
一、引言
基于扩散的模型可以通过文本提示生成多样化的高质量图像和视频。它还带来了从这些生成先验中编辑真实世界视觉内容的巨大机会。
为了编辑真实图像,可以利用确定性DDIM进行图像噪声inversion,然后,反转噪声在目标提示的条件下逐渐生成编辑后的图像。基于这个线路,在交叉注意力引导、即插即用功能和优化方面提出了几种方法。
通过生成先验作为上述图像编辑方法处理视频存在许多挑战。首先,没有公开的通用文本到视频模型。因此,基于图像模型的框架可能比基于视频模型的框架更有价值,这要归功于社区中的各种开源图像模型。然而,文本到图像模型缺乏对时间感知信息的考虑,例如运动和3D形状理解。将图像编辑方法直接应用于视频将显示正面闪烁。其次,虽然可以通过关键帧或图集编辑使用以前的视频编辑方法,但这些方法仍然需要图集学习,关键帧选择和每个提示的调整。此外,虽然它们在属性和样式编辑方面可能效果很好,但形状编辑仍然是一个巨大的挑战 。最后,如上所述,当前的编辑方法使用 DDIM 进行反转,然后通过新提示进行降噪。然而,在视频反演中,\(\textcolor{blue}{T}\)步进的反转噪声可能会因为误差累积而破坏原始视频的运动和结构。
在本文中,作者提出了FateZero,这是一种简单而有效的零镜头视频编辑方法,因为我们不需要针对每个目标提示单独训练,也没有用户特定的mask。与图像编辑不同,视频编辑需要保持编辑视频的时间一致性,这是原始训练的文本到图像模型无法学习的。本文通过使用两种新颖的设计来解决这个问题。首先,不是仅仅依靠反转和生成,而是采用不同的方法,在反转过程的每一步都存储所有的自我和交叉注意力图。这使得能够随后在 DDIM 的去噪步骤中替换它们。具体来说,作者发现这些自注意力块存储了更好的运动信息,交叉注意力可以用作空间上自我注意力混合的阈值掩码。这种注意力混合操作可以保持原始结构不变。此外,作者将自我注意力块改革为时空注意力块,以使外观更加一致。并且该框架支持使用预先训练的文本到图像模型直接编辑真实世界视频的样式和属性。此外,在获得视频扩散模型后,该方法在测试时显示出比简单的DDIM反演更好的对象编辑能力。大量的实验证明了所提出的方法在视频和图像编辑方面的优势。
二、方法
1.预备知识
DDIM inversion:在推理过程中,采用确定性DDIM采样将随机噪声\(\textcolor{blue}{z_T}\)转换为干净的潜在\(\textcolor{blue}{z_0}\),其时间步长为\(\textcolor{blue}{t:T→1}\):
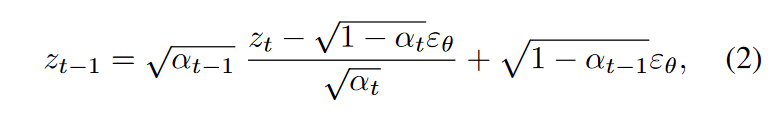
其中\(\textcolor{blue}{\alpha_t}\)是噪声 scheduling的参数。
基于扩散过程的常微分方程极限分析,提出DDIM inversion,以\(\textcolor{blue}{t:T→1}\)的步长将干净的潜在\(\textcolor{blue}{z_0}\)映射回噪声潜在\(\textcolor{blue}{\hat{z}_T}\):
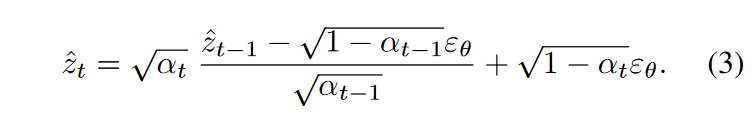
使得倒置的潜在 \(\textcolor{blue}{\hat{z}_T}\) 可以重建一个潜在 \(\textcolor{blue}{\hat{z}_0(p_{src})= DDIM(\hat{z}_T,p_{src})}\) ,类似于无分类器指导尺度 \(\textcolor{blue}{s_{cfg} = 1}\) 的干净潜在 \(\textcolor{blue}{z_0}\)。最近,图像编辑方法使用一个较大的无分类器指导尺度\(\textcolor{blue}{s_{cfg} ≫ 1}\)将潜在变量编辑为\(\textcolor{blue}{\hat{z}_0(p_{edit})= DDIM(\hat{z}_T,p_{edit})}\) (图3(a)中的第二行),其中并行进行\(\textcolor{blue}{\hat{z}_0(p_{src})}\)的重建以提供注意力约束。(图3(a)中的第一行)。
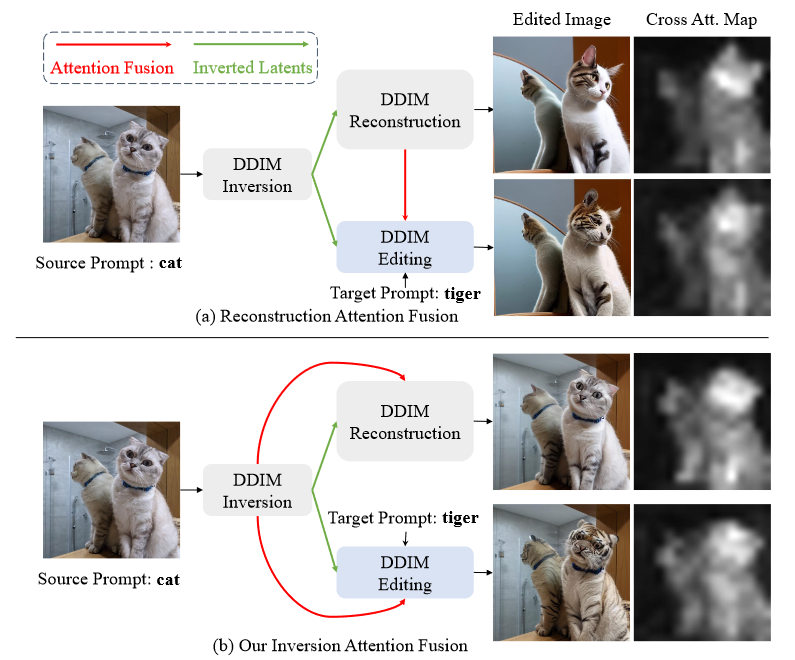
图3:使用稳定扩散的零样本局部属性编辑(猫→老虎)。与之前中工作中的Reconstruction Attention Fusion(a)相比,本文的Inversion Attention Fusion(b)提供了更准确的结构指导和编辑能力,如右侧所示。
2.FateZero视频编辑
如图 2 所示,作者使用预训练的文本到图像模型(即 Stable Diffusion)作为基础模型,其中包含一个用于 \(\textcolor{blue}{T}\) 时间步长去噪的 UNet。本文没有直接利用以重建注意力为指导的潜在编辑的常规管道,而是对视频编辑进行了以下几项关键修改。
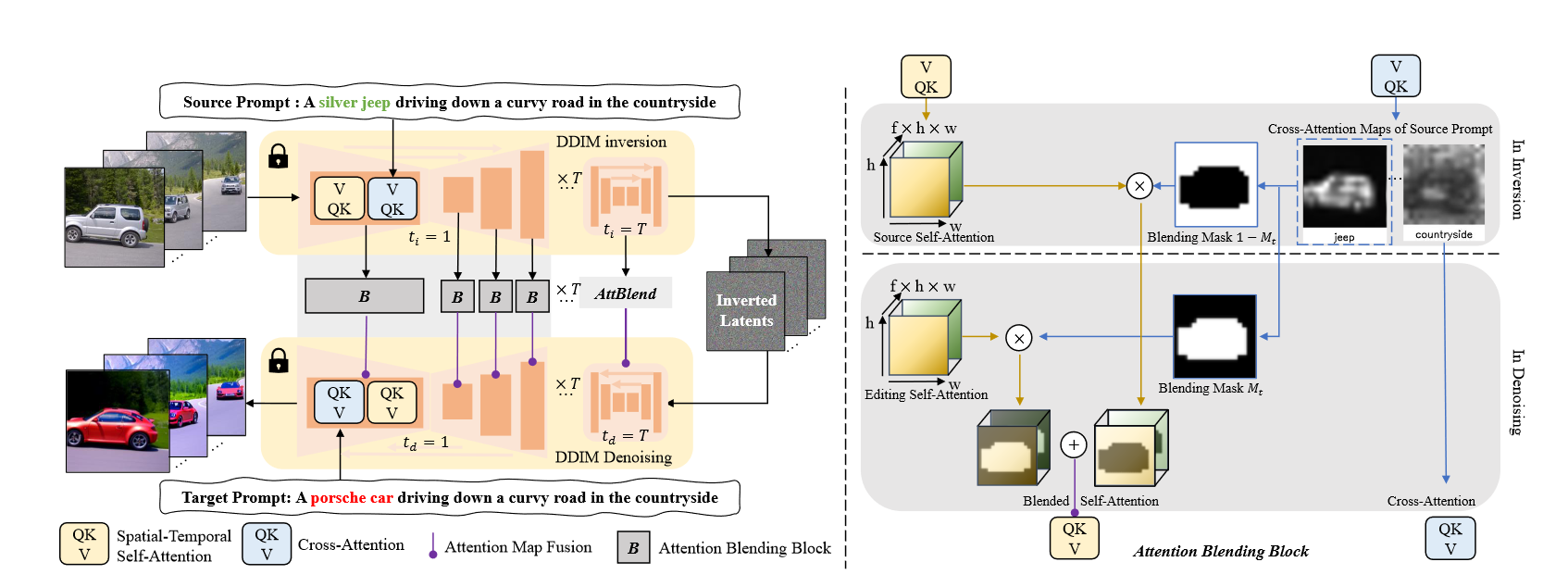
图2:方法的概述:输入是用户提供的源提示 \(p_{src}\)、目标提示 \(p_{edit}\) 和干净的潜在 \(z = {z^1,z^2,...,z^n}\) 由具有数字帧 \(n\)的视频序列中的输入源视频\(x = {x^1,x^2,...,x^n}\)编码所获得的。在左边,首先使用DDIM inversion 通道将视频反转为噪声潜在\(z_T\),使用源提示\(p_{src}\)和膨胀的3D U-Net \(ε_θ\)。在每个inversion 时间步长 \(t\) 期间,存储时空自我注意力映射 \(s^{src}_t\) 和交叉注意力映射 \(c^{src}_t\) 。在DDIM denoising的编辑阶段,将潜在\(z_T\)降噪回干净的图像\(\hat{z}_0\),条件是目标提示。在每个去噪时间步长\(t\),使用所提出的Attention Blending Block将\(ε_θ\)中的注意力图\((s^{edit}_t, c^{edit}_t)\)与存储的注意力图\((s^{src}_t,c^{src}_t)\)融合在一起。右图:具体来说,将未编辑的单词(例如,道路和乡村)的交叉注意力图 \(c^{edit}_t\) 替换为它们的源交叉注意力图 \(c^{src}_t\)。此外,将反转 \(s^{src}_t\) 和编辑 \(s^{edit}_t\) 期间的自注意力映射与从交叉注意力 \(c^{src}_t\) 获得的自适应空间掩码混合在一起,该掩码表示用户想要编辑的区域。
1️⃣Inversion Attention Fusion:使用反转噪声(inverted noise)进行直接编辑会导致帧不一致,这可能归因于两个因素。首先,式(2)和式(3)中讨论的DDIM的可逆性质只在小步长的极限内成立。然而,目前对 50 个 DDIM 去噪步骤的要求会导致每个后续步骤的错误累积。其次,使用大型无分类器引导 \(\textcolor{blue}{s_{cfg} ≫ 1}\) 可以提高去噪的编辑能力,但较大的编辑自由度会导致相邻帧不一致。因此,以前的方法需要优化文本嵌入或其他正则化。
虽然这些问题在单帧编辑的上下文中看起来微不足道,但在处理视频时它们可能会被放大,因为即使是帧之间的微小差异也会沿着时间索引加重。
为了缓解这些问题,本文的框架在Inversion步骤(方程(3))中使用了注意力图,因为在Inversion期间向UNet提供了源提示\(\textcolor{blue}{p_{src}}\)和初始潜在 \(\textcolor{blue}{z_0}\)。形式上,在Inversion过程中,存储每个时间步长 \(\textcolor{blue}{t}\) 的中间自注意力映射(self-attention maps) \(\textcolor{blue}{[s^{src}_t]^T_{t=1}}\)、交叉注意力映射(cross-attention maps) \(\textcolor{blue}{[c^{src}_t]^T_{t=1}}\),最终的潜在特征映射 \(\textcolor{blue}{z_T}\) 为
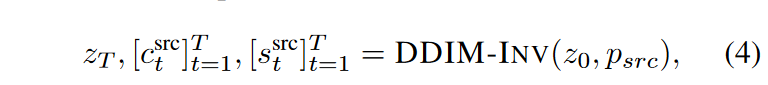
其中,DDIM-INV代表式(3)中讨论的DDIM Inversion 通道。在编辑阶段,我们可以通过融合反转的注意力来获得要去除的噪声:
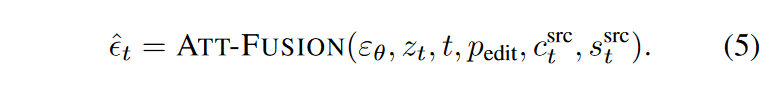
其中 \(\textcolor{blue}{p_{edit}}\) 表示修改后的提示。在函数 ATT-FUSION 中,注入提示中未更改部分的交叉注意力映射,类似于 Prompt-to-Prompt。此外,还替换了自注意力图,以在样式和属性编辑过程中保留原始结构和运动。
图3显示了本文的注意力融合方法与图像编辑中简单反转然后生成的典型方法之间的简单数据集的比较示例。在Inversion 过程中的交叉注意力图捕捉了源图像中猫的轮廓和姿势,但重建过程中的图有明显的差异。在视频中,注意力一致性可能会影响时间一致性,如图 8 所示。这是因为时空自注意力图代表了帧之间的对应关系,而现有视频扩散模型的时间建模能力并不令人满意。
2️⃣Attention Map Blending:反演时间注意力融合在局部损耗编辑中可能不足,如图 4 中的图像示例所示。在第三列中,用 \(\textcolor{blue}{s^{src}}\) 替换 \(\textcolor{blue}{s^{edit}∈R^{hw×hw}}\)自注意力编辑会带来不必要的结构泄漏,并且生成的图像在可视化中具有令人不快的混合伪影。另一方面,如果我们在 DDIM 去噪管道中保持编辑,背景和西瓜的结构会发生不必要的变化,并且原始兔子的姿势也会丢失。受交叉注意力图提供图像语义布局这一事实的启发,如图4的第二行所示,通过将编辑词的交叉注意力图在反转过程中阈值化为常数τ,从而获得二元掩码\(M_t\)。

图4:使用稳定扩散的零镜头形状编辑(兔子→老虎)中的混合自我注意力研究。第四列和第五列:忽视自我关注无法保留原有的结构和背景,幼稚的替换会导致伪影。第三列:使用交叉注意力贴图(第二行)混合自注意力,从具有相似姿势的目标文本中获取新形状,并从输入帧中获得背景。
然后,将编辑阶段 \(s^{edit}_t\) 和反演阶段 ssrc t 的自注意力映射与二元掩码 Mt 混合,如图 2 所示。从形式上讲,注意力图融合实现为