
一、引言
计算机断层扫描 (CT) 成像技术为临床观察、疾病诊断和治疗指导提供非侵入性、详细的横截面图像。造影剂增强 CT (CECT) 联合 CT 血管造影 (CTA) 专门用于血管成像,可有效增强感兴趣的区域,例如血管病变或其他器官病变。尽管CTA具有诊断优势,但CTA依赖于血管内注射昂贵的碘造影剂(ICAs),对碘过敏和肾功能不全的患者构成风险,限制了其临床应用。因此,从 NCCT 图像中获得类似 CECT 的图像可以减少对 ICA 的依赖,并提供更精确的病理细节,具有进一步发展的潜力。
通常,肝病的诊断过程涉及多阶段CECT图像,例如动脉期和静脉期。与NCCT图像相比,前者强调血管增强,而后者则侧重于增强相关器官或组织。强调 NCCT 图像与其他阶段图像之间微妙而关键的区别对于生成类似 CECT 的图像至关重要,这确保了对血管和器官结构的全面和准确描述。
近年来,基于深度学习方法的医学图像翻译取得了重大进展,特别是在生成对抗网络模型和扩散模型中。Chandrashekar等使用2D Cycle-GAN生成动脉期动脉瘤切片,通过该切片可以区分管腔和管腔内血栓。在3D医学图像翻译中,Choi等人使用3D Pix2pix将非对比胸部CT转换为CECT图像,从而更好地描绘纵隔淋巴结。Khader等表明,扩散概率模型可以合成高质量的MRI和CT图像,可用于乳房分割。Wang等将潜在扩散模型作为高分辨率MRI重建的生成先验。
尽管许多扩散模型在医学图像翻译中表现出了强大的转化能力,但大多数扩散模型都忽略了与多模态图像信息的互表示。实际上,同一解剖结构的不同模态应该具有相似的表示分布,差异突出了对比度增强的区域,这对于在合成图像中强调至关重要。不仅仅将目标图像作为模型训练的实况,而是在编码过程中利用两个模态图像的相关性。具体来说,作者设计了一种基于表征学习的自适应相似性损失,以使模型的生成趋向于差异。这种简单而有效的方法增强了潜在空间中的相互表征,在没有条件指导的情况下指示对比增强区域,并实现了对这些区域的同等重视。考虑到训练期间的生成能力,作者结合了一个动态相似性掩码,这有助于早期模型拟合到结构区域,然后拟合到对比度增强的区域。
二、方法
1.数据集
作者在内部多相腹部 CT 数据集 (MP-ACT) 上评估了作者提出的方法,该数据集包含 164 对非对比剂和动脉期图像,以及 170 对非对比剂和静脉期图像。MPACT 数据集有条不紊地分为训练子集和验证子集,动脉期和静脉期保持 4:1 的比例(训练数据:132 (A) 和 136 (V),验证数据:32 (A) 和 34 (V))。为了实现灰度范围的均匀性,作者将所有原始数据设置为窗口宽度为 400 HU(Houndfield 单位),窗口级别设置为 0 HU。此外,对所有大小为 256 × 256 × 48 的训练数据块进行随机裁剪。
2.模型架构
个体生成方法的局限性源于它们倾向于将过多的能力分配给自我建模,或者它们在捕捉医学图像中微妙但高频的细节方面效率不足。为了解决这个问题,许多研究采用了两阶段方法,保证高保真度生成,同时为第二阶段生成模型提供足够的感知信息。按照LDM的设计,作者提出了一种两阶段的医学图像翻译模型,如图1所示。
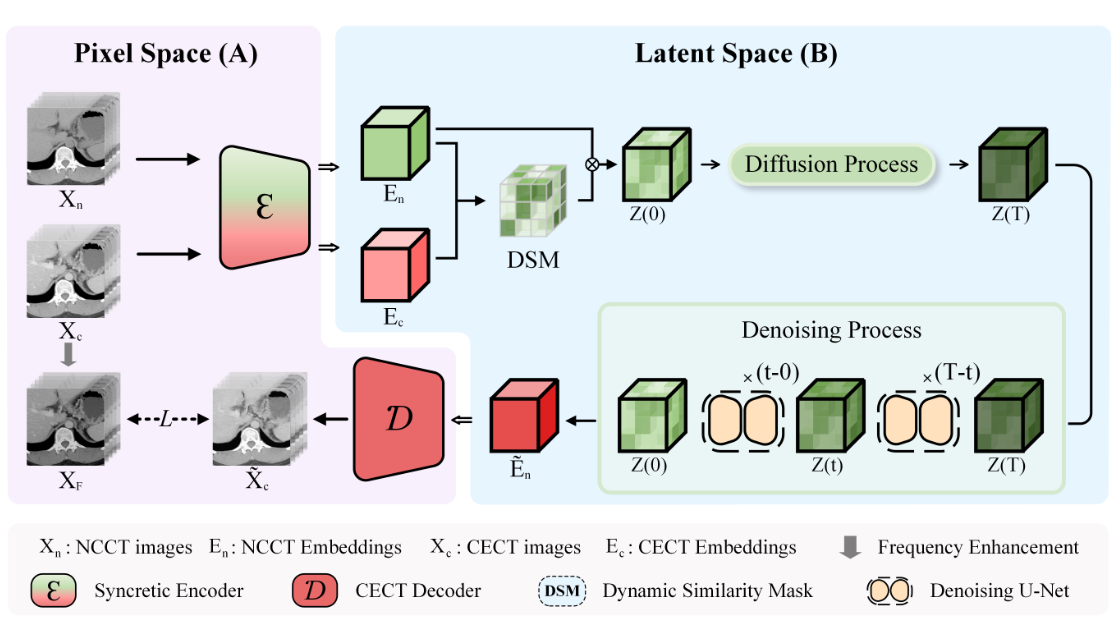
图1:融合潜在扩散模型的图表。 (A) 说明了从潜在空间生成 CECT 图像的像素空间,而 (B) 说明了相似性引导嵌入的扩散和去噪过程。
假设成对训练子集 \(\textcolor{blue}{\{(x_n, x_c)\}^M_{i=1}}\) 由相同数量的非对比和对比增强 CT 图像组成,本文的目标是训练一个高保真生成模型将 \(\textcolor{blue}{x_n}\) 转换为 \(\textcolor{blue}{x_c}\)。在图1的子图(A)中,首先训练一个自动编码器来提供一个低维且具有代表性的潜在空间,在符号上相当于像素空间。该方法没有使用对比增强 CT 图像进行条件引导,而是将它们作为融合编码器 \(\textcolor{blue}{\mathcal{E}}\) 的输入,并相应地从 CECT 解码器 \(\textcolor{blue}{\mathcal{D}}\) 生成重建的对比增强 CT 图像\(\textcolor{blue}{\tilde{x}_c}\)。
值得注意的是,非对比和对比增强CT图像的嵌入都是在编码后获得的,并且这两个嵌入之间的相似性在潜在空间中被进一步利用。来自不同阶段但相同解剖结构的表示趋于收敛,使得相似性成为分析非对比度和对比度增强区域的有用分布。
3.图像压缩
遵循既定的临床方案,外科医生通常更喜欢使用非增强 CT 图像,而不是增强 CT 图像。然而,之前的许多研究忽视了在临床应用的限制下充分利用多模态图像的机会。考虑到上述因素,作者使用设计的融合编码器 \(\textcolor{blue}{\mathcal{E}}\) 组合两个模态图像的嵌入,通过表示学习增强它们的相互表示。如图 2 所示,所提出的融合编码器包含两个相同的架构,两者在训练期间共享相同的权重。
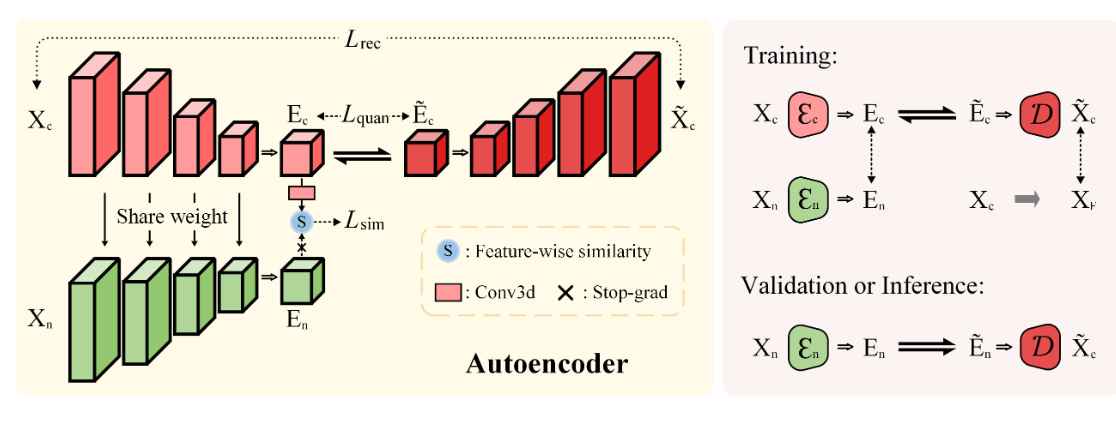
图2:使用融合编码器的图像压缩模型图。右子图说明了模型在训练和验证过程中的独特压缩策略。
受到SimSiam的启发,该目标是最大化双相 CT 图像中相同解剖结构所衍生的嵌入 \(\textcolor{blue}{E_n}\) 和 \(\textcolor{blue}{E_c}\) 之间的相似性。这项努力是为了增强从多模态图像中提取的感知信息。此外,作者还认为相互嵌入之间的差异对目标图像的生成很重要,特别是在对比度增强的区域。因此作者对focal loss做了轻微修改,调整特征相似性损失,更多地关注对比度增强的区域。公式如下:
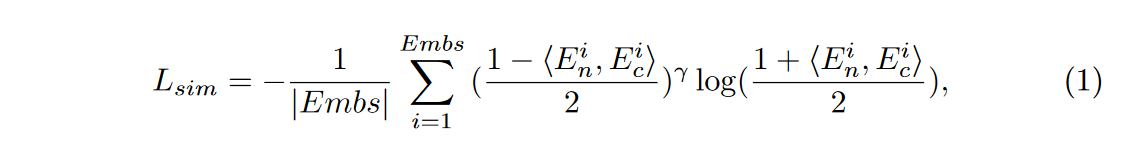
其中 \(\textcolor{blue}{E^i_n}\) 和 \(\textcolor{blue}{E^i_c}\) 是集合 \(\textcolor{blue}{E_{mbs}}\) 中的元素,表示特征方面的相似性。 \(⟨·,·⟩\) 表示潜在空间中两个不同嵌入之间的余弦相似度,其范围为 \([-1, 1]\)。\(\textcolor{blue}{γ}\) 一个常数,用于为特征相似性分配自适应权重。在本文中,设置 \(\textcolor{blue}{γ=1}\)。
除了上述相似性损失之外,本文的图像压缩模型基于 VQGAN,使用重建损失、基于生成目标的量化损失和基于patch的对抗目标损失进行训练。因此,本文的融合生成模型是通过在自动编码器训练过程中最小化总损失 \(\textcolor{blue}{L_{auto}}\) 之和来训练的,如图 2 所示。损失公式如下:
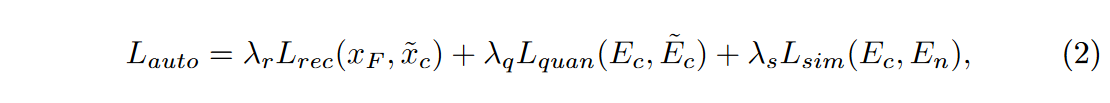
其中\(\textcolor{blue}{λ_r}\)、\(\textcolor{blue}{λ_q}\)和\(\textcolor{blue}{λ_s}\)分别表示\(\textcolor{blue}{L_{rec}}\),\(\textcolor{blue}{L_{auto}}\)和\(\textcolor{blue}{L_{sim}}\)的权重。 \(\textcolor{blue}{x_F}\) 表示高频增强后的对比增强 CT 图像。
综上所述,编码器 \(\textcolor{blue}{\mathcal{E}}\) 是专门为训练期间的双编码非造影和造影增强 CT 图像而设计的,但能够仅依赖于非造影 CT 图像来执行翻译任务。图 2 的右子图中还提供了有关这两种不同策略的更多详细信息。
4.潜在扩散模型
减轻在像素空间中重建图像时过多的计算负担的典型解决方案是将它们压缩到潜在空间中。几项著名的研究已经证明了扩散模型在高分辨率图像合成中的功效,并且不会产生过多的计算成本。为了将一种模态图像转换为另一种模态图像,大多数扩散模型在模型训练的第二阶段直接将目标图像作为附加输入。虽然这种设计已经证明了优异的结果,但作者建议将它们包含在自动编码器训练中,然后在扩散过程中利用它们的嵌入可以实现更优越的性能。
遵循这种直觉,作者引入了一系列调整,以在相似性指导下细化扩散模型中的两个嵌入。具体来说,给定来自不同模态的两个嵌入 \(\textcolor{blue}{E_n}\) 和 \(\textcolor{blue}{E_c}\),利用具有相同形状的动态特征相似性掩模 \(\textcolor{blue}{S}\) 来迭代地关注当前时期的感兴趣区域。显然,该目的是增强 \(\textcolor{blue}{E_n}\) 在对比度增强区域的代表性,因此,在扩散模型训练过程中,有必要逐步引导模型将大的、高相似性的区域转移到小、低相似性的区域。 \(\textcolor{blue}{S}\) 的公式如下:
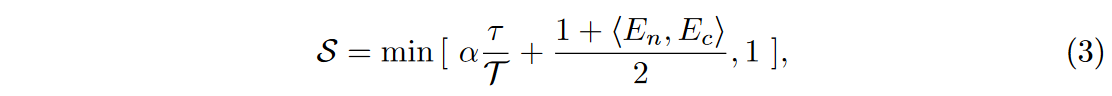
其中 \(\textcolor{blue}{τ}\) 和 \(\textcolor{blue}{\mathcal{T}}\) 分别表示当前epoch和总epoch。 \(\textcolor{blue}{S}\) 表示 \(\textcolor{blue}{τ}\) 时期非对比增强 CT 图像和对比增强 CT 图像的相应嵌入之间的动态余弦相似度。 \(\textcolor{blue}{\alpha}\) 是控制相似度变化率的常数,设置为2。
在医学图像翻译中,条件扩散模型利用条件自动编码器进行合成控制,并受到目标模态图像和分割等条件的指导。与这些方法不同的是,作者在扩散开始时将附加信息转化为便于原始嵌入,从而更灵活地控制合成过程。具体来说,采用特征相乘来强化通过动态相似性指导所预期的方向。基于非对比和对比增强 CT 图像对,通过以下方式优化模型
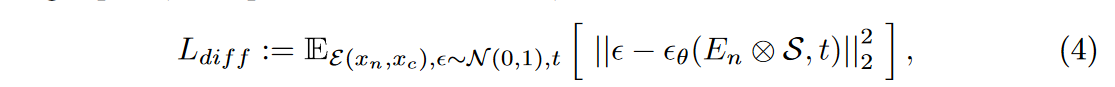
其中⊗表示按特征相乘,\(\textcolor{blue}{t}\) 从\(\textcolor{blue}{1,···,T}\) 中均匀采样。
与融合自动编码器的验证过程类似,作者还通过将特征相似性掩模转换为全一矩阵的简单过程,仅基于非对比 CT 图像来完成图像生成。
三、实验
1.实施细节
对于融合自动编码器和扩散模型训练,作者设计的两阶段模型利用 MP-ACT 数据集。图像压缩采用VQ-GAN,扩散模型基于LDM,使用PyTorch和MONAI库实现。在自动编码器训练期间,作者将批量大小设置为 1,包括自动编码器训练期间的一对两相 CT 图像,同时采用 AdamW 优化器,初始学习率为 2 × 10−6,在两个 A800 GPU 上进行 1000 次迭代。在扩散模型训练期间,作者将批量大小设置为 2,将时间步长设置为 1000,在三个 A6000 GPU 上进行 5000 次迭代。为了评估作者提出的方法,采用归一化平均绝对误差(NMAE)、峰值信噪比(PSNR)和结构相似性指数测量(SSIM)来评估生成质量。
2.与令人兴奋的模型的比较
为了证明\(\mathsf{S^2LDM}\)的有效性,作者在他们内部的 MP-ACT 数据集上与表 1 中最先进的生成模型进行了比较实验。所有实验都旨在执行两个不同阶段之间的图像转换:从 NCCT 图像到动脉和静脉期 CECT 图像。虽然其他模型通过将源图像和目标图像作为输入来评估性能,但在图像转换任务中专门采用非对比 CT 图像。
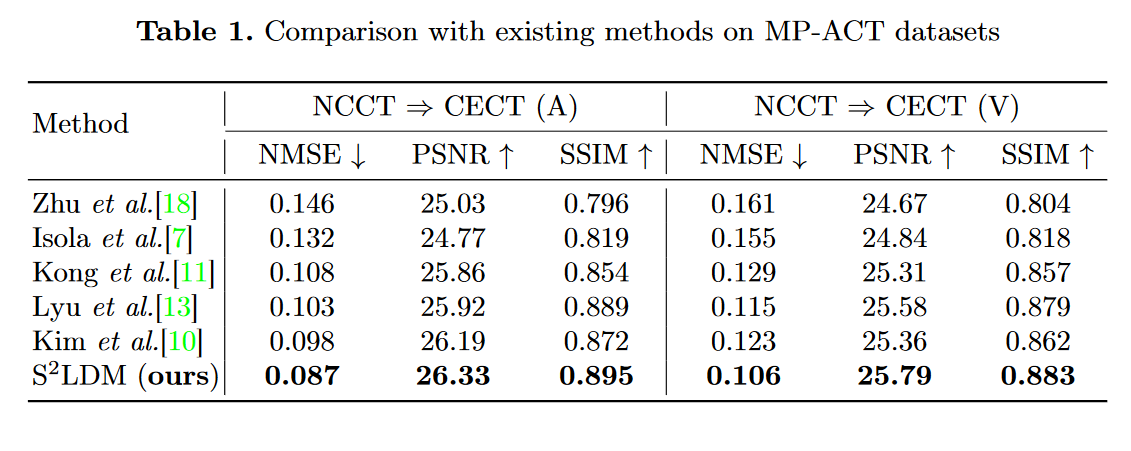
如表 1 所示,我们提出的方法在定量评估中优于大多数生成模型。在图 3 中,很明显,\(\mathsf{S^2LDM}\) 获得的结果非常接近真实的对比度增强区域,特别是在血管组织中。绿色箭头清楚地说明了我们的融合编码器和相似性引导扩散模型在特定情况下所促进的增强。
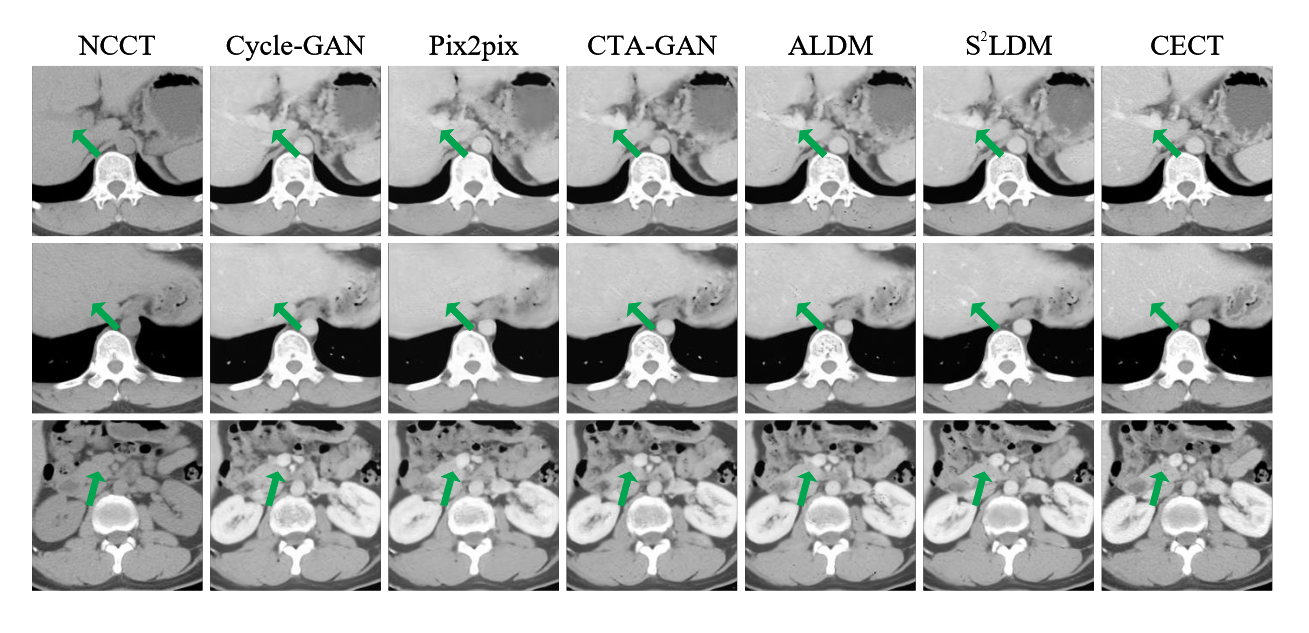
图3:\(\mathsf{S^2LDM}\) 结果的可视化和静脉期比较模型。
3.消融研究
为了验证\(\mathsf{S^2LDM}\)中每个组件的有效性,作者进行了表 2 所示的实验,逐渐消除了 \(\mathsf{S^2LDM}\) 的各个组件。具体来说,作者分析了融合编码器 \(\textcolor{blue}{\mathcal{E}}\)、自适应相似性损失 \(\textcolor{blue}{L_{sim}}\) 和动态相似性掩模 \(\textcolor{blue}{S}\),检查它们在模型训练期间的能力。超参数在所有消融实验中保持一致。
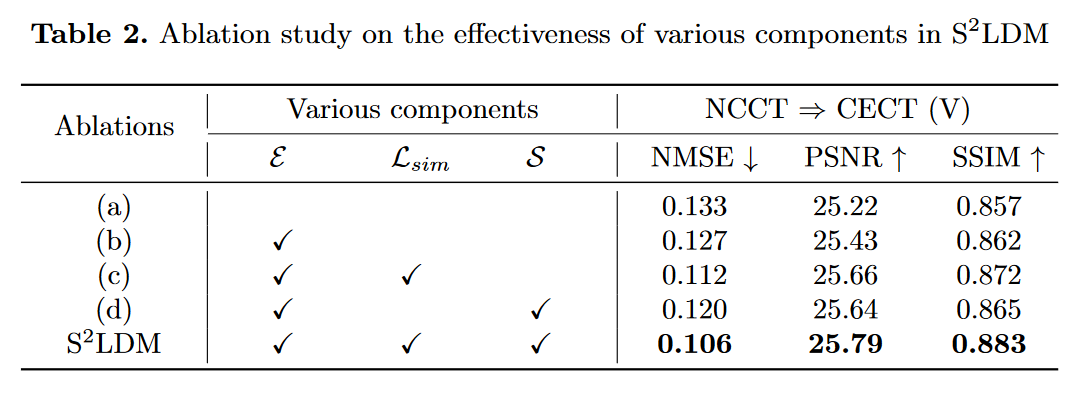
如表 2 所示,基线实验 (a) 涉及原始的潜在扩散模型,没有任何其他组件。在(b)中,作者在自动编码器训练期间引入 \(\textcolor{blue}{\mathcal{E}}\)。对于实验(c)和(d),作者在(b)的基础上单独合并\(\textcolor{blue}{L_{sim}}\)和\(\textcolor{blue}{S}\)。显然,每个组件都有助于提高医学图像翻译性能。
四、结论
在本文中,作者提出了一种名为 \(\mathsf{S^2LDM}\) 的新型图像转换模型,专门用于从非增强 CT 图像到增强 CT 图像的转换。在 LDM 的基础上,作者进一步探索了扩散模型中两种不同模式之间相似性的应用。具体来说,作者结合了一个融合编码器来增强基于表示学习的接近度,并结合自适应相似性损失来强调图像压缩模型训练期间的相异性。同时,强调加强潜在空间中的对比度增强区域,可能表现为两个嵌入中的差异。为了解决这个问题,采用动态相似掩模来逐渐引导模型在对比度增强区域收敛。通过比较和消融研究,验证了 \(\mathsf{S^2LDM}\) 在医学图像翻译中的有效性。