
《Mask-aware tranformer with structure invariant loss for CT translation》
一、摘要
多期增强CT(Multi-phase Enhanced Computed Tomography,MPECT)是由CT平扫转换而来的,可以帮助医生发现肝脏病变,防止患者在MPECT检查中出现过敏反应。现有的CT转换方法直接学习从平扫CT到MPECT的端到端映射,忽略了关键的临床领域知识。在临床诊断中,临床医生从MPECT图像中减去平扫CT作为减影图像,以突出对比度增强区域并进一步促进肝脏疾病的诊断,旨在利用该领域的知识进行CT自动转换。为此,本文提出了一种具有结构不变损失的掩模感知Transformer(MAFormer)用于CT变换,这是首次利用该领域的知识进行CT变换的尝试。具体地,所提出的MAFormer引入掩模估计器来从平扫CT图像预测减影图像。为了将减影图像集成到网络中,MAFormer设计了一个基于掩模感知Transformer器的归一化(MATNorm)作为归一化层,以突出对比度增强区域并捕获这些区域之间的长程依赖性。此外,为了保持CT切片的生物结构,设计了一种结构不变损失来提取结构信息,并最小化平扫和合成CT图像之间的结构相似性,以保证结构不变。
二、介绍
在过去的几十年中,由于不同的危险因素,肝癌的死亡率增长最快。为了观察肝脏病变,医生利用平扫计算机断层扫描(CT)来区分良性肿瘤和恶性肿瘤。与临床医生可能忽略的肝脏病变的不明确的平扫CT扫描相比,包括平扫(即,在注射造影剂之前)、动脉期、门静脉期和延迟期,可以表征肝损伤的生物学性质以提供更好的治疗方案。如图1(a)所示,相同区域在连续的4幅CT图像之间对比度不同,可以帮助医生动态观察病变。然而,MPECT检查将造影剂注入患者体内,可能引起过敏反应。为了避免患者出现过敏反应,将CT平片转换为MPECT图像是一种潜在的解决方案,可以在不进行检查的情况下获得MPECT。
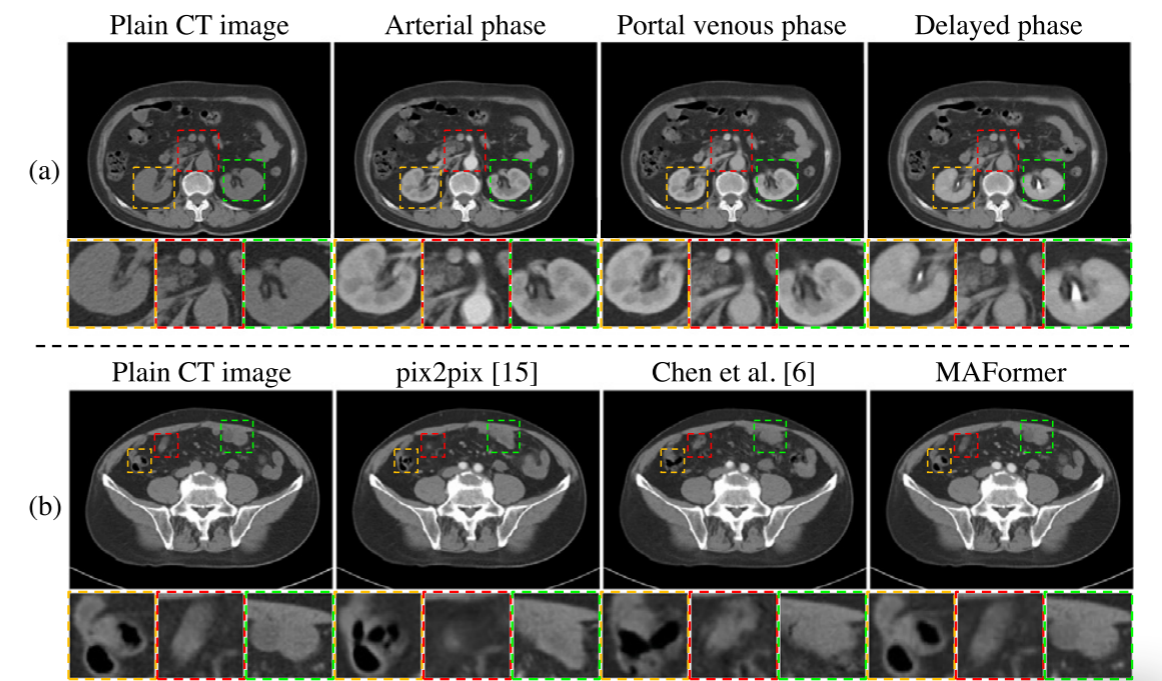
图1.真实的和合成MPECT图像的示例。(a)MPECT图像包括四个连续的CT图像,其中放大的斑块显示对比增强区域。(b)不同方法生成的动脉期与CT平扫图像结构的比较。放大的显示部分由现有方法合成的损坏的结构。
自动CT翻译已经通过各种基于深度学习的方法进行了研究。就网络体系结构而言,这些方法可以被分类为两组,包括基于编码器-解码器的和生成对抗网(GANs)的方法。前者采用基于编码器-解码器的网络(例如,U-Net )作为主干,像素级损失用于监督。后者包括用于合成真实CT图像的生成器和用于区分真实的CT图像与合成CT图像的判别器。
即使先前的方法已经深入挖掘了CT平扫图像与目标图像之间的相关性,但这些方法的CT翻译性能仍然不理想。现有技术通过直接学习从平扫CT图像到目标CT图像的映射来实现CT翻译。在真实的的临床实践中,医生使用时间减影技术来检测腹部CT图像上的小肝细胞癌(HCC)。他们从增强CT图像中减去平扫CT图像作为减影图像,以突出增强区域。然而,在现有方法中还没有将该领域知识用于CT翻译。在此,作者尝试利用这些领域知识来估计减影图像,并强调平扫和增强CT图像之间的关系,以便于CT翻译。为了进一步将减影图像整合到平扫CT图像中,直观的解决方案是采用现有技术,以通过自适应地归一化输入特征来将减影图像并入CT翻移网络。然而,这些方法忽略了对比区域之间的相关性,并且可能生成不准确的CT图像。例如,MPECT图像的某些区域应同时进行对比增强(例如,动脉期的肾脏和主动脉)。因此,减影图像与CT平扫图像融合的方法应强调增强区域在框架内的关系。
此外,在MPECT检查过程中,CT扫描的软组织被增强,而骨骼和器官的形状保持不变。因此,CT平扫和增强图像应保持病变区域生物学结构的一致性,以免影响临床对病变区域的诊断。在图1(B)中,作者可视化了由现有方法,如放大的块所示,现有方法破坏了合成CT图像的结构。近年来,一些工作采用了循环一致性损失和条件性GAN或引入空间相关图缩小平扫和目标CT图像之间的结构差异。然而,空间相关映射仅表示输入图像和合成图像之间的共享信息,而不是它们的内在结构(例如,骨头)。因此,为了保持合成图像的CT结构,CT翻译方法需要提取固有结构并提供精确的结构监控。
为了解决这些问题,作者介绍了一个掩模感知的Transformer(MAFormer)与CT翻译的结构不变损失。所提出的方法的目标是利用减影图像,以方便CT翻译。首先设计一个掩模估计器来预测掩模图像作为每个平片CT图像的减影图像。利用估计的掩模图像,所提出的MAFormer应用基于Mask-Aware Transformer的归一化(MATNorm)作为归一化层来突出对比度增强的区域并利用它们的相关性。为了进一步捕捉这些区域之间的长距离依赖关系,MATNorm利用Transformer作为主干来促进远距离对比区域之间的交互。为了保持CT结构,提出了一种结构不变损失(SIL)方法,以减少提取的结构感知特征的冗余纹理,并最大限度地减少普通CT图像和合成CT图像之间的结构感知特征差异。通过这种方式,所提出的MAFormer可以集成领域知识,以促进CT翻译,并生成真实合理的CT图像,用于肝癌诊断。
本文的贡献归纳如下:
1️⃣作者提出了一个掩模感知的Transformer(MAFormer)的CT翻译,其中包括一个掩模估计器生成的减影图像的生成器,以进一步促进CT从普通CT到MPECT图像的翻译。据我们所知,这是第一个工作,开发减影图像的CT翻译,这是非常重要的意义,在肝脏病变的诊断在真实的临床实践。
2️⃣为了将掩模图像整合到CT平片图像特征中,作者设计了一个基于掩模感知Transformer的归一化层(MATNorm),该层试图通过研究对比度增强区域的长程依赖关系并将此信息注入到CT平片图像特征中来突出对比度增强区域。
3️⃣为了在CT翻译过程中保持普通CT图像和合成CT图像之间的结构不变,提出了一种结构不变损失,以减少这些CT图像提取的结构信息之间的差异。
三、相关工作
1.CT 翻译
当前的CT平移方法可以分为两组,即,基于encoder-decoder的方法和基于GAN的方法。前一种方法采用基于编码器-解码器的网络作为骨干来实现CT翻译。例如应用了U-NET的框架,采用两个损失函数,包括合成图像和真实的CT图像之间的平均绝对误差(MAE)和结构不相似性(DSSIM)。至于后一种方法,它们在其框架中采用基于GAN的方法,例如,pix2pix和CycleGAN。这些方法包括将输入图像转换为目标图像的生成器和将真实的与合成图像区分开的判别器。Upadhyay等人(2021)设计了一种基于渐进GAN的框架,以应用随机不确定性作为指导,从磁共振成像(MRI)或正电子发射断层扫描(PET)图像合成CT图像。受CycleGAN的启发,Armanious等人(2019)引入了Cycle-MedGAN,以利用特征级的循环一致性损失来最大限度地减少真实的和合成CT图像之间的纹理和感知距离。具体地说,减影图像可以在不同的相位中突出MPECT图像的对比度增强区域,并且还可以用于检测癌细胞。因此,作者采用减影图像来开发CT翻译的领域知识,以通过定制的模块来简化翻译过程。
2.CT 翻译的结构保留
在CT翻译期间,合成CT图像的生物结构与普通CT图像相比应当保持不变。为了保持生物结构,我们需要提取结构信息,这不仅包括两个CT图像之间的最大互信息(例如骨骼),而且还排除冗余信息(例如纹理)。为了最大化互信息,自监督学习(SSL)被广泛用于学习没有任何注释的代表性特征,其可以进一步用于下游任务。一些对比SSL方法学习通过潜在空间中的对比损失来最大化示例和增强示例之间的一致性。为了增加输入图像和合成图像之间的互信息,在一些方法中采用对比SSL的图像翻译任务。CUT是第一个将对比SSL应用于图像翻译的工作,它利用逐块对比损失来最大化输入和输出图像的对应块之间的互信息。基于这项工作,Zheng等人(2021)引入了F-LSeSim来计算图像内的对比度损失,并系统地学习没有外观属性的空间相关地图。受F-LSeSim的启发,Ang等人(2022)采用空间相关图作为结构图,并在CT翻译期间对合成CT图像施加结构监督。然而,空间相关映射只包括输入和合成图像之间的共享信息,而不是内在结构。它不仅应该包含它们的共享信息(例如骨骼),还应该排除冗余信息(例如纹理)。因此,作者提出了一个结构不变的损失,提取内在结构与较少的冗余纹理,并保持不变的合成CT图像。
四、方法
1.总体网络结构概述
如图2所示,作者提出了一种用于CT翻译的具有结构不变损失的Mask-Aware Transformer(MAFormer),其包括Mask Estimator \(\textcolor{blue}{R}\)、生成器 \(\textcolor{blue}{G}\) 和 判别器 \(\textcolor{blue}{D}\)。在给定平扫CT图像 \(\textcolor{blue}{x}\) 的情况下,Mask Estimator可以通过预测对应的Mask image \(\textcolor{blue}{M}\) 来指示目标CT图像的对比度增强区域。然后,生成器 \(\textcolor{blue}{G}\) 通过多个mask-aware block(MAB)将平扫CT图像和Mask image的特征进行融合,并获得合成CT图像\(\textcolor{blue}{y^\prime= G(x, R(x))}\),其中MAB包含两个卷积层和基于Mask-Aware Transformer的归一化(MATNorm)层。最后,所提出的结构不变损失,对抗性损失和重建损失联合使用,以优化MAFormer。
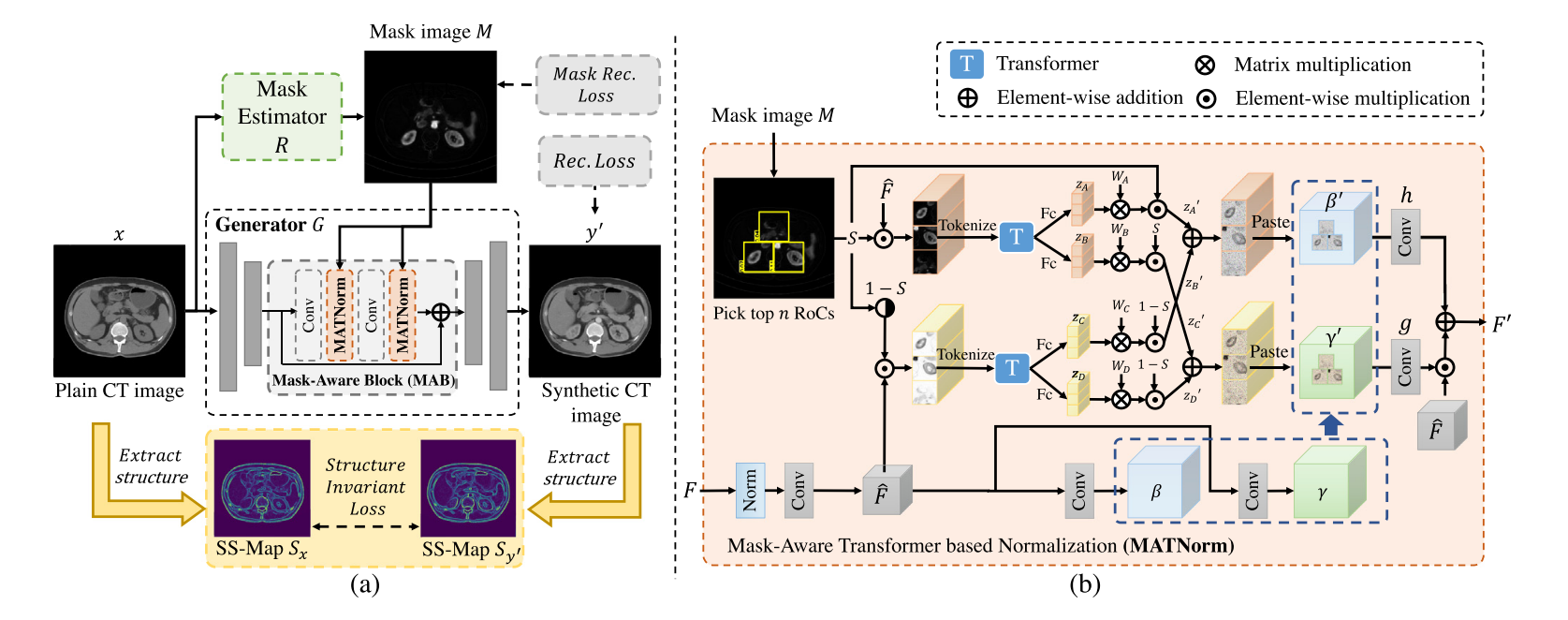
图2.(a)介绍了基于结构不变损失的Mask-Aware Transformer(MAFormer),包括用于Mask image预测的Mask Estimator、用于Mask image融合的基于Mask-Aware Transformer的归一化(MATNorm)和用于保持CT结构的结构不变损失;(B)提出的MATNorm,其中 \(T\) 表示 transformer。
2.Mask-Aware Transformer based network
2.1 Mask Estimator
大多数CT合成方法倾向于直接学习从平扫CT图像到目标CT图像的端到端映射,而不考虑CT翻译的领域知识,尤其是减影图像(subtraction image)。事实上,减影图像(subtraction image)可进一步用于促进肝病诊断。但是,减影图像尚未用于CT翻译。因此,为了采用减影图像来促进CT合成,提出了一种Mask Estimator来生成减影图像而不需要目标CT图像。
Mask Estimator \(R\)是一个编码器-解码器网络,其目的是Mask image作为每个平扫CT图像 \(\textcolor{blue}{x}\) 的减影图像。Mask image \(\textcolor{blue}{M}\) 被定义为\(\textcolor{blue}{M=R(x)}\)。为了监督Mask image的合成,计算生成的Mask image \(\textcolor{blue}{M}\) 和真实Mask image \(\textcolor{blue}{M_{GT}}\) 之间的掩模重建损失,以Mask Estimator的可靠性,\(\textcolor{blue}{L_M =||M-M_{GT}||^1}\),其中\(\textcolor{blue}{M_{GT}}\)是通过从目标CT图像中减去平扫CT获得的。通过采用Mask Estimator,可以获得具有潜在的对比度增强区域的平扫CT图像,并给予一个提示用于目标CT图像合成。
2.2 Mask-Aware transformer based normalization (MATNorm)
为了将生成的Mask image整合到平扫CT图像,现有方法可以使用自适应参数来归一化平扫CT图像特征。然而,这些方法不能探索对CT成像有用的对比区域之间的相关性。因此,作者引入了基于Mask-Aware Transformer的归一化(MATNorm)来选择Mask image 图像中的对比度增强区域,并利用这些区域之间的长程依赖性来归一化普通CT图像特征,并进一步促进CT翻译,如图2(B)所示。
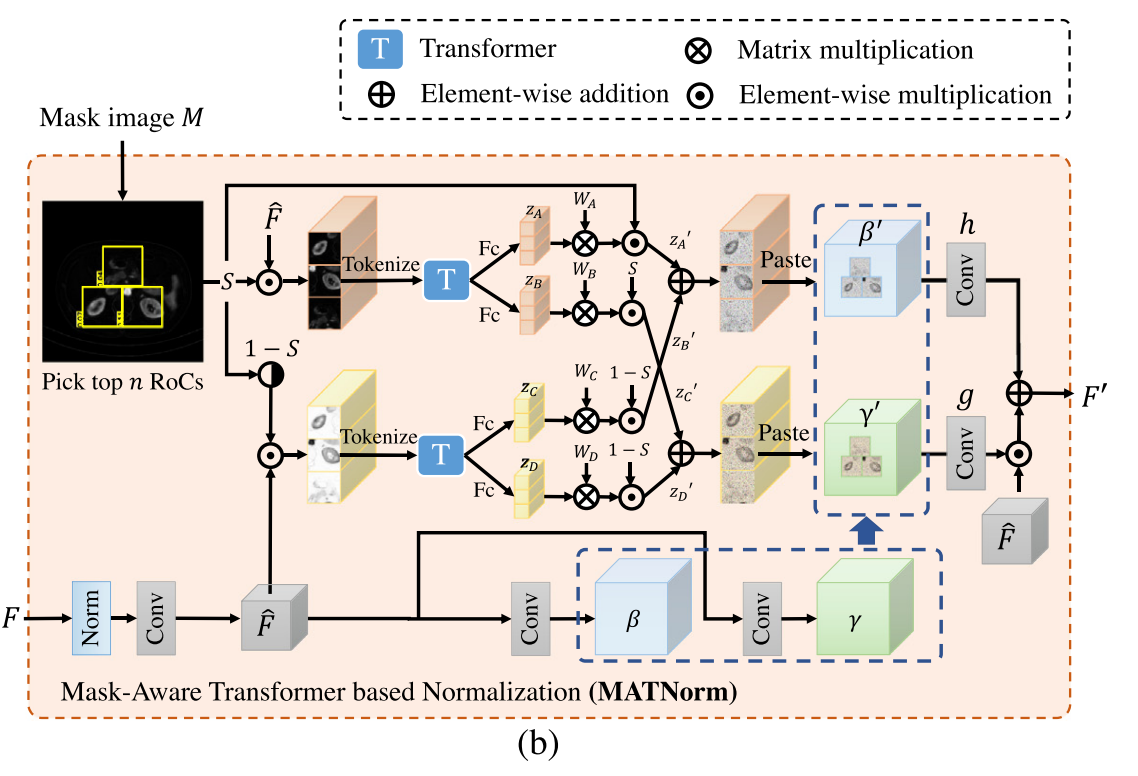
为了突出对比度增强的区域,作者首先在生成的Mask image \(\textcolor{blue}{M \in R^{H \times W}}\)上执行具有窗口大小(\(\textcolor{blue}{k \times k}\))和窗口步幅(\(\textcolor{blue}{s}\))的滑动窗口,以获得多个对比度区域(RoC),其中RoC表示对比度区域。作者将RoC的像素值相加作为置信度得分,并挑选出最高的RoCs \(\textcolor{blue}{S \in R^{C \times k \times}}\)。对于RoCs \(\textcolor{blue}{S}\),作者将其反转以获得其背景 \(\textcolor{blue}{1−S}\),其中表示1的矩阵。然后,通过分别执行 \(\textcolor{blue}{S}\) 和 \(\textcolor{blue}{\hat{F}}\) 的逐元素乘法以及\(\textcolor{blue}{1-S}\)和 \(\textcolor{blue}{\hat{F}}\) 的逐元素乘法来计算前景和背景RoC的平扫CT图像特征,其中\(\textcolor{blue}{\hat{F}}\)是由卷积层 \(\textcolor{blue}{f}\) 处理的归一化特征。与此同时,作者通过将\(\textcolor{blue}{\hat{F}}\)馈送到两个单独的卷积层中来获得ROC之外的特征的缩放和移位参数 \(\textcolor{blue}{\gamma \in R^{C \times H \times W}}\) 和\(\textcolor{blue}{\beta \in R^{C \times H \times W}}\)
为了利用不同RoC之间的长程依赖关系,作者使用Transformer来加强RoC的前景或背景特征之间的交互。两个单独的transformer分别将前景 \(\textcolor{blue}{tok_f ∈ R^{n \times C}}\) 和背景RoC tokens \(\textcolor{blue}{tok_b ∈ R^{n \times C}}\)作为输入,对于前景tokens,两个独立的全连接层预测嵌入 \(\textcolor{blue}{z_A ∈ R^{n \times C}}\)和 \(\textcolor{blue}{z_A ∈ R^{n \times C}}\)去移动和缩放 \(\textcolor{blue}{\hat{F}}\)。为了将嵌入\(\textcolor{blue}{z_A}\),\(\textcolor{blue}{z_B}\)转换为区块级特征,作者首先计算嵌入和可学习参数之间的矩阵乘法,然后通过按元素乘以RoCs \(\textcolor{blue}{S}\) 分别获得前景相关的嵌入\(\textcolor{blue}{z^{\prime}_A}\),\(\textcolor{blue}{z^{\prime}_B}\)。
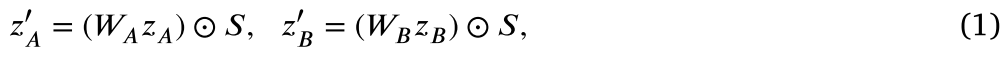
其中,\(\textcolor{blue}{W_A ∈ R^{K^2 \times n}} \)和 $ $ 表示可学习的参数。与前景部分类似,用于缩放背景特征的嵌入 \(\textcolor{blue}{z^{\prime}_C}\) 和 \(\textcolor{blue}{z^{\prime}_D}\) 通过以下公式进行计算:
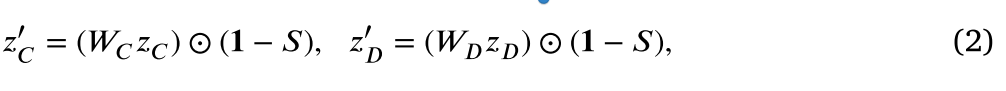
其中 \(\textcolor{blue}{W_C}\) 和 \(\textcolor{blue}{W_D}\) 是可学习的参数。通过与位移相关的 \(\textcolor{blue}{z^′_A}\)、\(\textcolor{blue}{z^′_C}\) 和与缩放相关的 \(\textcolor{blue}{z^′_B}\) 、\(\textcolor{blue}{z^′_D}\) 嵌入,我们将 RoC 的特征替换为分别为 \(\textcolor{blue}{z^′_A ⊕ z^′_C}\),\(\textcolor{blue}{z^′_B ⊕ z^′_D}\) 。
最后,为了缩放和平移 \(\textcolor{blue}{\hat{F}}\),我们将 \(\textcolor{blue}{\gamma^{\prime}}\) 和 \(\textcolor{blue}{\beta^{\prime}}\) 分别输入到两个不同的卷积层 \(\textcolor{blue}{g}\) 和 \(\textcolor{blue}{h}\) 中,并计算最终的输出特征 \(\textcolor{blue}{F^{\prime} = g(\gamma^{\prime}) ⊙ ̂ F ⊕ h(\beta^{\prime})}\) ,其中 \(\textcolor{blue}{⊙}\) 表示按元素乘法,\(\textcolor{blue}{⊕}\) 表示按元素加法。通过MATNorm,可以强调对比度增强区域,并可以开发这些区域之间的相关性,这进一步促进和促进CT翻译。
2.3 结构不变损失(SIL)
事实上,CT 翻译应该保留合成 CT 图像中不变的生物结构。然而,现有方法无法保留 CT 结构,并可能在 CT 翻译的过程中改变它。为了解决这个问题,作者引入了结构不变损失来提取内在结构信息并使其在合成 CT 图像中保持不变。
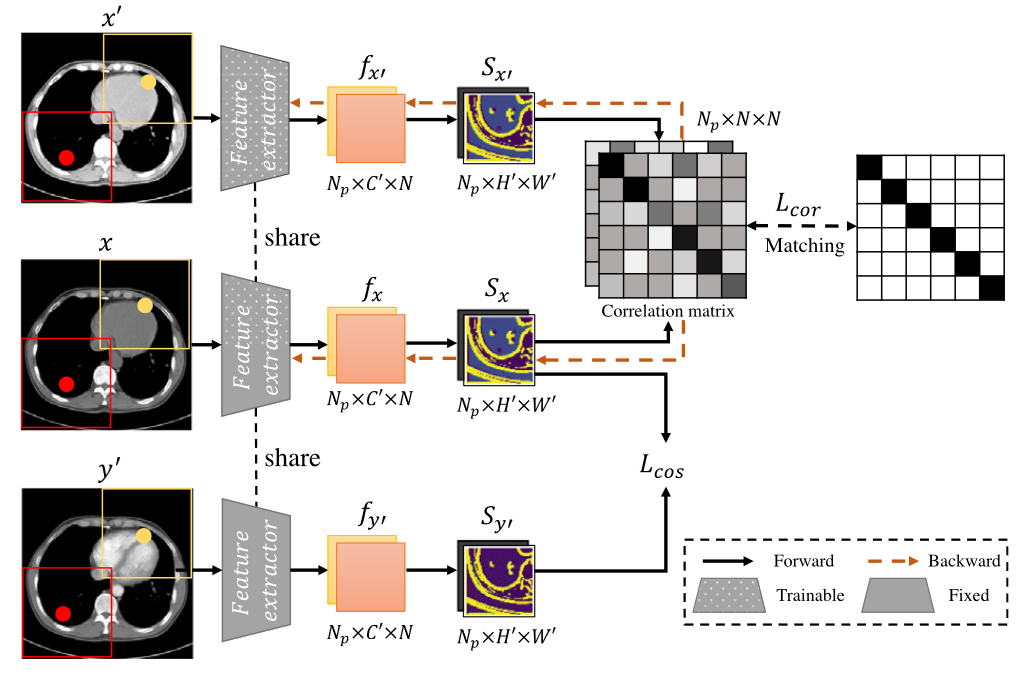
图3.结构不变损失概述。其目的是通过将相关矩阵与单位矩阵相匹配来提取结构感知特征,并缩小普通 CT 图像和合成 CT 图像之间的结构感知特征之间的差异。
如图3所示,作者将平扫CT图像及其增强图像视为正确对,以提取它们共享的结构信息,并将合成CT图像视为query image,以缩小其与平扫CT图像相比的结构差异。
具体来说,给定一张平扫 CT 图像 \(\textcolor{blue}{x}\)、一张增强图像 \(\textcolor{blue}{x^{\prime}}\) 和合成 CT 图像 \(\textcolor{blue}{y'}\),我们在 \(\textcolor{blue}{x}\)、\(\textcolor{blue}{x^{\prime}}\) 和 \(\textcolor{blue}{y^{\prime}}\) 上随机裁剪尺寸为 \(\textcolor{blue}{H_p × W_p}\) 的 \(\textcolor{blue}{N_p}\) 个区域块。然后,将这些区域块输入到可训练特征提取器中,以获得相应的特征 \(\textcolor{blue}{f_x ∈ R^{N_p×C^′×N}}\) 、 \(\textcolor{blue}{f_{x^′} ∈ R^{N_p×C^′×N}}\) 和 \(\textcolor{blue}{f_{y^′} ∈ R^{N_p×C^′×N} (N = H^′× W^{\prime})}\),其中 \(\textcolor{blue}{C^{\prime}}\)、\(\textcolor{blue}{H^{\prime}}\) 和 \(\textcolor{blue}{W^{\prime}}\) 表示提取的特征图的通道数、高度和宽度。利用每个区域块提取的特征,计算它们的自相似图以将内在结构表示为:

其中 \(\textcolor{blue}{S_x ∈ R^{N_p×N}}\) 表示平扫 CT 图像中 query 点 \(\textcolor{blue}{f_{x_i} ∈ R^{N_p×C^′×1}}\) 与其他点 \(\textcolor{blue}{f_x}\) 之间的特征相关性。以类似的方式计算增强 CT 图像 \(\textcolor{blue}{S_x^{\prime} ∈ R^{N_p×N}}\) 和合成 CT 图像 \(\textcolor{blue}{S_y^{\prime} ∈ R^{N_p×N}}\) 的自相似图。然后,通过计算 \(\textcolor{blue}{S_x}\) 和 \(\textcolor{blue}{S_{x^′}}\) 之间的相关矩阵 \(\textcolor{blue}{M_C}\) 来排除自相似图的冗余纹理:

将 \(\textcolor{blue}{M_C}\) 与对角矩阵 \(\textcolor{blue}{I ∈ R^{N_p×N×N}}\) 进行比较: \(\textcolor{blue}{L_{cor} = ‖M_C − I‖_2}\),其中 \(\textcolor{blue}{M_C}\) 表示 CT 平扫图像与其增强图像的结构信息之间的相关性。 \(\textcolor{blue}{M_C}\)的对角线元素表示同一位置共享结构的关系,应该具有较强的响应性。 \(\textcolor{blue}{L_{cor}}\) 尝试将相关矩阵的非对角线元素等同于0并分离不同位置的像素。通过这种方式,我们可以增强两幅CT图像的共享结构并消除不相关的纹理。
为了最大化平扫 CT 图像 \(\textcolor{blue}{x}\) 和合成 CT 图像 \(\textcolor{blue}{y'}\) 之间的相互结构信息,我们计算它们的自相似图 \(\textcolor{blue}{S_x}\)、\(\textcolor{blue}{S_y^{\prime}}\) 并通过余弦距离测量它们的结构差异。

\(\textcolor{blue}{L_{cos}}\) 评估平扫 CT 图像和合成 CT 图像之间的结构差异,以进一步优化网络以保存 CT 结构。整体结构不变损失定义为:

其中 \(\textcolor{blue}{λ_a}\) 和 \(\textcolor{blue}{λ_b}\) 是平衡这两个损失函数的超参数。通过采用结构不变损失,可以减少提取的自相似性中的冗余特征,并使合成的CT图像的结构与平扫CT图像的结构保持一致。
3.完整的目标函数
为了优化所提出的 MAFormer,我们利用结构不变损失来保留结构,利用对抗性损失来生成真实且高质量的图像,并利用重建损失来监督像素级的 CT 生成。
3.1 对抗loss
为了使合成 CT 图像更加真实,在所提出的方法中应用了条件 GAN,其对抗性损失可以表示为:

其中生成器 \(\textcolor{blue}{G}\) 生成以平扫 CT 图像 \(\textcolor{blue}{x}\) 和Mask Estimator生成的Mask image图像 \(\textcolor{blue}{M}\) 为条件的 CT 图像 \(\textcolor{blue}{G(x, M)}\),D 将合成 CT 图像与以平扫 CT 为条件的目标 CT 图像 \(\textcolor{blue}{y}\) 区分开来图像。在训练过程中,生成器的目标是最小化该目标,而判别器则试图最大化该目标。
3.2 重建损失
为了提供逐像素监督,作者还在生成的 CT 图像 \(\textcolor{blue}{y^′}\) 和目标 CT 图像 \(\textcolor{blue}{y}\) 之间应用重建损失,定义为:\(\textcolor{blue}{L_{Rec} = ‖y − y^′‖_1}\)。
MAFormer 的总体目标函数如下:
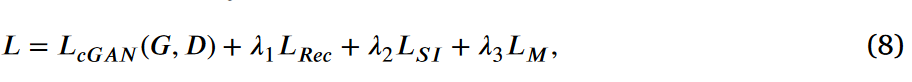
其中 \(\textcolor{blue}{λ_1}\)、\(\textcolor{blue}{λ_2}\) 和 \(\textcolor{blue}{λ_3}\) 是平衡这些损失函数的超参数。在这些目标函数的监督下,所提出的 MAFormer 不仅可以保证基本的像素级监督,而且可以生成高质量的逼真 CT 图像。
五、实验
1.数据集
作者主要在两个MPECT 数据集上进行实验,包括 VinDr-Multiphase和 MPECT 数据集。
VinDr-Multiphase 数据集是用于相位识别的腹部 MPECT 数据集,包括平扫 (P)、动脉期 (A) 和门静脉期 (V) CT 图像。该数据集由训练集(64 名患者和 32,993 个切片)、验证集(12 名患者和 4094 个切片)和测试集(7 名患者和 3798 个切片)组成。每个患者均进行CT平扫以及相应的动脉期和门静脉期CT扫描,每张切片的尺寸为512×512。
MPECT-data数据集是一个配对的MPECT数据集,包括374名在湘雅二医院成功接受MPECT的患者。该数据集由我们的放射科医生专家手动收集。每个患者有四次连续的时间顺序CT扫描,即平扫(P)、动脉期(A)、门静脉期(V)和延迟期(D)。每个CT切片的尺寸为512×512。我们将该数据集分为三部分,即训练集(224名患者和14,756个切片)、验证集(75名患者和5334个切片)和测试集(75名患者和5183个切片) 。该数据集将发布供公众访问。
为了将不同相位的 CT 扫描与普通 CT 扫描对齐,我们通过高级归一化工具(ANT)在两个数据集中执行仿射和变形配准,以互信息作为优化度量和弹性正则化。然后,通过窗口中心(60 HU)和窗口宽度(500 HU)的窗口变换,将配准的CT图像从原始范围[0, 4095]灰度级映射到显示范围[0, 255]灰度级。
2.实施细节和评估指标
我们的方法是使用 PyTorch 库实现的。生成器和判别器使用 Adam 优化器交替优化,最多 100 个 epoch,批量大小为 4。前 50 个 epoch 的初始学习率设置为 2 × 10−4,最后 50 个 epoch 线性衰减到零纪元。该生成器包括 3 个卷积层、后跟一个下采样层、9 个 MAB 模块和 3 个全卷积层。在 MATNorm 模块中,我们将掩模图像缩小 4 倍,并通过大小为 k × k(k = 64) 像素和步幅 s = 32 的滑动窗口选择前 n = 10 个 RoC。我们使用 ViT 的变换器在 MATNorm 中。掩模估计器由 3 个卷积层、3 个全卷积层和 1 个 sigmoid 层组成。在结构不变损失中,补丁的数量Np设置为256,补丁的高度Hp和宽度Wp为64。对于结构不变损失的特征提取器,我们采用VGG16作为主干。由两个内核大小为 1 × 1 的卷积层组成。特征提取器使用 LARS 优化器进行优化,权重的初始学习率为 0.2,偏差和批量归一化参数的初始学习率为 0.0048。学习率乘以批量大小并除以 256。我们在前 5 个 epoch 中对特征提取器使用学习率预热策略,之后我们使用余弦衰减计划将学习率降低 1000 倍。掩模估计器和特征提取器与生成器共同训练。所有实验均在两个具有 36 GB 内存的 NVIDIA Tesla V100 GPU 上进行。超参数λa、λb、λ1、λ2、λ3分别设置为0.001、1、100、1和100。源代码即将发布。
为了评估合成 CT 图像,我们应用了两种常用的指标,即峰值信噪比(PSNR)和结构相似性指数(SSIM),其中前者评估像素级相似性后者衡量结构感知相似性。值越高表示性能越好
3.与以往的方法比较
我们展示了 MPECT 数据和 VinDr-Multiphase 数据集的定量和定性结果,以将所提出的方法与现有方法进行比较,包括 pix2pix 、CycleGAN,CUT,F-LSeSim,DINO,CHAN和Chen等人提出的方法。
3.1 定量结果
在表 1 中,我们演示了不同阶段翻译在 MPECT 数据数据集上的 CT 翻译性能,包括平移到平移动脉期 (P-to-A)、平原期至门静脉期 (P-to-V) 以及平原期至延迟期 (P-to-D)。与现有方法相比,所提出的 MAFormer 在所有阶段 CT 翻译中均实现了最佳性能。具体来说,与基于编码器-解码器结构的次优方法相比,MAFormer 在转换 P-to-A CT 图像时将 PSNR 提高了 0.5608 dB。在 P-to-V 翻译中,MAFormer 的 CT 翻译性能优于基于 GAN 的方法,PSNR 分别为 1.2202 dB、0.9103 dB、2.2788 dB、1.1996 dB、1.5789 dB 和 1.1161 dB。配对 t 检验得出的 p-value证明改进具有统计显着性。这些结果不仅显示了所提出的 MAFormer 的有效性,而且验证了其相对于之前基于编码器-解码器和基于 GAN 的方法的优越性。

此外,我们还在 VinDr-Multiphase 数据集上验证了所提出的方法对于两个方向映射(包括 P 到 A 和 P 到 V CT 转换)的有效性。如表 2 所列,在 P-to-A 翻译过程中,MAFormer 优于基于 GAN 的方法,PSNR 分别为 0.5102 dB、0.2642 dB、0.3630 dB、0.1121 dB、0.2943 dB 和 0.8150 dB。根据 p 值,所有增量均具有统计显着性。这表明与现有的基于 GAN 的方法相比,所提出的方法是有效的。在 P-to-V CT 转换中,我们的方法还比基于编码器-解码器的方法实现了最高的性能,增量为 0.3704 dB。
为了评估各种方法的资源需求,我们在表 3 中列出了现有方法和 MAFormer 的参数 (Param)、FLOP、内存和推理时间。值得注意的是,MAFormer 凭借使用最少的参数(仅 4184 个)而脱颖而出。与其他方法相比的参数。此外,MAFormer 的推理时间与当前方法相当,排名第三。这些表明所提出的 MAFormer 不仅有效,而且对于现实世界的临床实践也很高效,因为它需要较低的计算资源。

3.2 定性结果
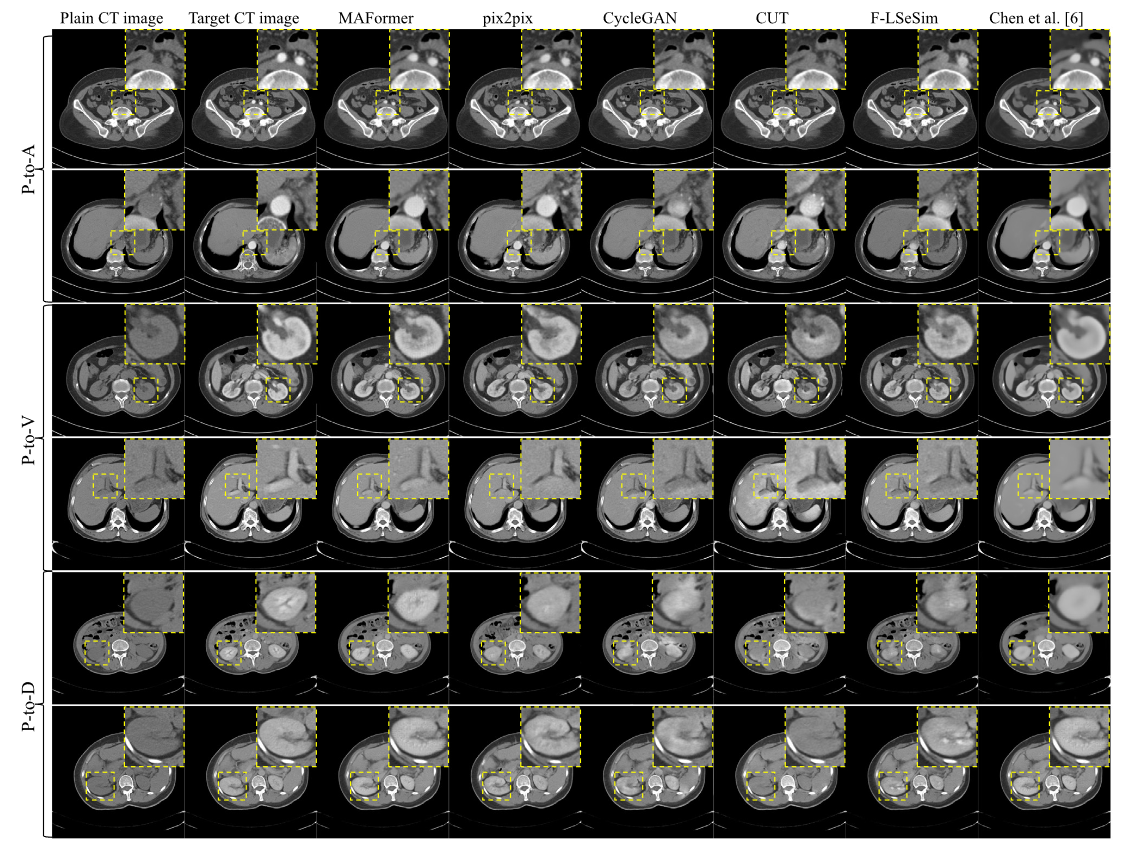
图4.MPECT 数据集上的定性结果与最先进的方法进行比较,包括平扫期到动脉期 (P-to-A)、平扫期到门静脉期 (P-to-V) 以及平扫期到延迟期(P 到 D)翻译。放大的图像块显示了合成 CT 图像的对比度增强区域。
图 4 可视化了所提出的 MAFormer 的结果,与 MPECT 数据数据集上不同阶段 CT 转换(包括 P 到 A、P 到 V 和 P 到 D 转换)的现有方法进行了比较。第一列和第二列展示了普通 CT 图像和目标 CT 图像,其余列分别显示了由所提出的 MAFormer、pix2pix、CycleGAN、CUT、F-LSeSim以及 Chen 等人提出的方法。我们裁剪 CT 图像的对比度增强区域,并将其放大版本放在右上角。显然,MAFormer 生成的 CT 图像比其他方法生成的 CT 图像更接近目标 CT 图像。具体来说,在 P-to-A 翻译中,与 CycleGAN和 CUT相比,所提出的 MAFormer 可以增强对比区域并保留这些区域的结构。此外,与其他方法相比,MAFormer 生成的 CT 图像质量更高,器官细节更多。还值得注意的是,合成 CT 图像的结构应与普通 CT 图像的结构相似,并且 MAFormer 可以比 pix2pix 保留更多的 CT 图像结构。与现有方法相比,MAFormer 成功生成了清晰、逼真且结构不变的 CT 图像,表明了其相对于其他方法的优越性。如图 5 所示,我们的 MAFormer 可以在 P 到 A 翻译中正确突出显示肾脏和主动脉区域,而其他方法主要增强主动脉而忽略肾脏区域。这表明与现有方法相比,MAFormer 能够显示不同 CT 区域的正确增强特征。事实上,MPECT 中不正确的对比度增强可能会导致对软组织特征的误解,从而可能导致严重的病情误诊。此外,在增强过程中改变组织形状可能会导致放射科医生误判肿瘤类型。
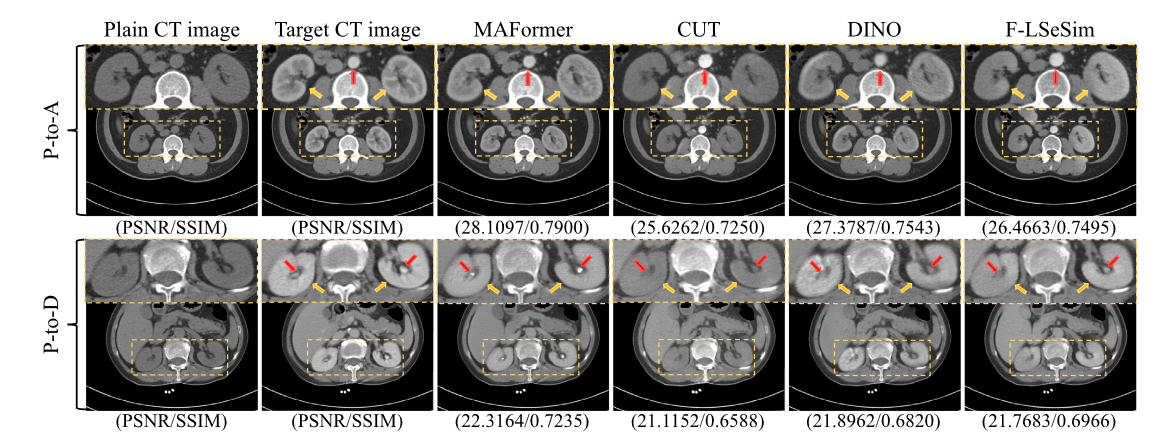
图5.MPECT 数据集上的视觉结果与现有的平相至动脉期(P 至 A)和平移至延迟期(P 至 D)转换的方法进行了比较。放大的图像块显示了合成 CT 图像的对比度增强区域。
为了在 VinDr-Multiphase 数据集上进行验证,图 6 显示了 MAFormer 和现有方法的可视化结果。如放大的图块所示,MAFormer 生成的合成 CT 图像保留了与目标 CT 图像类似的对比度增强区域,并且在 P 到 A 转换期间与普通 CT 图像相比,内容的形状保持不变。这表明所提出的方法不仅可以突出正确的对比区域,而且可以保留平扫 CT 图像的结构。

图6.VinDr-Multiphase 数据集上的定性结果,与状态相比我们裁剪并放大合成 CT 图像的对比度增强区域以获得更多细节。
4.消融实验
4.1 MATNorm的有效性
对 MPECT 数据集进行了详细的消融研究,以调查 MATNorm 的有效性,如表 5 和图 7 所示。我们消融了所提出方法的 MATNorm 和 SIL,并将其作为基线模型,实现了 CT PSNR 为 27.1978 dB 的转换性能。如表 5 所示,当我们将 MATNorm 集成到基线模型中时,性能显着提高,PSNR 为 0.7612 dB,与基线模型相比,表现出显着的改进(p 值 < 0.001),并表明MATNorm 的有效性。

RoC 数量分析:所提出的 MATNorm 选择前 n 个 RoC,并利用transformers来利用 RoC 之间的相关性。更多 RoC 将为 MATNorm 提供有关减法图像的更丰富的信息,这可能需要transformers部分更多的计算资源,反之亦然。因此,RoC 的数量显着影响网络的效率和有效性。为了分析不同数量的 RoC 的有效性,我们使用不同的设置训练基线模型,如表 5 所示。当 RoC 的数量为 10 时,MAFormer 实现了最佳性能,PSNR 值为 27.9590 dB。当 RoC 超过 10 个时,MAFormer 的性能逐渐下降,因为前 10 个 RoC 可以覆盖掩模图像的所有对比区域,其余 RoC 可能包括背景等非对比区域。这表明具有 10 个 RoC 的 MATNorm 是 MAFormer 的最佳设置。
掩模图像的可视化:在实际应用中,掩模图像可以显示平扫CT图像和增强CT图像之间的差异,这可以进一步应用于腹部CT图像上HCC的检测。在本文中,我们采用掩模估计器来合成掩模图像以突出显示对比度增强区域并将其集成到网络中,使其质量对于 CT 翻译至关重要。为了评估合成掩模图像的质量,我们将 P-to-A、P-to-V 和 P-to-D CT 转换的合成掩模图像可视化并放大一些补丁,如图 7 所示。在P-to-A翻译,真实和合成掩模图像的放大区域都有对比,这表明掩模估计器可以捕获对比度增强区域作为减法技术。在图7的第二行中,合成掩模图像可以像真实掩模图像一样突出显示两个肾脏区域,这表明掩模估计器也可以同时识别多个对比区域。

图7.MPECT 数据集上掩模图像的可视化,用于 P-to-A、P-to-V 和 P-to-D 转换。第一列和第二列显示普通 CT 图像、目标图像和合成 CT 图像。最后两列展示了掩模估计器生成的真实掩模图像和合成掩模图像。放大的色块显示对比度增强的区域,以进行细节比较。
4.2 \(L_{SIL}\) 的有效性
为了验证 \(L_{SIL}\) 的有效性,我们取消了掩模估计器和 MATNorm 模块,并将 CT 转换性能与基线模型进行比较。如表4所示,PSNR值大幅改善,PSNR达到0.5688 dB。 p 值证明这种改进具有统计显着性。这说明CT结构的完美保存有利于CT翻译。

\(L_{SIL}\)权重分析:为了保持CT结构不变,我们测量普通CT图像和合成CT图像之间的结构差异来优化生成器。结构差异 \(λ_b\) 的权重对于对合成 CT 图像施加适当的限制至关重要。为了找到最佳的 \(λ_b\),我们评估了 \(λ_b\) 等于 0.1、1、10 或 100 时的 CT 翻译性能。如表 6 所示,具有 \(L_SIL\)(\(λ_b = 1\))的基线模型实现了最佳性能,PSNR 为 27.7666 dB,超过 \(λ_b = 100\) 的方法 0.3426 dB。这意味着对CT结构的过强限制可能会影响CT翻译性能。
自相似图的可视化:为了证明自相似图(SS-Map)的合理性,我们在 P-to-A、P-to-V 和 P-to-D CT 翻译上展示了 SS-Map 示例。 MPECT 数据集。在图 8 中,我们可视化从普通 CT 图像和合成 CT 图像中裁剪出的斑块的 SS-Maps \(S_x\) 和 \(S^\prime_y\)。在P-to-A转换中,第四列和第五列完美地显示了裁剪后的斑块的CT结构曲线,并且\(S_x\)和\(S^\prime_y\)非常相似,这意味着\(L_{SIL}\)的有效性。当从 P-to-V 转换时,SS-Map 会丢弃软组织的纹理并提取 CT 结构。证明对相关矩阵的限制可以减少冗余,提取清晰的CT结构。

图8.结构感知自相似图(SS-Map)的可视化。第三列和第四列显示第一列和第二列中的普通 CT 图像和合成 CT 图像的相应黄色斑块的 SS-Map。
4.3 MAFormer 不同训练时间的效果
为了评估所提出的 MAFormer 模型的有效性,我们在 MPECT 数据集上进行了不同时期数(包括 10、20、50 和 100)的 P-to-A 翻译训练。如表 7 所示,MAFormer当训练 100 个 epoch 时,模型达到最佳性能。尽管 MPECT 数据集是一个包含 14,756 张用于训练的 CT 图像的大型集合,但我们发现训练过程只需要大约两天的时间。这一发现表明计算时间不是瓶颈,从而证实了我们提出的 MAFormer 模型在临床应用中的实用性。

5.讨论
为了进一步分析 MAFormer 在消除真实 MPECT 图像和合成 MPECT 图像之间域差距方面的有效性,我们比较了它们之间的灰度直方图,并展示了它们针对 MPECT 数据集的 t-SNE 可视化。我们首先使用灰度直方图来评估 MPECT 数据数据集上真实 CT 图像和合成 CT 图像的灰度分布之间的距离。在图9中,我们可视化了不同时相的平扫CT图像、真实和合成MPECT图像的灰度直方图,包括动脉期(A)、门静脉期(V)和延迟期(D)。如图9(a)所示,平扫CT图像与真实A CT图像相距甚远,表明它们的灰度分布存在显着差异。当将所提出的 MAFormer 应用于普通 CT 图像时,合成的 A CT 图像在不同灰度级下非常接近真实的 A CT 图像。这表明合成的 A CT 图像与真实的 A CT 图像具有相似的灰度分布。此外,这还意味着我们的 MAFormer 具有将普通 CT 图像转换为逼真的 MPECT 图像的能力。

图9.MPECT 数据数据集上三个不同阶段的平扫 CT、真实和合成 MPECT 图像的灰度直方图,包括 (a) 动脉期、(b) 门静脉期和 (c) 延迟期。
此外,我们还应用 t-SNE 可视化来比较三个阶段的 MPECT 数据数据集上的普通 CT、真实和合成 MPECT 图像的高级特征分布。为了提取可视化的代表性特征,我们首先在 MPECT 数据集上预训练 ResNet-34 模型以进行 MPECT 相位识别,并使用预训练模型提取 CT 图像的特征。如图 10(a) 所示,普通 A CT 图像和真实 A CT 图像分别位于两个独立的簇中,并且彼此相距较远,表明它们之间存在显着的域间隙。当我们通过所提出的 MAForm 将平扫 CT 转换为动脉期时,合成 A CT 图像几乎与真实 A CT 图像重叠,表明真实 CT 图像和合成 CT 图像之间的域间隙很小。它还表明我们的方法可以有效地将普通 A CT 图像转换为真实的 A CT 图像。

图10.MPECT 数据数据集上三个不同阶段的平扫 CT、真实和合成 MPECT 图像的 t-SNE 可视化,包括 (a) 动脉期、(b) 门静脉期和 (c) 延迟期。
六、总结
在这项工作中,我们提出了一种新颖的 MAFormer 将普通 CT 转换为 MPECT 图像,其中包括用于减法图像预测的掩模估计器、作为归一化层的 MATNorm 和用于结构保存的结构不变损失。据我们所知,这项工作代表了利用 CT 翻译关键领域知识(即减影图像)的首次努力。所提出的掩模估计器尝试从普通 CT 图像中预测减影图像。为了突出减影图像的对比度增强区域,所提出的 MATNorm 将减影图像集成到网络中,并捕获对比区域之间的远程依赖性。为了保持合成 CT 图像的结构,提出了结构不变损失来提取结构信息并最小化普通 CT 图像和合成 CT 图像之间的结构差异。在 VinDr-Multiphase 和 MPECT-data 数据集上进行了定量和定性实验,以证明所提出的 MAFormer 的有效性及其相对于现有方法的优越性。在实际临床应用中,医生可以将MAFormer应用到平扫CT上,让患者获得合成的MPECT,并据此诊断肝脏疾病,这样可以避免MPECT检查中使用的造影剂潜在的过敏现象。