
一、介绍
得益于扩散模型的发展,视频生成取得了突破性进展,特别是在基本的文本到视频(T2V)生成模型中。现有的大多数方法都遵循一种逻辑来获取视频模型,那就是通过添加时态模块,然后用视频训练视频模型,将文本到图像(T2I)主干扩展到视频模型。一些模型从头开始训练视频模型,而大多数模型从预先训练的T2I模型开始,通常是稳定扩散(SD)。根据扩散模型建模的空间,模型也可以分为两组,即像素空间模型和潜在空间模型。后者是占主导地位的方法。图像质量、运动一致性和概念构图是评估视频模型的重要维度。图像质量是指清晰度、噪点、失真、美学评分等方面。运动一致性是指帧与运动平滑度之间的外观一致性。概念构图代表了将不同概念组合在一起的能力,这些概念可能不会同时出现在真实视频中。
最近,一些商业初创公司发布了他们的 T2V 模型,可以制作出噪音最小、细节出色、美学得分高的合理视频。然而,他们在大规模且过滤良好的高质量视频数据集上接受训练,社区和学术界无法访问该数据集。由于版权限制和后期过滤处理,收集数百万个高质量视频具有挑战性。虽然有一些开源的视频数据集从互联网上收集到用于视频理解,如HowTo100M、HD-VILA100M和InterVid,但视频生成存在许多问题,例如图像质量和字幕差、一个视频中有多个剪辑以及静态帧或幻灯片。WebVid10M 是学术界使用最广泛的视频生成模型训练数据集。剪辑分割良好,多样性很好。但是,画质不尽如人意,大多数视频的分辨率约为320p。缺乏高质量的数据集是学术界训练高质量视频模型的重大障碍。
在这项工作中,针对一个相当具有挑战性的问题,即在不使用高质量视频的情况下训练高质量的视频模型。本文深入研究了基于SD的训练模型的训练过程,分析了不同训练策略下空间和时间模型之间的联系,并研究了低质量视频的分布转移。作者做了一个有意义的观测,即所有模块的完全训练比仅仅训练时间模块更能使外观和运动之间的耦合更强。完整的训练可以实现更自然的运动,并容忍更多的空间模块后续修改,这是提高生成视频质量的关键。基于对连接的观察,作者提出一种在数据水平上将运动与外观分开来克服数据限制的方法。具体来说,作者利用低质量的视频来保证动作的一致性,而不是高质量的视频,并使用高质量的图像来保证图像质量和概念构图能力。得益于SDXL和Midjourney等成功的T2I模型,可以方便地获得大量具有高分辨率和复杂概念构图的图像。根据分析的准则,作者设计了一个管道来完全训练从标清扩展的视频模型。然后,通过探索使用合成图像修改完全训练模型的空间和时间模块的不同方法,作者发现仅微调空间权重优于其他方式,直接微调优于LORA。图 1 显示了该方法生成的可视化示例。

图1.给出文本提示,本文的方法可以生成具有高视觉质量和准确文本视频对齐的视频。请注意,它仅使用低质量的视频和高质量的图像进行训练。不需要高质量的视频。
本文的主要贡献总结如下:
- 👒作者提出了一种克服数据的方法,通过在数据水平上将运动与外观分开,来训练高质量的视频模型。
- 🎪本文研究了空间和时间模块之间的联系,以及分布偏移。识别关键信息,以获得高质量的视频模型。
- 🏓作者根据观察结果设计了一个有效的管道,即首先获得一个经过充分训练的视频模型,然后用合成的高质量图像调整空间模块。
二、方法
本文提出了一种有效的方法来克服训练高质量视频扩散模型的数据局限性。首先分析了不同训练策略下基于SD的视频模型的空间和时间模块之间的联系。然后,根据观察结果,开发了一个管道来训练高质量的视频模型,仅使用低质量的视频和高质量的图像,即在数据级别上将外观与运动分开。
1.Spatial-temporal Connection Analyses
基本 T2V 型号。为了利用在大规模图像数据集上训练的标清中的先验,大多数文本到视频扩散模型通过添加时间模块将标清模型膨胀为视频模型,包括Align Your Latent、AnimateDiff、LVDM、Magic Video、ModelScopeT2V 和 LAVIE。他们遵循VDM使用一种特定类型的3D-UNet,该3D-UNet在空间和时间上被分解。
这些模型可以根据其训练策略分为两组。一种是使用视频来学习空间和时间模块,并将SD权重作为初始化,称为完全训练。另一种是用固定的空间模块来训练时间模块,称为部分训练。Align Your Latent 和 AnimateDiff 属于第一组,而其他 T2V 模型属于另一组。
尽管这些基于 SD 的 T2V 模型具有相似的架构,但它们是在不同的训练设置下训练的。本文采用一个典型模型,研究了两种训练策略下空间模块和时间模块之间的联系。遵循开源 VideoCrafter1的架构,具有 FPS(每秒帧数)条件。作者还在 ModelScopeT2V中加入了时间卷积,以提高时间一致性。
用于完全和部分训练的参数扰动:作者使用相同的数据将这两种训练策略应用于同一架构。该模型是根据预训练的 SD 权重初始化的。WebVid-10M 被用作训练数据。为了避免概念遗忘,LAION-COCO 600M 也用于视频和图像联合训练。图像分辨率是 512 × 320。为简单起见,完全训练的视频模型表示为 \(\textcolor{blue}{M_F(\theta_T, \theta_S)}\),而部分训练的视频模型表示为 \(\textcolor{blue}{M_P(\theta_T, \theta_S^0)}\),其中 \(\textcolor{blue}{θ_T}\) 和 \(\textcolor{blue}{θ_S}\) 分别是时间和空间模块的学习参数。\(\textcolor{blue}{θ^0_S}\) 是 SD 的原始空间参数。
为了评估空间和时间模块之间的连接强度,作者通过使用另一个高质量的图像数据集\(D_I\)来扰动指定模块的参数进行微调。图像数据是 JDB,由来自Midjornery的合成图像组成。由于 JDB 有 400 万张图像,并使用 LORA 进行微调。
空间扰动(Spatial Perturbation):首先使用图像数据集扰动了两个视频模型的空间参数。时态参数被冻结。完全训练的基础模型 \(\textcolor{blue}{M_F}\) 的扰动过程可以表示为:

其中 \(\textcolor{blue}{PERTB^{LORA}_{θ_S}}\) 表示使用 LORA 对图像数据集 \(\textcolor{blue}{D_I}\) 上的 \(\textcolor{blue}{θ_S}\) 微调 \(\textcolor{blue}{M_F}\)。\(\textcolor{blue}{∆_{θ_S}}\) 表示 LORA 分支的参数。类似地,可以得到部分训练的视频模型的扰动模型:

为了便于理解,作者使用名称“F-Spa-LORA”来表示模型 \(\textcolor{blue}{M^′_F}\),并使用“P-Spa-LORA”来表示 \(\textcolor{blue}{M^′_P}\)。“F”表示完全训练的基础模型,而“P”表示部分训练的模型。“Spa”和“Temp”分别表示对空间和时间模块进行微调。“LORA”表示使用 LORA 进行微调,而“DIR”表示没有 LORA 的直接微调。例如,“F-Spatial-LORA”表示使用 LORA 的完全训练的 T2V 模型的扰动空间模块。
比较两个结果模型的合成视频,能够得出以下观察结果。首先,F-Spa-LORA的运动质量比P-Spa-LORA更稳定(见表4中的用户研究)。在微调过程中,P-Spa-LORA的运动会迅速变差。微调步骤越多,视频往往更静止,局部闪烁(见图 2)。而与完全训练的基础模型相比,F-Spa-LORA 的运动略有退化。其次,P-Spa-LORA的视觉质量比F-Spa-LORA好得多(见图2)。与部分训练的基础模型相比,F-Spa-LORA的图像质量和美学得分大大提高(见表3)。令人惊讶的是,水印也被删除了。虽然 F-Spa-LORA 在画质和美学得分方面略有提高,但生成的视频仍然很嘈杂。

图2.使用 LORA 扰动空间模块。
从这两个观察结果中,我们可以得出结论,完全训练模型的空间和时间模块之间的耦合强度强于部分训练模型的耦合强度。因为部分训练模型的时空耦合很容易被破坏,导致快速运动退化和图像质量偏移。较强的连接比弱连接更能承受参数扰动。这个观察结果可以用来解释 AnimateDiff 的质量改进和运动退化。AnimateDiff 不是通用模型,仅适用于选定的个性化 SD 模型。原因是它的运动模块是用部分训练策略获得的,不能容忍较大的参数扰动。当个性化模型与时态模块不匹配时,图像和运动质量都会下降。
时间扰动(Temporal Perturbation):部分训练的模型仅更新了时态模块,但图像质量已转换为 WebVid-10M 的质量。因此,时间模块不仅负责运动,还负责图像质量。扰动时间模块,同时用图像数据集固定空间模块。扰动过程可以表示为:

我们观察到 P-Temp-LORA (\(\textcolor{blue}{M^{′′}_P}\)) 的图像质量优于 F-Temp-LORA (\(\textcolor{blue}{M^{′′}_F}\))。然而,视频的前景和背景更加不稳定,即时间一致性变差(见图3)。F-Temp-LORA的画面有所改善,但水印仍然存在。它的运动接近基本模型,比 P-Temp-LORA 好得多(见表 4)。这些观测结果也支持了从空间扰动中获得的结论。

图3.使用 LORA 扰动时间模块。
2.Data-level Disentanglement of Appearance and Motion
由于版权问题,获得具有高度多样性的大规模、高质量视频数据集具有挑战性,因此作者探索了在不使用高质量视频的情况下训练高质量视频模型的可能性。首先可以访问低质量的视频,例如 WebVid-10M 和高质量的图像,例如 JDB。作者建议在数据层面上将运动与外观分开,即从低质量视频中学习运动,同时从高质量图像中学习图像质量和美学。可以先用视频训练视频模型,然后用图像微调视频模型。关键在于如何训练视频模型以及如何用图像对其进行微调。
根据对空间和时间模块之间联系的研究,完全训练的模型更适合于后续对高质量图像的微调。这是因为强烈的时空耦合可以承受空间和时间模块的参数扰动,而不会出现明显的运动退化。
接下来,需要研究如何使用图像微调基础模型。在空间和时间扰动(第3.1节)中,图像质量可以提高,但不是很明显。为了获得更大的质量改进,我们评估了两种策略。一种是涉及更多参数,即使用图像微调空间和时间模块。另一种是改变微调方法,即使用没有LORA的直接微调。评估以下四种情况:
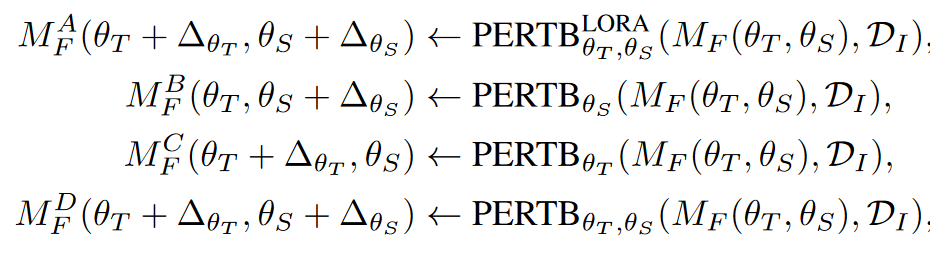
其中 \(\textcolor{blue}{M^A_F}\) (F-Spa&Temp-LORA)是通过遵循第一种策略获得的,而 \(\textcolor{blue}{M^B_F}\) , \(\textcolor{blue}{M^C_F}\) 和 \(\textcolor{blue}{M^D_F}\) 则使用第二种策略获得。 \(\textcolor{blue}{M^B_F}\) (F-Spa-DIR) 和 \(\textcolor{blue}{M^C_F}\) (F-TempDIR) 分别表示直接微调空间和时间模块。 \(\textcolor{blue}{M^D_F}\) (F-Spa&Temp-DIR) 表示直接微调所有模块。
比较四个模型生成的视频,我们得出以下观察结果。首先,F-Spa&Temp-LORA可以进一步提高F-Spa-LORA的画质,但质量仍然不尽如人意。大多数生成的视频中都存在水印,噪点明显。其次,F-TempDIR 比 F-Temp-LORA 获得更好的图像质量。它也比F-Spa&Temp-LORA更好。一半的视频中的水印被移除或变亮。第三,F-SpaDIR和F-Spa&Temp-DIR在微调的型号中实现了最佳的图像质量。然而,F-Spa-DIR的运动更好(见图4和表4)。F-Spa&Temp-DIR的前景和背景在M D F生成的视频中闪烁,尤其是局部纹理。

图4.基于完全训练的 T2V 模型选择模块。
通过探索微调策略和不同的模块,我们发现直接用高质量图像微调空间模块是提高图像质量的最佳方法,而不会降低运动质量。至此,我们的数据级解纠缠流水线可以总结如下:先用低质量视频对视频模型进行全面训练,然后只用高质量图像直接微调空间模块。
3.概念构成的推进
为了提高视频模型的概念组合能力,作者建议在部分微调阶段使用具有复杂概念的合成图像,而不是使用真实图像。SDXL 和 Midjornery 等 T2I 模型的成功是建立在大规模高质量图像之上的。他们有能力复合现实世界中没有出现的概念。作者建议通过合成一组具有复杂概念的图像,而不是使用他们的训练图像,将他们的概念组合能力转移到视频模型中。通过这种方式,作者认为可以减轻同时捕捉概念和动作的负担。
为了验证合成图像的有效性,作者使用 JDB 和 LAION-aesthetics V2 作为第二微调阶段的图像数据。LAION-aesthetics V2 由网络收集的图像组成,而 JDB 包含由 Midjourney 合成的图像。可以观察到,用 JDB 训练的模型具有更好的概念组合能力(见图 5 和表 3)。
三、实验
1.设置
数据:为了克服数据限制,作者利用WebVid-10M 作为低质量视频数据的来源,并使用JDB 作为高质量图像数据的来源。WebVid-10M 是一个大规模、多样化的视频数据集,包含大约 1000 万对文本-视频。大多数视频的分辨率为 336 × 596,每个视频由一个镜头组成。在训练过程中,从不同帧速率的视频中采样。JDB 是一个大型图像数据集,包含来自 Midjourney 的约 400 万张高分辨率图像,每张图像都带有相应的文本提示注释。为了防止在基本 T2V 模型的训练过程中忘记概念,我们还采用了 LAION-COCO,这是一个包含 6 亿个为公开可用的 Web 图像生成的高质量字幕的数据集,用于图像和视频训练
Metrics:作者利用 EvalCrafter 进行定量评估。EvalCrafter 是评估文本到视频生成模型的基准,其中包含大约 18 个视觉质量、内容质量、运动质量和文本字幕对齐的客观指标。它提供了大约 512 个提示。客观指标与来自五项主观研究的用户意见一致,即运动质量、文本-视频对齐、时间一致性、视觉质量和用户偏好。运动质量考虑了三个指标:动作识别、平均流量、振幅分类分数,而时间一致性考虑了变形误差、语义一致性、面部一致性。EvalCrafter 中的技术和美学评分改编自 DOVER。此外,由于仍然缺乏一个全面的客观指标来衡量运动质量,因此作者还对人类偏好进行了用户研究。
Training Details:在 Sec 3.1 中,两个基于的模型共享相同的架构,改编自开源 VideoCrafter1,并结合了来自 ModelScopeT2V 的时间卷积。空间模块使用 SD 2.1 中的权重进行初始化,时间模块的输出初始化为零。训练分辨率设置为 512 × 320。对于联合图像和视频训练,使用低质量的 WebVid-10M 和 LAION-COCO 数据集。这些模型在 32 个 NVIDIA A100 GPU 上进行训练,用于 270K 迭代,批处理大小为 128。所有训练任务的学习率设置为 5 × 10−5。当使用 LORA 对时态或空间模块进行扰动时,并且专门使用 JDB 进行调谐。微调在 8 个 A100 GPU 上进行,用于 30K 迭代,批处理大小为 256。鉴于 JDB 的图像具有方形分辨率,将微调分辨率调整为 512 × 512。
2.比较 State-of-the-Art T2V Models
作者将他们的方法与几个最先进的 T2V 模型进行了比较,包括 Gen-2 和 Pika Labs 等流行的商业模型,以及 Show-1、VideoCrafter1 和 AnimateDiff 等开源模型。Gen-2、Pika Labs 和 VideoCrafter1 都利用高质量视频来训练他们的 T2V 模型。值得注意的是,AnimateDiff 和本文提出的模型仅使用来自 WebVid-10M 的视频。Show-1 使用额外的高质量视频进行微调以消除 WebVid10M 中的水印。AnimateDiff 不是通用的 T2V 模型;它仅当 LORA SD 模型与其时态模块兼容时才有效.为了进行比较,作者使用基于SD v1.5的时间模块(第二版),并采用Realistic Vision V2.0 作为其相应的LORA模型。
定量评估:使用EvalCrafter获得的定量结果如表1所示。本文的方法实现了与VideoCrafter1和Pika Labs相当的视觉质量,后者使用高质量的视频进行训练。这凸显了使用高质量图像来提高图像质量和美学分数的有效性。此外,本文的文本-视频对齐性能排名第二。在运动质量方面,本文模型的性能超过了Show-1,但与利用大量视频来学习运动的模型相比,VideoCrafter2性能有所欠缺。这表明该方法可以在不显著运动退化的情况下提高视觉质量。

定性评估:视觉比较如图 6 所示。“ours”结果的视觉质量与 Gen-2 和 Pika Labs 等商业模型相当。由于本文使用 JDB 作为图像数据集,因此合成视频的图像质量从 WebVid-10M 转变为 JDB。在运动方面,“ours”运动质量优于 AnimateDiff,可与 Show-1 相媲美。尽管将时态模块与 LORA SD 模型集成可以提高视觉质量,但 AnimateDiff 在通用场景中会出现运动降级。


图4.不同文本到视频生成模型的比较。
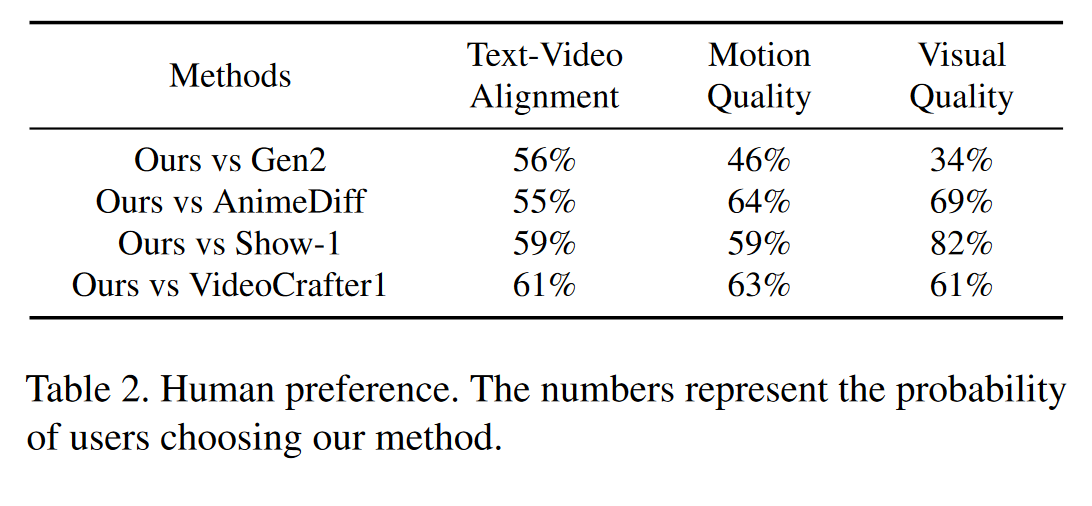
用户研究:为了进一步评估,本文进行了一项用户研究,将本文的方法与其他视频模型进行比较。从 EvalCrafter 中选择了 50 个提示,涵盖了不同的场景、样式和对象。在比较模型对时,要求三位视频制作专家根据给定的主题(即视觉质量、运动质量和文本视频对齐)从三个选项中选择他们喜欢的视频:方法 1、方法 2 和可比较的结果。结果如表2所示。“ours”方法比 AnimateDiff 和 Show-1 具有更好的视觉质量,并且与 VideoCrafter1 相当。“ours”方法在运动质量方面比 Show-1 和 AnimateDiff 更受欢迎。
3.策略评估
时空连接:在第 3.1 节中,展示了图 2 和图 3 中完全和部分训练模型的空间和时间参数扰动的视觉比较。在这里,提供了表3中视觉质量的定量比较,包括DOVER的美学和技术得分

我们能够观察到,微调部分训练的模型总是可以获得比完全训练的模型更好的视觉质量。这意味着可以更容易地移动部分训练模型的分布。此外,本文还进行了一项用户研究,要求参与者选择在前景/背景闪光和运动闪烁方面在运动中具有更好性能的有利型号。结果如表4所示。可以观察到,扰动完全训练模型的运动质量更好。与部分训练的模型相比,完全训练的模型可以容忍更大的参数扰动。这些观察表明,完全训练的模型具有更强的时空耦合。

模块选择:在选择完全训练的模型作为基础后,使用两种策略来确定最有效的模块进行微调,从而在第 3.2 节中产生四个模型。这些模型的视觉质量评估如表3的底部所示。F-Spa-DIR 和 F-Spa&Temp-DIR 的视觉质量比其他两个型号要好得多。它揭示了直接微调空间模块是提高图像质量的关键。
由于 F-Spa-DIR 和 F-Spa&Temp-DIR 的视觉质量非常接近,因此本文对运动质量进行了用户研究以确定最终模型。结果显示在表 4 的最后一行。直接微调空间模块只会在运动中表现得更好。如图4所示,F-Spa-DIR比FSpa&Temp-DIR更稳定,时间一致性更好。后者在前景和背景中都有明显的闪光。
图像数据的影响:为了验证合成图像的有效性,本文分别使用LAION Aesthetics V2数据集和JDB在第二阶段直接微调空间模块。可视化示例如图 5 所示。结果表明,使用 JDB 复合概念训练的模型优于使用 LAION Aesthetics V2 训练的模型。视觉质量的定量评价如表3所示。F-Spa-DIR 在美学和技术得分方面都比 F-Spa-DIR-LAION 好得多。

图5.图像数据对概念构成的影响。“F-SpaDIR-LAION”使用LAION aesthetics V2作为图像数据,而“F-Spa-DIR”使用JDB。
四、总结
为了克服数据限制,本文提出了一种在不使用高质量视频的情况下训练高质量视频扩散模型的方法。深入研究了基于SD的视频模型的训练方案,并研究了空间和时间维度之间的耦合强度。我们可以观察到,完全训练的 T2V 模型比部分训练的模型表现出更强的时空耦合。基于这一观察结果,我们建议在数据层面上将外观与运动分开,即利用低质量视频进行运动学习,利用高质量图像进行外观学习。此外,我们建议使用具有复杂概念的合成图像进行微调,而不是真实图像。进行定量和定性评估,以证明所提方法的有效性。