采用指数欧式距离来计算自相似性。对于任意两个 pathces \(\textcolor{blue}{I_p,I_q \in R^{(2f+1) \times (2f+1) \times C}}\) 分别以图像 \(\textcolor{blue}{I \in R^{H \times W \times C}}\)中的像素\(\textcolor{blue}{u_p}\)和\(\textcolor{blue}{u_q}\)为中心,其中\(\textcolor{blue}{f}\)表示patches半径,\(\textcolor{blue}{H}\),\(\textcolor{blue}{W}\),\(\textcolor{blue}{C}\)分别是图像的高度、宽度和通道数,首先计算\(\textcolor{blue}{I_p}\)和\(\textcolor{blue}{I_q}\)之间的欧式距离平方:
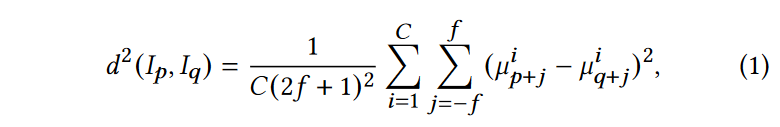
其中 \(\textcolor{blue}{μ^i_{p+j}}\) 和 \(\textcolor{blue}{μ^i_{q+j}}\) 分别表示块 \(\textcolor{blue}{I_p}\) 和 \(\textcolor{blue}{I_q}\) 中 \(\textcolor{blue}{μ^i_{p}}\) 和 \(\textcolor{blue}{μ^i_{q}}\) 周围的邻域像素。 \(\textcolor{blue}{I_p}\) 和 \(\textcolor{blue}{I_q}\)之间的相似度 \(\textcolor{blue}{S(I_p,I_q)}\) 计算如下:
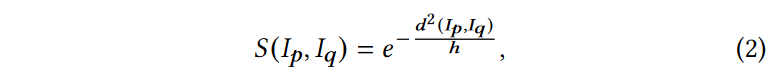
其中 \(\textcolor{blue}{h > 0}\) 是比例因子。可以看出,\(\textcolor{blue}{0≤S(I_p, I_q)≤1}\)。当欧氏距离\(\textcolor{blue}{d^2(I_p,I_q)}\)接近0时,相似度\(\textcolor{blue}{S(I_p,I_q)}\)接近1,表明两个patches高度相似。
2.Mask Generation
通过使用等式2中定义的自相似性度量。 我们可以计算一个块与整个图像中所有其他块的相似度,并构建一个自相似图(SSG)。然而,这在计算上是昂贵的,因为这样的SSG的大小将为\(\textcolor{blue}{H^2 × W^2}\)。实际上,我们不需要计算每个patches的自相似性,因为Real-ISR的挑战在于边缘和纹理区域而不是平滑区域。因此,可以生成边缘/纹理像素的掩模来指示我们应该在哪里计算 SSG。为了简单起见,首先通过将拉普拉斯算子(用 \(\textcolor{blue}{L}\) 表示)应用于 GT 图像 \(\textcolor{blue}{I_{HR} ∈ R^{H ×W ×C}}\) 来生成边缘图 \(\textcolor{blue}{E \in R^{H ×W}}\),即 \(\textcolor{blue}{E = L ⊗ I_{HR}}\)。然后,通过对 \(\textcolor{blue}{E}\) 进行阈值处理得到二值掩码 \(\textcolor{blue}{M ∈ R^{H ×W}}\):
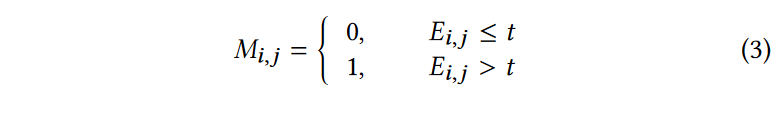
其中 \(\textcolor{blue}{t}\) 是阈值。我们根据经验将其设置为 20,以保留大部分真实边缘像素,同时滤除平滑和琐碎的图像特征。 \(\textcolor{blue}{M}\)以离线方式计算,以避免每次迭代中的重复计算。
在训练过程中,对于\(\textcolor{blue}{(i,j)}\)处的像素,其中\(\textcolor{blue}{M_{i,j} = 1}\),在GT图像和ISR输出中找到对应的RGB像素\(\textcolor{blue}{u_p}\),并计算它们的SSG进行比较。在DF2K_OST训练数据集上,边缘像素仅占图像像素总数的13%。通过使用\(\textcolor{blue}{M}\)来指导SSG的构建,不仅可以显着降低训练成本,而且可以集中精力于图像边缘和纹理。
3.自相似图计算
对于原始RGB图像 \(\textcolor{blue}{I}\) 中的边缘像素 \(\textcolor{blue}{p}\)(Mask \(\textcolor{blue}{M}\)中对应的像素为\(\textcolor{blue}{M_p = 1}\)),我们定义一个搜索区域\(\textcolor{blue}{I_{K_s} ∈ R^{K_s ×K_s ×C}}\)以及局部窗口\(\textcolor{blue}{I_p ∈ R^{K_w ×K_w ×C}}\)以它为中心,其中 \(\textcolor{blue}{K_w = 2f + 1}\),\(\textcolor{blue}{f}\) 是窗口的半径。然后对于搜索区域中的每个像素\(\textcolor{blue}{q}\),我们提取一个滑动窗口\(\textcolor{blue}{I_q ∈ R^{K_w×K_w×C}}\)并通过式(1)和等式(2)来计算其与\(\textcolor{blue}{I_p}\)的相似度,即\(\textcolor{blue}{S(Ip,Iq)}\). 然后我们将\(S(I_p,I_q)\)归一化为:
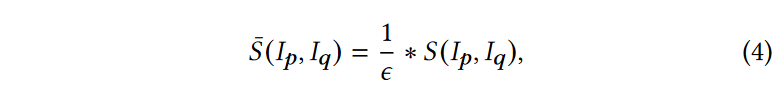
其中 \(\textcolor{blue}{ε = \sum_{q∈I_{K_s}}S(I_p, I_q)}\) 是归一化因子。
SSG的整体计算流程如图3所示。更具体地说,对于mask中的每个边缘像素,在GT图像和ISR图像中找到对应的像素,并设置以它们为中心的搜索区域。然后,设置一个局部滑动窗口,计算以中心像素为中心的patches与另一个以搜索区域像素为中心的patches之间的相似度。\(\textcolor{blue}{\bar{S}(I_p, I_q)}\) 的所有值构建了图像 \(\textcolor{blue}{I}\) 的 SSG,它描述了图像固有的结构相似性分布。在实践中,我们可以使用步幅 \(\textcolor{blue}{s}\) 对 \(\textcolor{blue}{I_q}\) 进行采样,以进一步降低计算成本(我们在实现中设置 s = 3)。
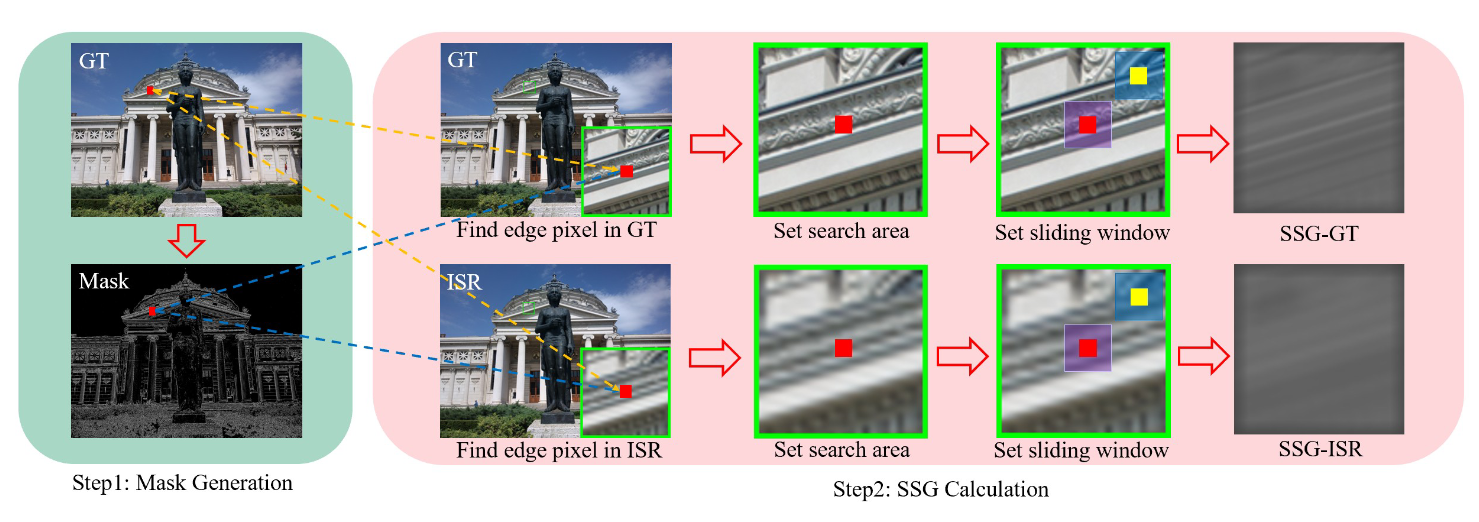
图3:自相似图(SSG)计算过程图示。首先通过在 GT 图像上应用拉普拉斯算子来生成一个mask来指示图像边缘区域。在训练期间,对于mask中的每个边缘像素,我们在GT图像和ISR图像中找到对应的像素,并设置以它们为中心的搜索区域。利用局部滑动窗口计算搜索区域内各像素与中心像素的相似度,从而可以分别计算GT图像和ISR图像的SSG,进而计算SSL。红色像素表示边缘像素,蓝色块表示滑动窗口。
4.自相似性损失
分别用\(\textcolor{blue}{\bar{S}_{HR}}\) 和 \(\textcolor{blue}{\bar{S}_{ISR}}\) 表示 GT 图像的 SSG 和 ISR 输出。我们可以使用它们的距离作为损失来监督网络训练。这里作者使用 KL 散度和 L1 距离来构建 SSL:
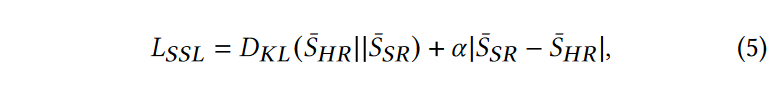
基于 GAN 的模型中的 SSL。要将SSL应用到现成的基于GAN的Real-ISR方法中,只需将上述\(\textcolor{blue}{L_{SSL}}\)损失添加到其原始损失函数\(\textcolor{blue}{L_{original}}\)(例如像素级\(\textcolor{blue}{L_1}\)损失、感知损失和GAN损失)中,然后重新训练模型:
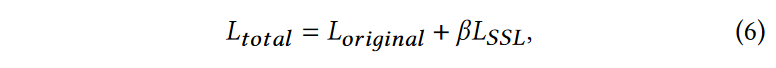
其中\(\textcolor{blue}{β}\)是平衡参数。
基于 DM 的模型中的 SSL。对于那些基于潜在 DM 的 Real-ISR 方法,StableSR 和 ResShift,应用 \(\textcolor{blue}{L_{original}}\) 来预测潜在空间中所需的噪声。由于SSL是在图像空间中计算的,因此我们需要将预测的噪声通过VAE解码器传递以输出ISR图像,如图2(b)所示,然后将SSL应用于重建图像。我们还采用逐像素 L1 损失来实现更稳定的训练。总损失为:
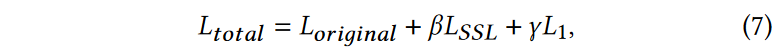
其中\(\textcolor{blue}{β}\)、\(\textcolor{blue}{γ}\)是平衡参数。 \(\textcolor{blue}{L_{SSL}}\)和\(\textcolor{blue}{L_1}\)将反向传播它们的梯度以更新去噪UNet的参数和DM中的控制部分
三、实验结果
1.基于GAN模型的实验
比较方法。我们提出的 SSL 可以直接应用于现有的基于 GAN 的 Real-ISR 模型,作为即插即用模块,通过简单的双三次降级或复杂的混合降级来提高其性能。对于双三次降解,我们将 SSL 嵌入到 ESRGAN 、RankSRGAN、SPSR、BebyGAN和 LDL中。对于复杂的混合物降解,我们将 SSL 嵌入到 Real-ESRGAN 和 BSRGAN 中。上述大多数模型都采用 CNN 主干(例如 RRDB 或 SRResNet )作为生成器。在本文中,作者还采用transformer backbones,即 SwinIR 和 ELAN,作为生成器,产生 SwinIRGAN 和 ELANGAN 模型。对于上述每个 Real-ISR 模型(例如 ESRGAN),我们用“*-SSL”表示(例如 ESRGAN-SSL)
训练细节。对于每种评估的 Real-ISR 方法,我们使用相同的patches大小和训练数据集(即 DIV2K、DF2K和 DF2K-OST)训练其 SSL 引导对应方法和原来的方法一样。在复杂退化的实验中,由于RealESRGAN和BSRGAN中的原始退化设置太重,我们遵循HGGT中的Real-ESRGAN和BSRGAN设置(退化水平较弱)来生成训练数据。采用 Adam 优化器。初始学习率设置为 1e-4,对于 CNN 主干网,在 200K 次迭代后减半;对于 Transformer 主干网,在 200K、250K、275K、287.5K 次迭代后,该学习率减半。计算SSG时,搜索区域\(I_{Ks}\)设置为25,滑动窗口\(I_{Kw}\)设置为9,缩放因子\(h\)设置为0.004。 \(β\) 设置为 1000。所有实验均在 NVIDIA RTX 3090 GPU 上进行。所有 SSL 引导模型都是从训练有素的面向保真度的版本(例如 RRDB、SwinIR或 ELAN (仅使用 L1 损失进行训练而没有鉴别器)进行微调,以获得更好的初始化
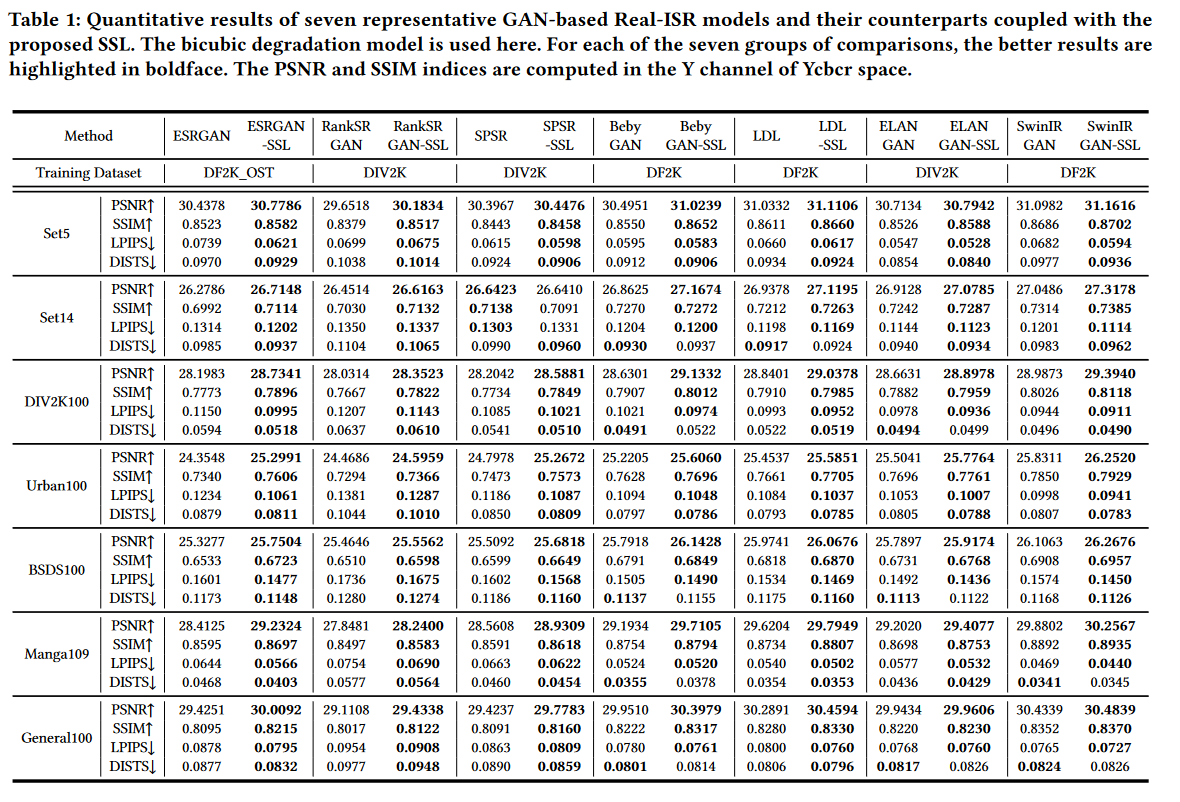
评估数据集和指标。我们采用广泛使用的测试基准,包括 Set5、Set14、DIV2K100、Urban100、BSDS100、Manga109、General100 来评估竞争方法。考虑到使用[65, 84]中的复杂混合退化模型时合成LR图像存在一定的随机性,对于每个测试图像,我们使用随机采样的退化因子合成一组30张LR图像,并报告公平可靠评估的平均指标。我们计算 Y 通道中的 PSNR 和 SSIM,以进行保真度测量。对于感知质量,LPIPS 和DISTS 用于定量评估。
双三次降解的结果。表 1 显示了使用双三次降解时不同 Real-ISR 模型的定量结果。可以看出,在所有 7 个测试数据集上,无论使用 CNN 还是 Transformer 主干,我们的 SSL 引导模型在大多数保真度(PSNR、SSIM)和感知(LPIPS、DISTS)测量方面都超过了原始模型。这表明图像SSG可以表征图像的固有结构,而我们的SSL可以在Real-ISR模型训练过程中提供有效的监督,迫使模型以更好的保真度幻觉出更正确的内容,并抑制视觉伪影以实现更好的感知质量。值得一提的是,我们的SSL不会在推理过程中引入任何额外的成本。
定性结果。图 4 提供了在双三次退化情况下主要 Real-ISR 模型与其 SSL 引导版本之间的视觉比较。可以清楚地看到 SSL 引导模型可以生成更清晰的纹理(第一列),或更丰富的细节(第二列),并纠正原始生成的扭曲纹理(第三/第四/第五/第六/第七列)模型。这些观察结果与表 1 中的结果相呼应,再次证明 SSL 可以幻觉正确的细节并抑制伪影。

图4:基于最先进的 GAN 的 Real-ISR 模型与使用我们的 SSL 训练的对应模型的视觉比较。这里使用双三次退化模型。从顶行到底行是双三次插值的结果、原始 Real-ISR 模型、使用我们的 SSL 训练的 Real-ISR 模型以及 GT 图像。
2.基于DM模型的实验
比较方法。我们将 SSL 嵌入到三个代表性的基于 DM 的模型中,包括 StableSR、ResShift 和 DiffIR。对于上述每个 Real-ISR 模型(例如,StableSR),我们用“*-SSL”(StableSR-SSL)表示。
训练细节。对于每个评估的基于 DM 的 Real-ISR 方法,我们采用相同的训练数据集(包括 DF2KOST、DIV8K、FFHQ),并应用与所使用的相同的退化管道在稳定SR中。 SSL 引导版本中的训练补丁大小和迭代设置为与原始方法相同。使用 Adam 优化器。学习率固定为5e-5。计算SSG时,搜索区域\(\textcolor{blue}{I_{K_s}}\)设置为25,滑动窗口\(\textcolor{blue}{I_{K_w}}\)设置为9,缩放因子\(\textcolor{blue}{h}\)设置为0.004。对于SSL引导的StableSR和DiffIR,方程7中的权重\(\textcolor{blue}{β}\)和\(\textcolor{blue}{γ}\) 分别设置为 1 和 0.1。对于 SSL 引导的 DiffIR,由于原始模型已经利用了逐像素 L1 损失,因此我们将损失函数类型实现为等式6、\(\textcolor{blue}{β}\)设置为1000。所有实验均在NVIDIA V100 GPU上进行。我们更新了预训练 DM 中 UNet 的所有参数以及 SSL 引导对应部分的控制部分。
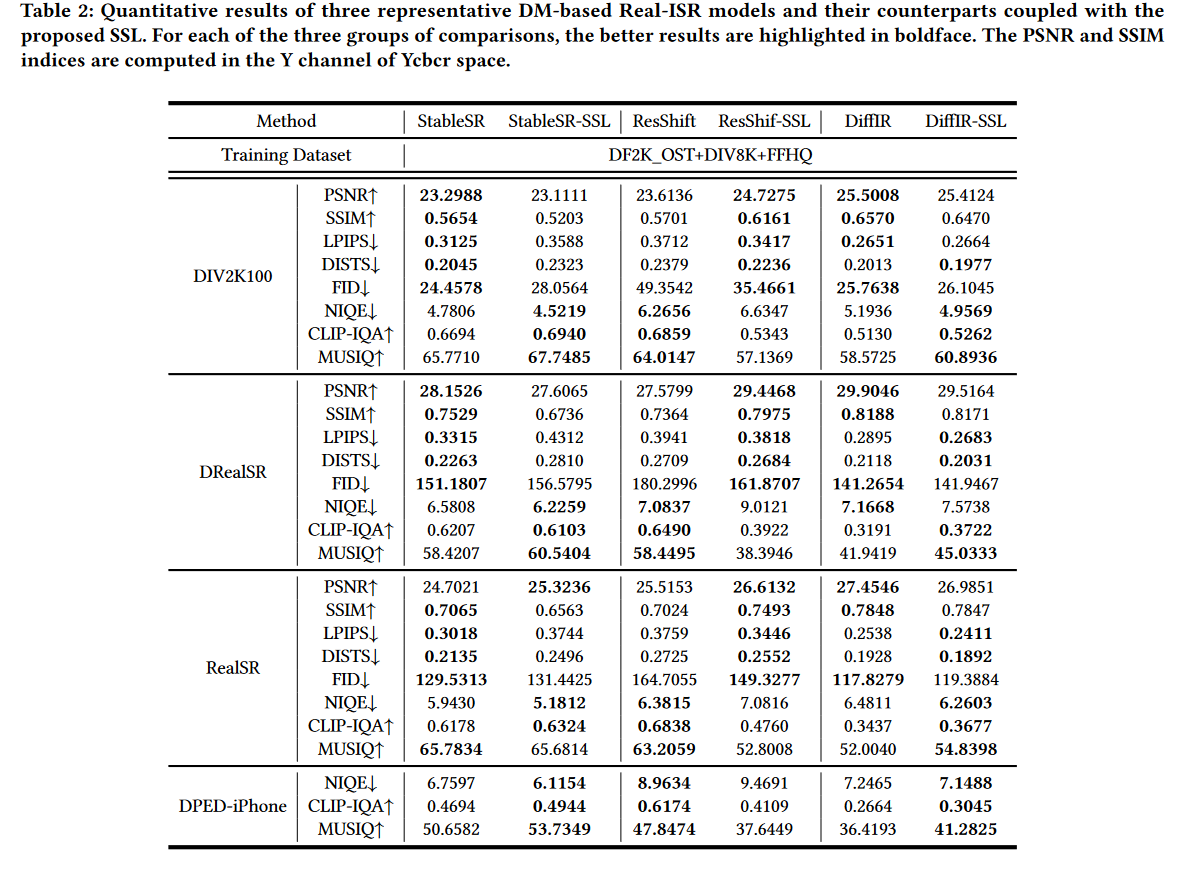
评估数据集和指标。我们利用来自StableSR的测试图像,包括3000个合成的DIV2K100低质量测试图像(每个GT图像有一组由具有复杂退化因素的DIV2K100 数据集生成的30个LR图像),RealSR ( 100张真实世界低质量图像及其由相机获取的相应GT),DRealSR (93张真实世界低质量图像及其由相机捕获的相应GT),DPED-iphone(113张真实世界不带 GT 的 iPhone 拍摄的低质量图像)。我们计算全参考图像质量指标,包括 PSNR、SSIM、LPIPS 和 DISTS,以及无参考图像质量指标,包括 NIQE、CLIP-IQA 和 MUSIQ 。还计算了统计距离度量 FID 。
定量结果。表 2 显示了原始基于 DM 的 Real-ISR 方法及其 SSL 引导版本的数值结果。可以看到,StableSR-SSL 获得了更好的无参考指标(NIQE/CLIP-IQA/MUSIQ),同时获得了较差的全参考指标(PSNR/SSIM/LPIPS/DISTS)。 ResShift-SSL 获得更好的全参考指标(PSNR/SSIM/LPIPS/DISTS),但更差的无参考指标(NIQE/CLIP-IQA/MUSIQ)。 DiffIR-SSL 获得更好的感知相关指标(LPIPS/DISTS/NIQE/CLIP-IQA/MUSIQ)。虽然不同的SSL引导模型获得不同的性能,但仍然是合理的,原因如下:(1)。 StableSR-SSL 利用预训练的稳定扩散模型,该模型在 LAION5B 上进行训练,LAION5B 是一个包含大量文本到图像对的多模态数据集。与用于 SR 任务的一般训练数据集(例如 DF2K和 DIV8K)相比,这会导致明显的数据分布差异。因此,在推理阶段,StableSR-SSL 生成的结果与测试集中的 GT(例如 DIV2K100)表现出显着差异。因此,所有全参考指标都会失败,而无参考指标却得到更好的结果,这也表明感知质量更好。 (2) ResShift-SSL 获得更好的 FR-IQA (PSNR/SSIM/LPIPS/DISTS/FID)结果,这表明SSL可以帮助ResShift以更高的保真度重建纹理。至于较差的NR-IQA指标,这主要是因为现有的NR-IQA指标,包括NIQE、CLIP-IQA和MUSIQ,偏向于具有更多高频细节的图像,即使这些细节是错误的。从补充图 6 中可以看出,ResShift 产生了许多错误的细节(例如,在第 1 列的窗口上),而 ResShift-SSL 成功地删除了这些伪影。我们的用户研究还表明,73.07% 的观察者选择了 ResShift-SSL 的结果。然而,NR-IQA 指标更喜欢 ResShift 的结果,因为它们还不够准确,无法代表人类的感知。 (3)。 DiffIR-SSL 不仅从头开始训练潜在扩散模型,而且还利用了鉴别器。由于鉴别器引入的影响,PSNR/SSIM变得更差,但获得了更好的感知相关指标(LPIPS/DISTS/NIQE/CLIP-IQA/MUSIQ)。
定性结果。图 5 显示了可视化结果。可以看到,与原始的基于DM的Real-ISR方法相比,它们的SSL引导版本在恢复图像结构和细节方面表现明显更好,展示了SSL强大的结构正则化能力。例如,StableSR 在 T 恤中生成错误图案(第 1 列),在周柱上生成不完整的细节(第 2 列),而 SSL 引导的 StableSR 会恢复正确的 T 恤图案,并在周柱上产生更完整的结构。对于 ResShift,它要么过度平滑细节(第 3 列),要么生成错误的纹理(第 4 列),而 SSL 可以帮助解决这个问题。 DiffIR 也得到了类似的观察结果。所有这些结果都验证了 SSL 在鼓励 Real-ISR 模型生成更精细细节方面的有效性。

图5:对最先进的基于 DM 的 Real-ISR 模型与使用我们的 SSL 训练的模型进行视觉比较。从顶行到底行是双三次插值的结果、原始 Real-ISR 模型、使用我们的 SSL 训练的 Real-ISR 模型以及 GT 图像。
四、总结
生成图像超分辨率方法,包括基于 GAN 和基于 DM 的方法,很容易产生视觉伪影。在这项工作中,我们提出了一种图像自相似性先验的新颖用途,用于改进生成的现实世界图像超分辨率结果。具体来说,我们显式计算图像的自相似图(SSG),并将真实图像的SSG图与Real-ISR输出之间的差异作为自相似损失(SSL)来监督网络训练。 SSL 可以轻松嵌入到现成的 Real-ISR 模型中,包括基于 GAN 和基于 DM 的模型,作为即插即用的惩罚,指导模型更稳定地生成真实细节并抑制错误生成和视觉文物。我们对基准数据集进行的广泛实验验证了所提出的 SSL 在生成 Real-ISR 任务中的通用性和有效性。