

一、引言
在这项研究中,本文提出了 StableSR,这是一种保留预训练扩散先验的方法,而不对退化做出明确的假设。具体来说,与以前需要将 低分辨率的LR 图像连接到中间输出的工作(这需要从头开始训练扩散模型)不同,本文的方法只需要微调一个轻量级的时间感知编码器(lightweight time-aware encoder)和一些特征调制层(feature modulation layers)即可完成 SR 任务。编码器包含一个时间嵌入层来生成时间感知特征,允许扩散模型中的特征在不同的迭代中自适应调制。除了提高训练效率外,保持原始扩散模型的冻结还有助于保留生成先验。时间感知编码器还通过在恢复过程中为每个扩散步骤提供自适应指导来帮助保持保真度,即在早期迭代时提供更强的指导,在以后提供较弱的指导。实验表明,这种时间感知特性对于实现性能改进至关重要。
为了抑制从扩散模型继承的随机性以及由于自动编码器编码过程导致的信息丢失,受Codeformer的启发,本文应用了一个具有可调系数的可控特征包装模块,在自动编码器的解码过程中细化扩散模型的输出。具体而言,采用来自编码器的多尺度中间特征,以残差方式调整解码器特征。通过可调节系数来控制残余强度,这样可以进一步实现连续的保真度和真实感权衡,以处理轻度和重度退化。
将扩散模型应用于任意分辨率仍然是一个持续的挑战。一个简单的解决方案是将图像拆分为多个补丁并独立处理每个补丁。但是,这种方法通常会导致输出中的边界不连续性。为了解决这个问题,作者引入了一种渐进式聚合抽样策略。该方法是将图像划分为重叠的块,并在每次扩散迭代中使用高斯核融合这些块。这个过程使边界变得平滑,从而产生更连贯的输出。
将生成先验调整为真实世界的图像超分辨率提出了一个有趣但具有挑战性的问题,在这项工作中,本文提供了一种新颖的方法作为解决方案。并引入了一种微调方法,该方法利用预先训练的扩散模型,而无需对退化做出明确的假设。通过提出简单而有效的模块来解决关键挑战,例如保真度和任意分辨率。凭借作者提出的时间感知编码器、可控的特征包装模块和渐进式聚合采样策略, StableSR 可以作为强大的基线,激发未来在恢复任务中采用扩散先验的研究。
二、方法
受 Stable Diffusion 的生成能力的启发,本文在工作中将其用作扩散先验,因此该方法命名为 StableSR。StableSR 的主要组件是一个时间感知编码器,它与冻结的 Stable Diffusion 模型一起训练,以允许根据输入图像进行调节。为了进一步促进真实感和保真度之间的权衡,根据用户的偏好,遵循CodeFormer引入了可选的可控功能包装模块。StableSR的整体框架如图2所示:
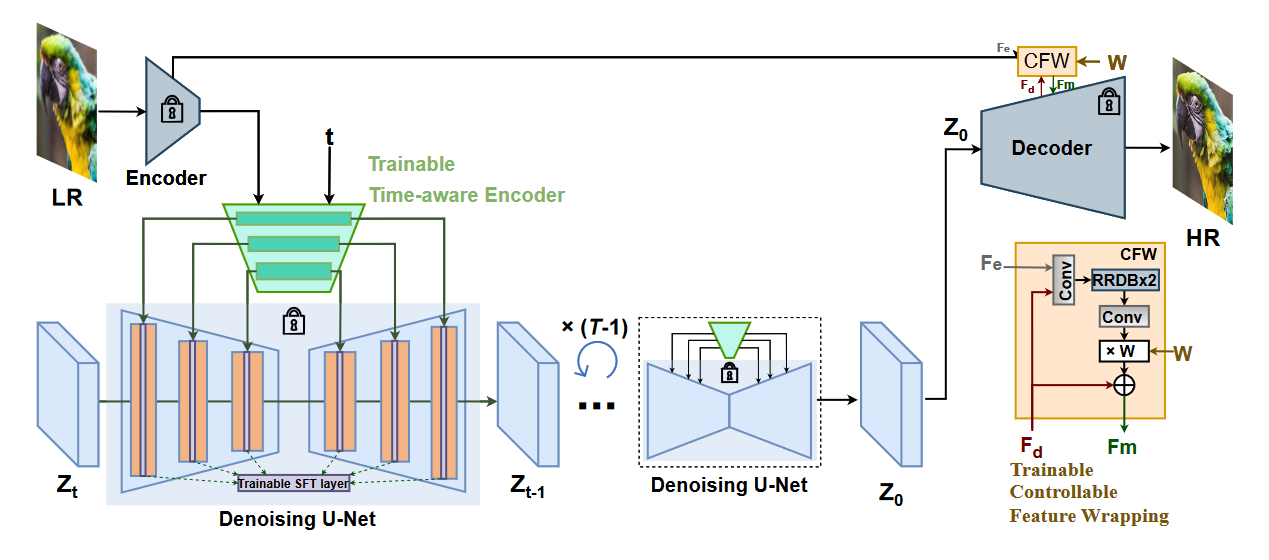
图2:StableSR 框架:首先对时间感知编码器进行微调,该编码器连接到固定的预训练稳定扩散模型。特征与可训练的空间要素变换 (SFT) 图层相结合。这种简单而有效的设计能够利用图像SR的丰富扩散。然后,扩散模型是固定的。受CodeFormer的启发,作者还引入了一个可控特征包装(CFW)模块,以残差方式获得调整后的特征\(F_m\),给定来自LR特征的附加信息\(F_e\)和来自固定解码器的特征\(F_d\)。通过可调节的系数 \(w\),CFW 可以在质量和保真度之间进行权衡。
1.使用时间感知进行引导式微调
为了利用 SR 稳定扩散的先验知识,我们在设计模型时建立了以下约束:1) 生成的模型必须能够生成合理的 HR 图像,条件是观察到的 LR 输入。这一点至关重要,因为LR图像是结构信息的唯一来源,这对于保持高保真度至关重要。2)该模型应仅对原始稳定扩散模型进行最小的改动,以防止破坏封装在其中的先前模型。
特征调制:虽然现有方法通过交叉注意力成功地控制了扩散模型生成的语义结构,由于归纳偏差不足,这种策略很难提供详细和高频的指导。为了更准确地指导生成过程,作者采用了一个额外的编码器,从退化的LR图像特征中提取多尺度特征 \(\textcolor{blue}{\{F^n\}_{n=1}^N}\),并使用它们通过空间特征变换(SFT)调制稳定扩散中residual blocks的中间特征图 \(\textcolor{blue}{\{F^n_{diff}\}_{n=1}^N}\):
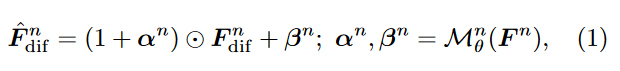
其中 \(\textcolor{blue}{α_n}\) 和 \(\textcolor{blue}{β_n}\) 表示 SFT 中的仿射参数,\(\textcolor{blue}{M^n_θ}\) 表示由多个卷积层组成的小网络。这里 \(\textcolor{blue}{n}\) 索引了 Stable Diffusion 中 UNet 架构的空间尺度。
在微调期间,作者冻结了 Stable Diffusion 的权重,并仅训练编码器和 SFT 层。这种策略允许我们插入从 LR 图像中提取的结构信息,而不会破坏 Stable Diffusion 捕获的生成先验。
时间感知指导:作者发现,通过编码器中的时间嵌入层合并时间信息可以大大提高生成质量和对真实情况的保真度,因为它可以自适应地调整从LR特征得出的条件强度。在这里,从信噪比(SNR)的角度分析了这种现象,然后在消融研究中对其进行了定量和定性验证。
在生成过程中,生成图像的SNR会随着噪声的逐渐消除而逐渐增加。最近的一项研究表明,当 SNR 接近 5e−2 时,图像内容会迅速填充。根据这一观察结果,作者提出的编码器旨在为信噪比达到5e−2的扩散模型提供较强的条件。这是必不可少的,因为在此阶段生成的内容会显着影响我们方法的超分辨率性能。为了进一步证实这一点,作者利用 SFT 前后 Stable Diffusion 特征之间的余弦相似性来测量编码器提供的条件强度。不同时间步长的余弦相似度值如图3a)所示。可以看出,余弦相似度在5e−2的信噪比(SNR)附近达到最小值,表明编码器施加的最强条件。此外,作者还描绘了从图 3b) 中专门设计的编码器中提取的特征图。值得注意的是,5e−2的SNR点周围的特征更加清晰,并且包含更详细的图像结构。因此假设这些自适应特征条件可以为 SR 提供更全面的指导。
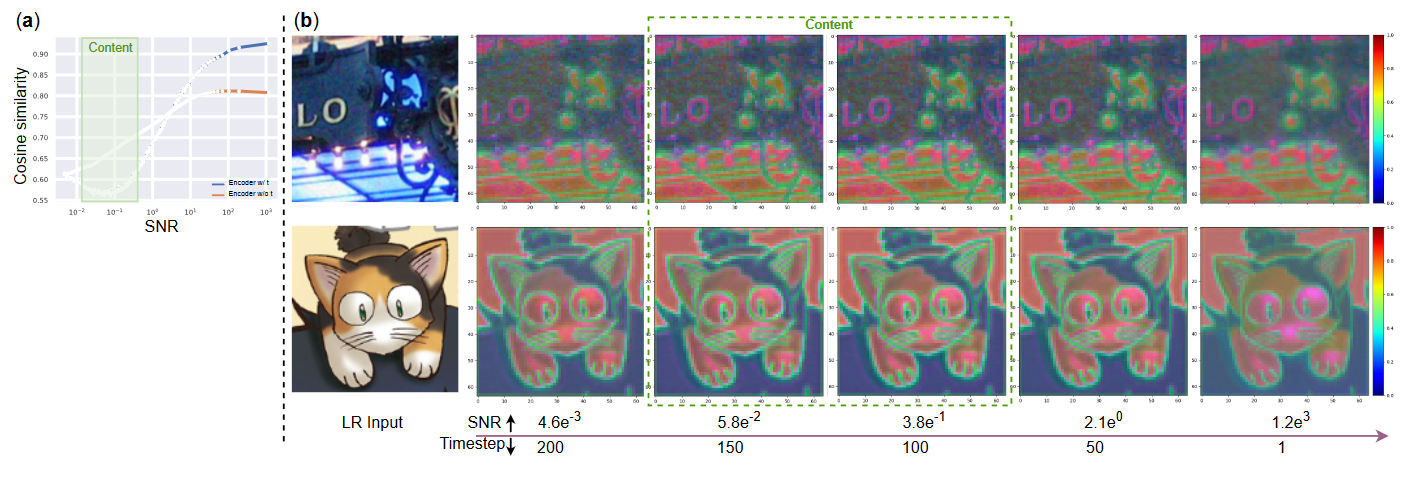
图3:与没有时间嵌入的条件编码器相比,配备时间嵌入的编码器可以自适应地为预训练的扩散模型提供指导。图(a):测量了扩散模型在SFT前后特征在不同时间步长之间的余弦相似性,这与源自编码器的条件强度相呼应。图(b):进一步可视化了从LR图像中提取的条件编码器的特征。如图所示,当 SNR 徘徊在 5e−2 附近时,编码器倾向于提供清晰的特征。这正是扩散模型需要大量指导才能生成所需的高分辨率图像内容的时候。
色彩校正:扩散模型偶尔会表现出颜色偏移。为了解决这个问题,作者对生成的图像进行颜色归一化,以使其均值和方差与 LR 输入的均值和方差保持一致。特别的,让 \(\textcolor{blue}{x}\) 表示 LR 输入,\(\textcolor{blue}{\hat{y}}\) 表示生成的 HR 图像,则颜色校正后的输出 \(\textcolor{blue}{y}\) 计算如下:
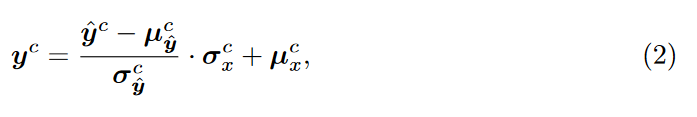
其中\(\textcolor{blue}{c \in \{r,g,b\}}\)表示颜色通道,\(\textcolor{blue}{μ^c_{\hat{y}}}\) 和 \(\textcolor{blue}{σ^c_{\hat{y}}}\)(或 \(\textcolor{blue}{μ^c_x}\) 和 \(\textcolor{blue}{σ^c_x}\))分别是从 \(\textcolor{blue}{\hat{y}}\)(或 \(\textcolor{blue}{x}\))的第 \(\textcolor{blue}{c}\) 个通道估计的平均值和标准方差。这种简单的校正足以弥补色差。
除了在像素域中采用色彩校正外,作者还提出了基于小波的色彩校正,以获得更好的视觉性能。给定任何图像 \(\textcolor{blue}{I}\),作者通过小波分解在第\(\textcolor{blue}{i}\) 个 (\(\textcolor{blue}{1 ≤ i ≤ l}\)) 尺度上提取其图像的高频分量 \(\textcolor{blue}{H^i}\) 和低频分量 \(\textcolor{blue}{L^i}\),即
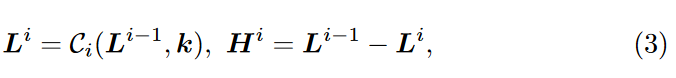
其中 \(\textcolor{blue}{L^0 = I}\),\(\textcolor{blue}{C_i}\) 表示膨胀为 \(\textcolor{blue}{2_i}\) 的卷积算子,\(\textcolor{blue}{k}\) 是卷积核定义为:
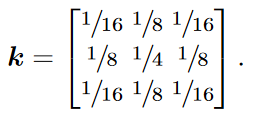
通过将 \(\textcolor{blue}{x}\)(或 \(\textcolor{blue}{\hat{y}}\))的第 \(\textcolor{blue}{l}\) 个低频和高频分量表示为 \(\textcolor{blue}{L^l_x}\) 和 \(\textcolor{blue}{H^l_x}\)或( \(\textcolor{blue}{L^l_y}\) 和 \(\textcolor{blue}{H^l_y}\)),所需的 HR 输出 \(\textcolor{blue}{y}\) 公式如下:

直观地说,就是用 \(\textcolor{blue}{L^l_x}\) 替换了 \(\textcolor{blue}{\hat{y}}\) 的低频分量 \(\textcolor{blue}{L^l_y}\) 来校正颜色偏差。默认情况下,为了简单起见,作者在像素域中采用色彩校正。
2.保真与现实主义的权衡
尽管所提出的方法的输出在视觉上令人信服,但由于扩散模型固有的随机性,它经常偏离基本事实。从CodeFormer中汲取灵感,作者引入了可控特征包装(CFW)模块,以灵活地管理真实感和保真度之间的权衡。
由于稳定扩散是在自动编码器的潜在空间中实现的,因此很自然地利用自动编码器的编码器功能来调制相应的解码器功能,以进一步提高保真度。设 \(\textcolor{blue}{F_e}\) 和 \(\textcolor{blue}{F_d}\) 分别作为编码器和解码器特征。并引入了一个可调系数 \(\textcolor{blue}{w \in [0,1]}\) 来控制调制的程度:
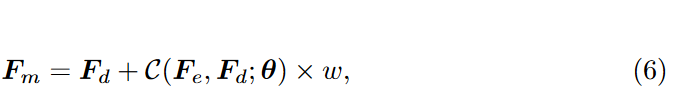
其中 \(\textcolor{blue}{C(·; θ)}\) 表示具有可训练参数 \(\textcolor{blue}{θ}\) 的卷积层。整体框架如图 2 所示。
在此设计中,小 \(\textcolor{blue}{w}\) 利用了 Stable Diffusion 的生成能力,从而产生具有高真实感的输出。相比之下,较大的 w 允许 LR 图像提供更强的结构引导,从而增强保真度。我们观察到 \(\textcolor{blue}{w = 0.5}\) 在质量和保真度之间取得了良好的平衡。请注意,作者只在这个特定阶段训练 CFW。
3.聚合采样
由于 Stable Diffusion 中注意力层相对于图像分辨率的灵敏度更高,因此对于与其训练设置不同的分辨率,它往往会产生较差的输出,特别是 512×512。这实际上限制了 StableSR 的实用性。
一种常见的解决方法是将较大的图像拆分为几个重叠的小块,并单独处理每个块。虽然这种策略通常对传统的基于CNN的SR方法产生良好的结果,但它并不直接适用于扩散范式。这是因为在扩散迭代过程中,patches之间的差异会复合并被放大。图 4 显示了一个典型的故障案例。

图4:在处理超过 512×512 的图像时,StableSR(无聚合采样)通过将图像切成多个图块、单独处理并将它们拼接在一起,从而存在明显的块不一致。通过作者提出的聚合采样,StableSR可以在大图像上获得一致的结果。图中的分辨率为1024×1024。
作者应用渐进式patch聚合采样算法来处理任意分辨率的图像。具体来说,首先将低分辨率图像编码为潜在特征图 \(\textcolor{blue}{F ∈ R^{h×w}}\),然后将其细分为 \(\textcolor{blue}{M}\) 个重叠的小斑块 \(\textcolor{blue}{\{F_{Ωn}\}_{n=1}^M}\),每个patch的分辨率为 64 × 64 - 匹配训练分辨率(Stable Diffusion 中自动编码器的下采样比例因子为 8×。)。这里,\(\textcolor{blue}{Ω_n}\) 是 \(\textcolor{blue}{F}\) 中第 \(\textcolor{blue}{n}\) 个patch的坐标集。在反向采样的每个时间步中,每个patch都通过 StableSR 单独处理,随后对处理后的patch进行汇总。为了集成重叠的patch,为每个patch \(\textcolor{blue}{F_{Ω_n}}\) 生成一个权重图 \(\textcolor{blue}{w_{Ω_n}\in R^{h \times w}}\),其条目跟随 \(\textcolor{blue}{Ω_n}\) 中的高斯滤波器,而其他地方为 0。然后根据重叠像素各自的高斯权重图进行加权。特别是,作者定义了一个填充函数 \(\textcolor{blue}{f(·)}\),它通过填充区域 \(\textcolor{blue}{Ω_n}\) 之外的零点将任何大小为 64×64 的块扩展为 h×w 的分辨率。重复此过程,直到达到最终迭代。
给定每个patche的输出为 \(\textcolor{blue}{ε_θ(Z^{(t)}_{Ω_n}, F_{Ω_n}, t)}\),其中\(\textcolor{blue}{Z^{(t)}_{Ω_n}}\) 是噪声输入 \(\textcolor{blue}{Z^{(t)}}\)的第 \(\textcolor{blue}{n}\) 个斑块,\(\textcolor{blue}{θ}\) 是扩散模型的参数,所有patches聚合在一起的结果可以公式化如下:
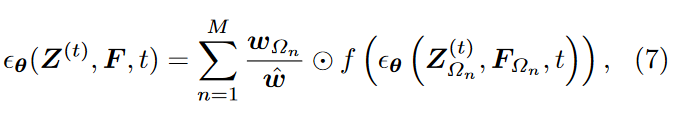
其中\(\textcolor{blue}{\hat{w}=\sum_n w_{Ω_n}}\) 。基于\(\textcolor{blue}{ε_θ(Z^{(t)}_{Ω_n}, F, t)}\)),可以根据采样程序得到\(\textcolor{blue}{Z^{(t-1)}}\),在扩散模型中表示为\(\textcolor{blue}{Sampler(Z^{(t)}, ε_θ(Z(t), F, t)}\)。随后,将 \(\textcolor{blue}{Z^{(t-1)}}\) 重新拆分为重叠的patch并重复上述步骤,直到 \(\textcolor{blue}{t=1}\)。整个过程总结在算法 1 中。实验表明,这种渐进式聚合方法大大减轻了重叠区域的差异,如图4所示。

三、实验
1.实验设置
StableSR 基于 Stable Diffusion 2.1-base 预训练模型所构建。时间感知编码器类似于稳定扩散中去噪 U-Net 的收缩路径,但更轻巧(∼105M,包括 SFT 层)。SFT层加入到Stable Diffusion的每个residual block块中,以实现有效控制。作者对 StableSR 的扩散模型进行了 117 个epoch的微调,批处理大小为 192,并将提示固定为 null。遵循 Stable Diffusion 使用 Adam 优化器,学习率设置为 5 × 10−5。训练过程以 512 × 512 分辨率和 8 个 NVIDIA Tesla 32G-V100 GPU 进行。为了进行推理,作者采用具有 200 个时间步长的 DDPM 采样。为了处理任意大小的图像,对 512×512 以外的图像采用了建议的聚合采样策略。对于低于 512×512 的图像,首先放大 LR 图像,使较短的一侧的长度为 512,并在生成后将结果重新缩放回目标分辨率。
为了训练 CFW,首先在 Real-ESRGAN 中的降解管道之后生成分辨率为 512 × 512 的 100k 合成 LR-HR 对。然后,采用微调扩散模型,以上述LR图像为条件,生成相应的潜码\(\textcolor{blue}{Z_0}\)。训练损失与 LDM 中使用的自动编码器几乎相同,只是作者使用 0.025 的固定对抗性损失权重而不是自调损失权重
训练数据集:作者采用Real-ESRGAN的降解管道在DIV2K,DIV8K,Flickr2K和OutdoorSceneTraining数据集上合成LR-HR对。作者还从 FFHQ 数据集中添加了 5000 张面部图像,用于一般情况。
测试数据集:作者在合成数据集和真实世界数据集上评估了它们的方法。对于合成数据,遵循Real-ESRGAN的退化管道,从DIV2K验证集生成3k LR-HR对。LR 的分辨率为 128 × 128,相应 HR 的分辨率为 512 × 512。请注意,对于 StableSR,在推理之前,首先将输入上采样到与输出相同的大小。对于真实世界的数据集,我们遵循通用设置对 RealSR、DRealSR和 DPED-iPhone进行比较。并进一步从互联网上收集了 40 张图片进行比较。
比较方法:为了验证我们方法的有效性,我们将我们的 StableSR 与几种最先进的方法3 进行了比较,即 RealSR4 (Ji et al., 2020)、BSRGAN (Zhang et al., 2021a)、RealESRGAN+ (Wang et al., 2021c)、DASR (Liang et al., 2022)、FeMaSR (Chen et al., 2022)、潜在扩散模型 (LDM) (Rombach et al., 2022)、SwinIR-GAN5 (Liang et al., 2021) 和 DeepFloyd IF III (Deep-floyd, 2023). 由于 LDM 是在分辨率为 256 × 256 的图像上正式训练的,因此我们按照 StableSR 的相同训练设置对其进行微调,以便进行公平的比较。对于其他方法,我们直接使用官方代码和模型进行测试。请注意,本节中的结果是在训练的相同分辨率下获得的,即 128 × 128。具体来说,对于来自(Cai et al., 2019;Wei 等人,2020 年;Ignatov 等人,2017 年),我们在中心裁剪它们以获得分辨率为 128 × 128 的补丁。对于其他真实世界的图像,我们首先调整它们的大小,使较短的边为 128,然后应用中心裁剪。至于其他分辨率,图 4 显示了 1024 × 1024 分辨率下真实世界图像上的 StableSR 示例。
评估指标:对于具有配对数据的基准测试,即 DIV2K Valid、RealSR 和 DRealSR,作者采用各种感知指标,包括 LPIPS、FID、CLIP-IQA和 MUSIQ来评估生成图像的感知质量。还报告了 PSNR 和 SSIM 分数(在 YCbCr 色彩空间的亮度通道上评估)以供参考。由于 DPED-iPhone 中无法获得地面实况图像,遵循现有方法报告无参考指标的结果,即用于感知质量评估的 CLIP-IQA 和 MUSIQ。此外,作者还对 16 张真实世界的图像进行了用户研究,以验证它们的方法相对于现有方法的有效性。