
一、引言
在现实场景中,视频超分辨率(VSR)是一项具有挑战性的任务,旨在提高低质量视频的质量以产生高质量的结果。与之前主要关注合成退化或特定相机相关退化的工作不同,由于需要解决低质量视频中常见的复杂和未知退化,例如缩减采样、噪点、模糊、闪烁和视频压缩,因此这项任务要求更高。此外,保持视觉保真度和确保时间连贯性对于输出视频的感知质量至关重要。尽管最近基于卷积神经网络(CNN)的网络在缓解多种形式的退化方面取得了成功,但由于它们的生成能力有限,它们在产生逼真的纹理和细节方面仍然不足,这通常会导致过度平滑,这可以在图1所示的RealBasicVSR结果中观察到。

图1:真实世界和 AI 生成视频的视频超分辨率比较。Upscale-A-Video展示了出色的升级能力。通过使用适当的文本提示,它取得了令人印象深刻的效果,其特点是更精细的细节和更高的视觉真实感。(放大以获得最佳视图)
扩散模型在生成高质量图像和视频方面表现出令人印象深刻的熟练程度。利用其生成潜力,已经提出了基于扩散的模型用于图像恢复,包括从头开始训练和从预训练的稳定扩散模型进行微调。这些方法有效地缓解了在基于CNN的模型中经常观察到的过度平滑问题,产生了具有更逼真的细粒度细节的结果。然而,使这些扩散先验适应VSR仍然是一个不小的挑战。这种困难源于扩散采样中固有的随机性,这不可避免地会在生成的视频中引入意想不到的时间不连续性。这个问题在潜在扩散中更为明显,VAE解码器在低级纹理细节中进一步引入了闪烁。
最近,通过引入时间一致性策略,使图像扩散模型适应视频任务,其中包括:
1️⃣使用时间层(如3D卷积和时间注意力)微调视频模型;
2️⃣在预训练模型中采用零样本机制,如跨帧注意力和流引导注意力。
尽管这些解决方案显著提高了视频稳定性,但仍存在两个主要问题:1️⃣ 当前的方法在U-Net功能或潜在空间中运行,难以保持低级一致性,仍然存在纹理闪烁等问题。2️⃣现有的时间层和注意力机制只能对短的本地输入序列施加约束,限制了它们在较长视频中确保全局时间一致性的能力。
为了解决这些问题,作者采用了局部-全局策略来保持视频重建中的时间一致性,同时关注细粒度纹理和整体一致性。在local video clip中,作者在视频数据上使用额外的时间层微调预训练图像 ×4 upscaling model。具体来说,在潜在扩散框架中,首先使用集成的 3D 卷积和时间注意力层对 U-Net 进行微调,然后使用视频条件输入和 3D 卷积对 VAE 解码器进行微调。前者显著实现了局部序列的结构稳定性,而后者则进一步提高了低级别的一致性,减少了纹理闪烁。在more global scale,作者推出了一种新颖的、无需训练的流引导循环潜在传播模块。它跨越短视频片段,在推理过程中双向进行逐帧传播和潜在融合。该模块利用长期序列中的潜在融合,可提高长视频的整体稳定性。
进一步研究了扩散模型在VSR任务中的生成潜力。按照文本引导的方式,本文的模型可以利用文本提示作为可选条件来引导模型产生更逼真和高质量的细节,如图 1 所示。此外,可以通过在输入中注入噪声来稀释其劣化,从而增强了模型对严重或看不见的退化的鲁棒性。通过调整添加噪声的水平,可以在扩散模型中调节恢复和生成之间的平衡。较低的噪声水平优先考虑模型的恢复能力,而较高的噪声水平则鼓励生成更精细的细节,从而在输出的保真度和质量之间实现权衡。
总而言之,本文的主要贡献是为现实世界的VSR提供了一种实用而稳健的方法。特别是,我们进行了详尽的探索,将局部-全局时间策略整合到潜在扩散框架中,增强了时间的连贯性和生成质量。进一步研究了通过允许文本提示指导纹理创建来提高多功能性的方法,并提供对噪点水平的控制以平衡恢复和生成,从而实现保真度和质量之间的权衡。
二、方法
如图 2 所示,本文的框架在潜在扩散模型 (LDM) 中同时包含局部和全局模块,以保持视频段内和视频段之间的时间一致性。在每个扩散时间步长内 (\(t = 1, 2 . . .,T\)),视频被分割成多个片段,并使用包含时间层的 U-Net 进行处理,以确保每个片段内的一致性。如果当前时间步长落在用户指定的全局细化步骤 (\(T^∗\)) 范围内,则采用递归潜在传播模块来提高推理过程中跨段的一致性。最后,使用微调的VAE解码器来减少剩余的闪烁伪影。得益于扩散范式,该模型表现出非凡的多功能性:1)输入文本提示可以通过改进的真实感和细节进一步提高视频质量。2) 用户指定的噪声水平可以控制质量和保真度之间的权衡。
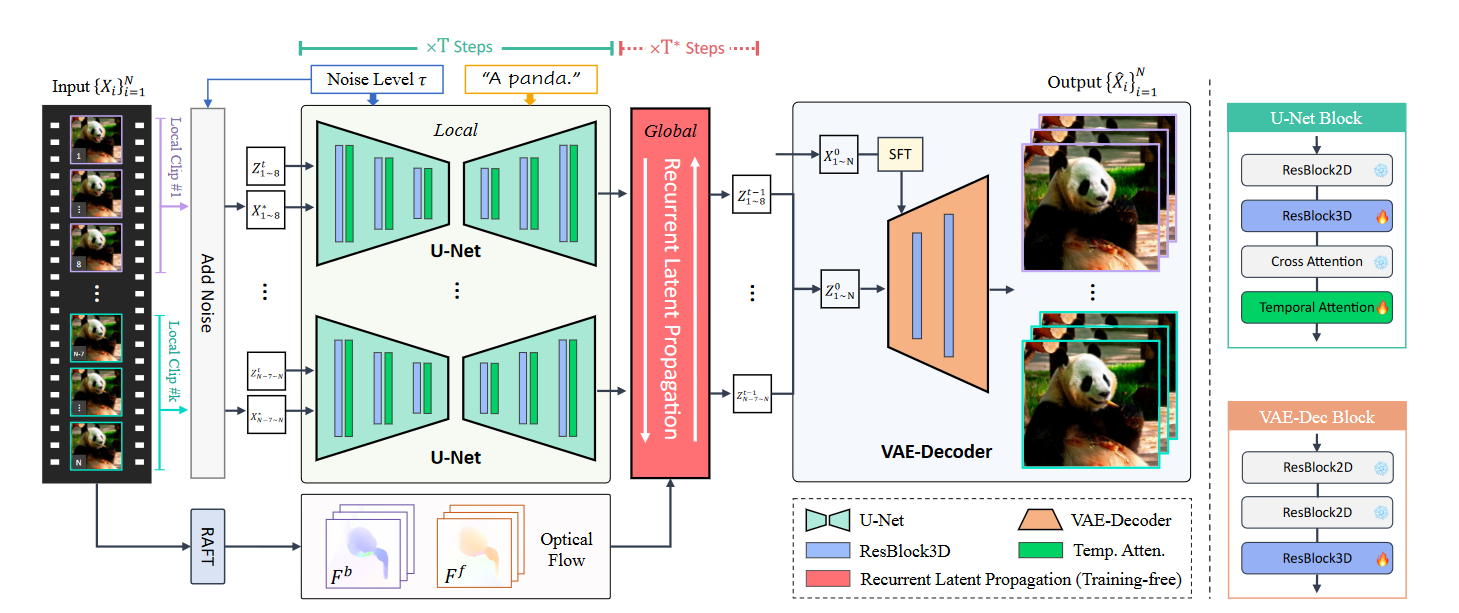
图2:Upscale-A-Video 概述。Upscale-A-Video 使用局部和全局策略处理长视频,以保持时间连贯性。它将视频分成多个片段,并使用具有时间层的 U-Net 进行处理,以实现片段内的一致性。在用户指定的扩散步骤中,使用循环潜伏传播模块来增强段间一致性。最后,经过微调的VAE解码器可减少剩余的闪烁伪影,从而实现低级一致性。该模型还允许用户使用文本提示来指导纹理创建,并调整噪点水平以平衡恢复和生成的效果。
1. 视频片段的局部一致性
为了将预训练的文本到图像SD模型应用于视频相关任务,现有的视频扩散模型通常采用3D卷积,时间注意力和跨帧注意力等技术来确保时间一致性。
微调 Temporal U-Net: 在预训练的图像模型中引入了额外的时间层,并学习了视频片段中的局部一致性约束。如图 2 所示,在修改后的时态 U-Net 中,选择时间注意力和基于 3D 卷积的 3D 残差块作为时间层,并将它们插入到预训练的空间层中。时间注意力层沿时间维度执行自我注意,并聚焦于所有局部帧。此外,作者将旋转位置嵌入(RoPE)添加到时间层中,为模型提供时间位置信息。
时间层使用与预训练图像模型相同的噪声时间表进行训练。重要的是,在训练期间保持预训练的空间层固定,并且仅使用方程(1)优化插入的时间层。这种策略的一个基本好处是,它允许我们利用从巨大的高质量图像数据集中学习的预训练空间层。这使我们能够将训练工作集中在完善时间层上。
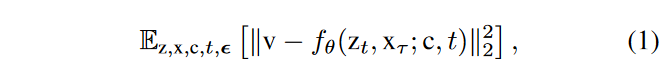
值得注意的是,本文采用v-prediction perameterization,即训练U-Net降噪器 \(\textcolor{blue}{f_\theta}\) 对\(\textcolor{blue}{v_t ≡ \alpha_t \epsilon - \sigma_t x}\) 进行预测。
微调Temporal VAE-Decoder:即使在对视频数据的U-Net进行微调后,LDM框架中的VAE解码器(仅针对图像进行训练)在解码潜在序列时仍然倾向于产生闪烁的伪影。为了缓解这个问题,作者在VAE解码器中引入了额外的时间3D残差块,以增强低级一致性。此外,U-Net中的扩散去噪过程经常会出现颜色偏移,这是其他基于扩散的恢复网络也遇到的问题。为了解决这个问题,作者利用空间特征变换(SFT)层对输入视频进行调理,该层利用输入来改换VAE解码器第一层的特征。这允许输入视频提供低频信息,例如颜色,以增强输出结果的色彩保真度。
与时间 U-Net 的训练类似,保持预训练的空间层不变,只训练新添加的时态层。这些时间层使用由L1 损失、LPIPS 感知损失 和采用时间 PatchGAN 鉴别器的对抗性损失组成的混合损失在视频数据上进行训练。
2.跨视频段的全局一致性
LDM 中经过训练的时间层仅限于处理局部序列(例如,在UNet 设置中为 8 帧),因此无法在视频片段之间实施全局一致性约束。先前的研究已经展示了流引导的长期传播在增强视频恢复任务的时间一致性方面的优势。但其性能的提升通常在处理提供长期信息的长视频序列时才能观察到。不幸的是,由于内存限制,这些方法并不适合扩散模型,这通常会限制它们处理短视频剪辑
无需训练的循环潜在传播:在潜在空间内引入了一种免训练的流动引导的递归传播模块。该模块可确保长输入视频的全局时间相干性,包括向前和向后方向的双向传播。在这里,详细阐述了前向传播,而后向传播遵循相同的过程。
给定一个低分辨率的输入视频,首先采用RAFT来估计光流,其分辨率与潜在分辨率完全匹配,因此无需调整大小。然后,通过评估前向-后向一致性误差来检查估计光流的有效性
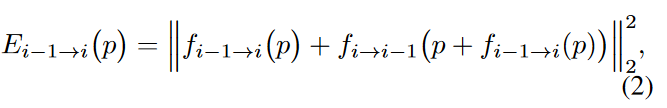
其中 \(\textcolor{blue}{p}\) 表示最后一帧潜在的位置,\(\textcolor{blue}{f_{i−1→i}}\) 和 \(\textcolor{blue}{f_{i→i-1}}\)分别是正向和反向流动。如图 3 所示,只有一致性误差小的潜在才会被传播,这可以被认为是一个遮挡掩码。
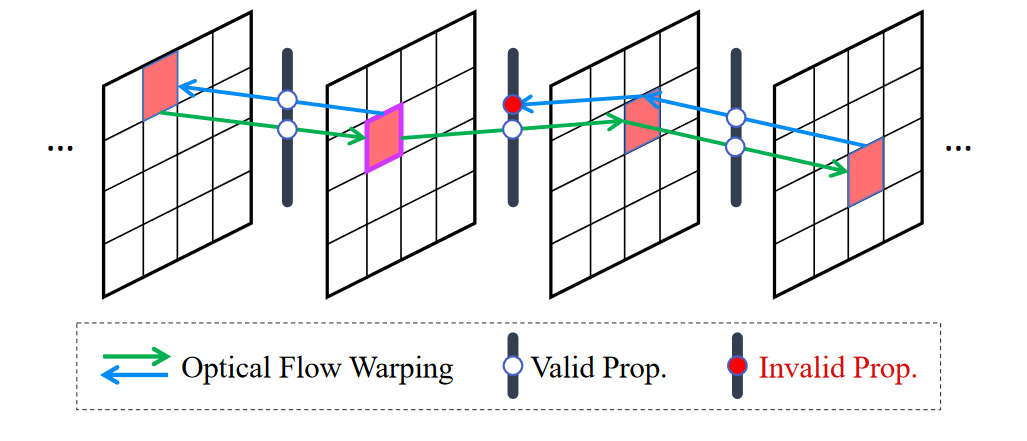
图3:流引导的循环潜在传播的图示。无需任何学习,该模块可以通过长期的潜在传播和聚合实现跨视频片段的一致性。它依赖于由前向-后向一致性误差确定的光流有效性。只有一致性误差低的潜在位置才会传播,而那些误差大(用红点标记)的位置则不会传播。
\(\textcolor{blue}{M:E_{i−1→i}(p) < δ}\),其中\(\textcolor{blue}{δ}\) 是一个阈值。设 \(\textcolor{blue}{z_i}\) 为扩散步骤 \(\textcolor{blue}{t}\) 处第 \(\textcolor{blue}{i}\) 帧的潜在特征,将预测的\(\textcolor{blue}{\hat{z}_0}\) 更新为 \(\textcolor{blue}{\tilde{\hat{z}_0}}\) 循环潜在传播和融合的过程表示为:
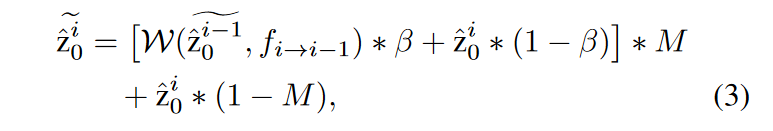
其中\(\textcolor{blue}{W(·)}\)表示扭曲操作(具有最接近的模式),\(\textcolor{blue}{β ∈[0,1]}\)用作融合权重,用于融合从前一帧\(\textcolor{blue}{(i−1)}\)到当前第\(\textcolor{blue}{i}\)帧的扭曲潜在,其中较小的值倾向于保留当前信息,而较大的值则有利于传播的信息。默认情况下,\(\textcolor{blue}{β}\) 设置为 0.5。
在推理过程中,无需在每个扩散步骤中应用此模块。相反,可以选择 \(\textcolor{blue}{T^∗}\)步骤进行潜在传播和融合。在处理轻微的视频抖动时,可以选择在扩散去噪过程的早期集成此模块,而对于严重的视频抖动,例如 AIGC 视频,最好在去噪过程的后期执行此模块。
3.附加条件的推理
作者进一步调整 Upscale-A-Video 中文本提示的附加条件和噪声级别,以影响扩散去噪过程。文本提示可以指导纹理细节的生成,例如动物皮毛或油画笔触。此外,调整噪声水平能够平衡模型的恢复和生成能力,较小的值有利于恢复,较大的值促进更多细节的生成(见图7中的比较)。作者还在推理过程中采用无分类器指导(CFG),这可以显著增强文本提示和噪声水平的影响,有助于生成具有更精细细节的高质量视频。
三、实验
1.数据集和训练细节
训练数据集:作者使用以下数据集来训Upscale-A-Video:1) WebVid10M 的子集包含大约 335K 个视频文本对,每个分辨率约为 336×596,通常用于训练视频扩散模型; 2)YouHQ数据集。由于缺乏用于训练的高质量视频数据,作者额外从 YouTube 收集了一个大规模高清 (1080 × 1920) 数据集,其中包含大约 37K 的视频剪辑,具有多种场景,即街景、景观、动物、人脸、静态物体、水下和夜间场景。对这种高质量数据进行训练进一步增强了该模型在真实世界 VSR 中的生成能力。按照RealBasicVSR的降级通道,生成用于训练的LQ-HQ视频对。
测试数据集:对于合成测试数据集,作者构建了四个合成数据集(即SPMCS、UDM10、REDS30 和 YouHQ40),它们在训练中遵循相同的降解通道来生成相应的LQ视频。作者将 YouHQ40 测试集从上面提到的 YouHQ 数据集中分离出来,其中包含 40 个视频。此外,作者还在真实世界数据集(即 VideoLQ)和 AIGC 数据集(名为 AIGC30)上评估了这些模型,该数据集通过目前流行的文本到视频生成模型收集了 30 个 AI 生成的视频。
Training Details:Upscale-A-Video 在 32 个 NVIDIA A100-80G GPU 上进行训练,批量大小为 384 个。训练数据裁剪为 80 × 80,长度为 8。使用 Adam 优化器将学习率设置为 1 × 10−4。作者首先在 WebVid10M 和 YouHQ 上训练 U-Net 模型进行 70K 次迭代。然后,仅在 YouHQ 上训练另外 10K 次迭代。由于 YouHQ 没有文本提示,因此在训练期间使用 null 提示。通过这种方式,该模型可以处理具有 LQ 输入和提示的 VSR,也可以处理仅使用 LQ 输入的 VSR,从而在实践中使用更加灵活。在VAE-Decoder微调方面,作者遵循StableSR 方法,首先在WebVid10M 和YouHQ上生成100K合成的LQ-HQ视频对,并采用微调后的U-Net模型生成对应的LQ视频潜码。
评估指标:本文采用不同的指标来评估帧质量以及生成结果的时间一致性。对于具有LQ-HQ对的合成数据集,我们采用PSNR、SSIM、LPIPS 和流动扭曲误差 \(\textcolor{blue}{E^∗_{warp}}\)进行评估。对于真实世界和AIGC测试数据,由于没有可用的真实的实况视频,根据常用的非参考指标进行评估,即CLIP-IQA、MUSIQ 和DOVER 。
2.实验对比
为了验证该方法的有效性,将Upscale-A-Video与几种最先进的方法进行了比较,包括Real-ESRGAN、SD ×4 Upscaler、ResShift、StableSR、RealVSR、DBVSR 和RealBasicVSR 。
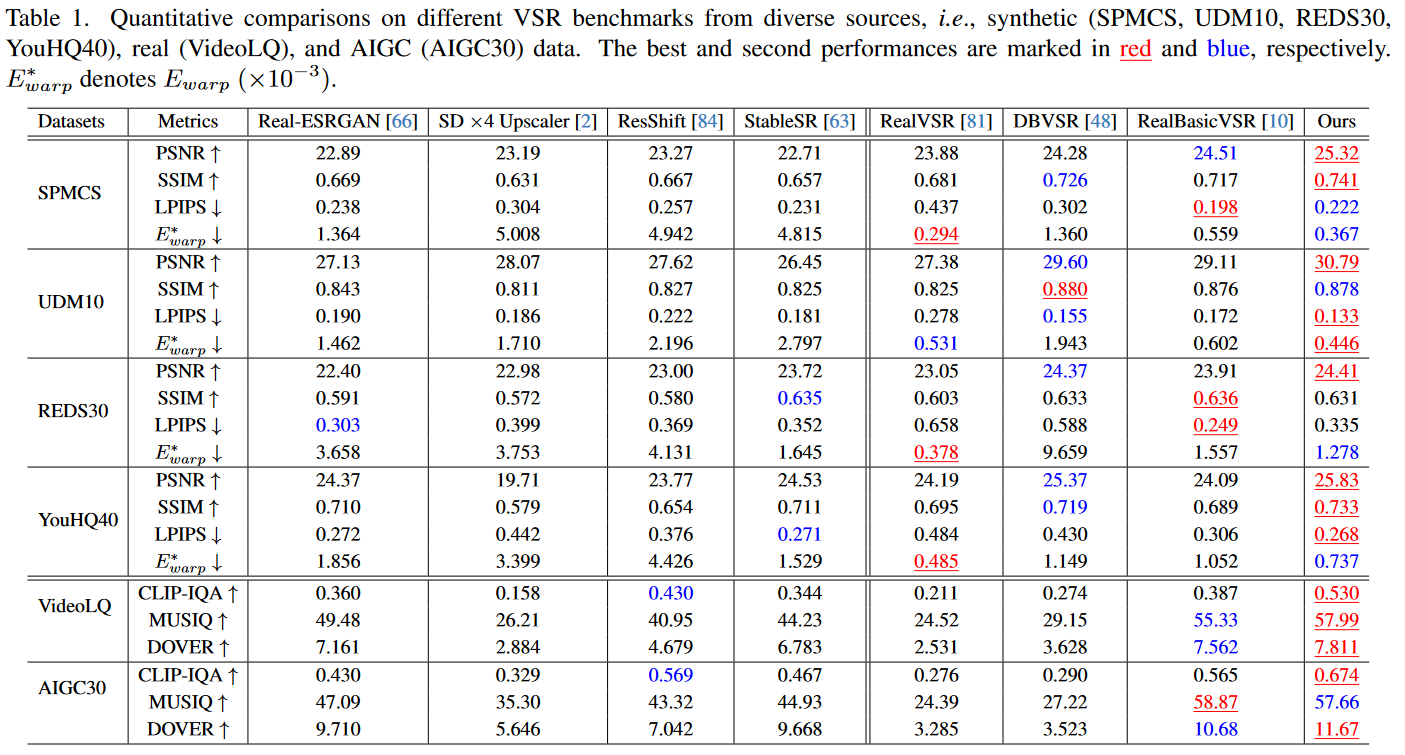
定量评估。如表1所示,Upscale-A-Video在所有四个合成数据集上都实现了最高的PSNR,表明其出色的重建能力。此外,在 UDM10 和 YouHQ40 上都获得了最低的 LPIPS 分数,表明Upscale-A-Video生成的结果具有很高的感知质量。除了在综合基准测试中表现出色外,Upscale-A-Video在真实数据集和AIGC视频上都获得了最高的CLIP-IQA和DOVER分数。
定性评估:作者分别在图 4 和图 5 中展示了合成和真实世界视频的视觉结果。据观察,Upscale-A-Video在伪影去除和细节生成方面都明显优于现有的基于CNN和扩散的方法。具体来说,与图4中的其他方法相比,Upscale-A-Video能够生成更多自然的考拉的细节,并成功恢复了图5中第一个示例中广告牌上的“EAT IN或TAKEAWAY”字样,而其他方法则产生模糊或扭曲的结果。请注意,SD ×4 Upscaler 对真实世界的 VSR 效果较差,因为它在其训练数据中不考虑混合退化。

图4:对来自 REDS30和 YouHQ40 数据集的合成低质量视频进行定性比较。在经过测试的方法中,只有Upscale-A-Video可以恢复准确的墙体结构并产生详细的考拉的皮毛特征。

图5:对 VideoLQ 数据集中真实世界测试视频的定性比较。我们的 Upscale-A-Video 有效地利用了扩散范式的优势来生成高质量的结果。与现有方法相比,它在恢复能力方面明显表现出色,成功恢复了广告牌上的“EAT IN or TAKEAWAY”字样。特别是,在文本提示的指导下,Upscale-A-Video 展示了有望通过更多细节和高度真实感获得增强的结果。
时间一致性:得益于局部-全局时间策略,Upscale-A-Video在UDM10上取得了最好的光流误差分数,在REDS30、SPMCS和YouHQ40上取得了第二好的分数,明显优于其他基于扩散的方法,甚至击败了强大的基于CNN的VSR方法,即RealBasicVSR和DBVSR。在图 6 中可视化了时间分布。据观察,本文的方法通过更无缝、更平滑的过渡实现了卓越的性能。

图6:时间剖面图的比较。随机挑选一行并跟踪随时间的变化。现有方法和Exp.(a)和(c)(不带潜在传播模块)的剖面显示噪声,表明存在闪烁伪影。即使使用微调的解码器,Exp.(c)仍然显示出一些不连续性。由于长期的潜在传播和聚合, UpscaleA-Video 的生成结果表现出更无缝、更平滑的过渡。
3.消融实验
微调VAE解码器的有效性:首先研究了微调VAE-Decoder的有效性。如表 2 所示,用原始解码器替换微调的 VAE 解码器会导致 PSNR、SSIM 和 \(\textcolor{blue}{E^∗_{warp}}\) 变差。特别是,\(\textcolor{blue}{E^∗_{warp}}\)从 0.737 增加到 1.815 表明时间相干性显着恶化。图6中的比较还表明,如果没有微调的VAE解码器,时间一致性较差。
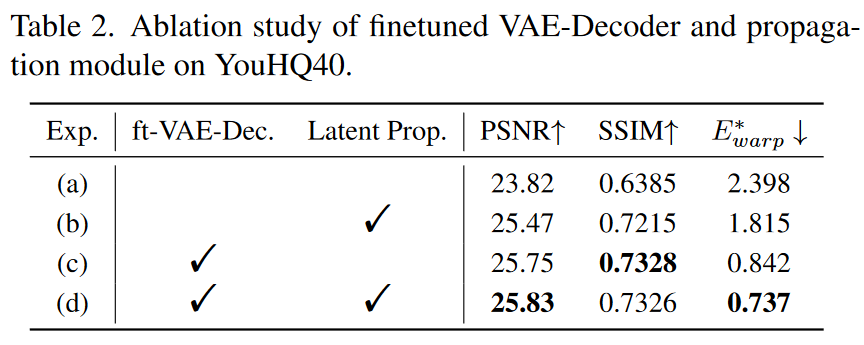
传播模块的有效性:除了对VAE-Decoder进行微调外,作者提出的光流引导循环潜传播模块进一步增强了长视频的稳定性。如表2所示,采用传播模块可以进一步减少\(\textcolor{blue}{E^∗_{warp}}\)误差,在保持高PSNR的同时有效提高时间一致性。在图6中的时间剖面中也可以观察到类似的现象,显示出更无缝的过渡。传播模块的有效性。除了对VAE-Decoder进行微调外,我们提出的流导循环潜传播模块进一步增强了长视频的稳定性。如表2所示,采用传播模块可以进一步减少\(\textcolor{blue}{E^∗_{warp}}\)误差,在保持高PSNR的同时有效提高时间一致性。在图6中的时间剖面中也可以观察到类似的现象,显示出更无缝的过渡。
文本提示:Upscale-A-Video 在视频数据上进行训练,其中包含标记的提示或空提示,因此可以处理这两种情况。我们研究了使用无分类器指导来提高采样过程中的视觉质量。如图 7 所示,与空提示相比,采用适当的文本提示可以显著提高感知质量,细节更真实。

图7:比较文本提示的各种条件和不同程度的噪声
噪声水平:据观察,添加到输入端的噪声水平会影响该方法的性能。如图 7 所示,在低噪声水平下,生成的结果往往不理想,细节模糊。但是,过大的噪声水平可能会导致过度锐化。
四、总结
虽然扩散模型在各种图像任务上都取得了令人印象深刻的性能,但它们在视频任务中的应用,尤其是真实世界的VSR,仍然具有挑战性且研究不足。在本文中,作者提出了UpscaleA-Video,这是一种利用先验图像扩散进行真实世界VSR的新方法,同时避免了采样过程中固有的随机性所导致的时间不连续性。具体来说,通过在潜在扩散框架内提出一种新的局部-全局时间策略来增强时间一致性。此外,作者还致力于通过文本提示和噪声级别控制创建纹理来实现保真度和质量之间的权衡,进一步促进了在真实场景中的实际使用。