
一、介绍
在当今的数字时代,短视频已成为一种占主导地位的娱乐形式。这些视频的编辑和艺术渲染具有相当打的实际意义。目前,扩散模型的最新进展使用户能够通过自然语言提示方便地操作图像,从而彻底改变了图像编辑。尽管在图像领域取得了这些进步,但视频处理仍然带来了独特的挑战,尤其是在确保自然运动与时间一致性方面。
时间相关运动可以通过在广泛的视频数据集上训练视频模型或在单个视频上微调重构的图像模型来学习,然而,这对普通用户来说既不经济也不方便,或者,零样本方法通过改变具有额外时间一致性约束的图像模型的推理过程,为视频处理提供了一种有效的途径。除了效率之外,零样本方法还具有与为图像模型设计的各种辅助技术(例如ControlNet和LoRA)高度兼容的优点,从而实现更灵活的操作。
现有的零样本方法主要集中在改进注意力机制上。这些技术通常用跨帧注意力代替自我注意力机制,聚合多个帧的特征。但是此方法仅确保粗略级别的全局风格一致性。为了实现更精细的时间一致性,Rerender-A-Video 和 FLATTEN等方法假设生成的视频保持与原始视频相同的帧间对应关系。它们结合了原始视频中的光流来指导特征融合过程。虽然这一战略显示出希望,但有三个问题仍未得到解决。
1)不一致:操作过程中光流的变化可能会导致引导不一致,从而导致某些前景出现在静止的背景区域而没有适当的前景移动等问题(图2 (d)-(f) )。
2)覆盖不足:在遮挡或快速运动阻碍精准光流估计的区域,由此产生的约束不足,导致失真(图2 (c)-(e) )。
3)不准确:顺序逐帧生成仅限于局部优化,误差会随时间的累积(图2(b)中缺少手指,因为前几帧中没有参考手指)。

图2.真实视频到CG视频翻译。Rerender-A-Video方法仅依靠光流会出现(a),(f):不一致或 (c),(d),(e):缺失光流引导和 (b):误差累积。通过引入FRESCO,很好地解决了这些挑战。
为了解决上述关键问题,作者提出了帧时空响应(FRESCO)。虽然以前的方法主要侧重于约束帧间时间对应关系,但保持帧内空间对应关系同样重要。FRESCO能够确保语义相似的内容得到连贯的处理,在翻译后保持其相似性。这种策略有效地解决了前两个挑战:它可以防止前景被错误地转换为背景,并增强光流的一致性。对于没有光流的区域,原始坐标系内的空间对应关系可以作为调节机制,如图2所示。
FRESCO被引入两个层次:注意力和特征。在注意力层面,作者引入了FRESCO引导注意力。它建立在光流引导之上,并通过集成输入帧的自相似性来丰富注意力机制。它允许有效使用输入视频中的帧间和帧内线索,以更受约束的方式战略性地将焦点引导到有效特征上。在特征层面,作者提出了FRESCO感知特征优化。这不仅仅影响特征注意力,它还涉及U-Net解码器层中语义上有意义的功能显示更新。这是通过梯度下降来实现的,以与输入视频的高度时空一致性紧密对齐。这两项增强功能的协同作用导致性能显著提升,如图1所示。为了克服最后的挑战,作者采用了多帧处理策略。批处理中的帧是集体处理的,允许它们相互引导,而锚帧则在批处理之间共享,以确保批次之间的一致性。对于长视频翻译,使用启发式方法进行关键帧选择,并对非关键帧帧采用插值。

图1.FRESCO框架基于预训练的图像扩散模型实现高质量和连贯的视频翻译。给定一个输入视频,该方法会根据目标文本提示重新渲染它,同时保留其语义内容和动作。FRESCO零样本框架与各种辅助技术兼容,如 ControlNet、SDEdit 和 LoRA,可实现更灵活和定制的翻译。
本文的主要贡献:
1️⃣一种以帧时空对应关系为指导的新型零样本扩散架构,用于连贯灵活的视频翻译。
2️⃣将FRESCO 引导的特征关注和优化结合为强大的帧内和帧间约束,与单独的光流相比,具有更好的一致性和覆盖范围。
3️⃣通过联合处理批处理帧,实现批次间一致性的长视频翻译。
二、方法
1.总体框架
所提出的零样本视频翻译流水线如图3所示。给定一组视频帧 \(\textcolor{blue}{I = \{I_i\}^N_{i=1}}\),按照执行 DDPM 正向和后向处理,以获得其转换后的 \(\textcolor{blue}{I^\prime = \{I^\prime_i\}^N_{i=1}}\)。而 \(\textcolor{blue}{I}\) 的时间和空间对应关系定义为:
Temporal correspondence:这种帧间对应关系是通过相邻帧之间的光流来测量的,这是保持时间一致性的关键因素。将 \(\textcolor{blue}{I_i}\) 到 \(\textcolor{blue}{I_j}\) 的光流和遮挡掩模分别表示为 \(\textcolor{blue}{w^j_i}\) 和 \(\textcolor{blue}{M^j_i}\),我们的目标是确保 \(\textcolor{blue}{I^\prime_i}\) 和 \(\textcolor{blue}{I^\prime_{i+1}}\) 在非遮挡区域共享 \(\textcolor{blue}{w^{i+1}_i}\)。
Spatial correspondence:这种帧内对应关系通过单个帧内像素之间的自相似性来衡量。目的是使 \(\textcolor{blue}{I^′_i}\) 与 \(\textcolor{blue}{I_i}\) 共享自相似性,即语义相似的内容被转化为相似的外观,反之亦然。这种语义和空间布局的保留隐含地有助于提高翻译过程中的时间一致性。
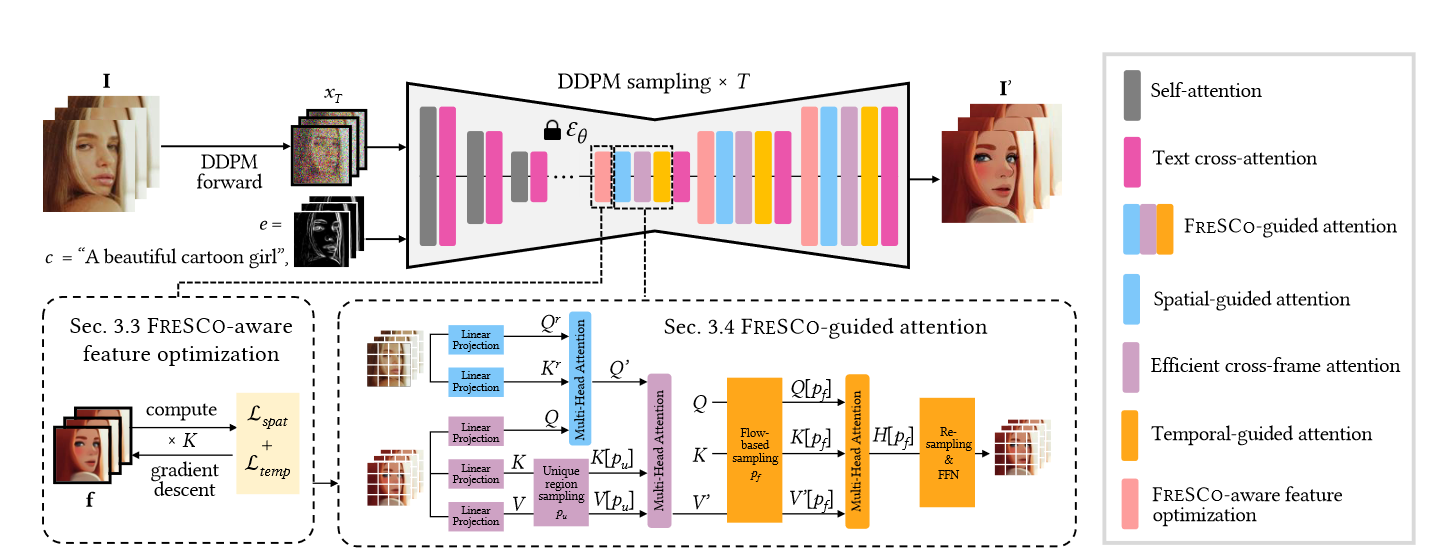
图3.零镜头视频翻译框架,由 FRamE 时空响应 (FRESCO) 指导。对 U-Net 要素应用了 FRESCOaware 优化,以增强其与输入帧的时间和空间一致性。作者还将FRESCO集成到自我注意力层中,从而产生空间引导注意力,以保持与输入帧的空间对应关系,高效的跨帧注意力和时间引导注意力,分别保持与输入帧的粗略和精细的时间对应关系。
adaptation集中于 U-Net 中解码器层的输入特征和注意力模块,因为解码器层的噪声比编码器层小,并且比 \(\textcolor{blue}{x_t}\) 潜在空间在语义上更有意义:
Feature adaptation:作者提出了一种新的FRESCO感知特征优化方法,如图3所示。设计了一个空间一致性损失 \(\textcolor{blue}{L_{spat}}\)和一个时间一致性损失 \(\textcolor{blue}{L_{temp}}\) 来直接优化解码层特征\(\textcolor{blue}{f = \{f_i\}^N_{i=1}}\),以加强它们与输入帧的时间空间一致性。
Attention adaptation:这里是将FRESCO引导注意力代替了自我注意力,包括三个组成部分,如图3所示。空间引导的注意力首先根据输入帧的自相似性聚合特征。然后,使用跨帧注意力聚合所有帧的特征。最后,时间引导注意力沿同一光流聚合特征,以进一步加强时间一致性。
Feature adaptation直接优化了特征,使其与\(\textcolor{blue}{I}\)具有高度的空间和时间一致性。同时,Attention adaptation通过对如何以及在何处关注有效特征施加软约束来间接提高连贯性。文章中提出将这两种适应形式结合起来可以达到最佳性能。
2.FRESCO-Aware feature Optimization
UNet各解码层的输入特征\(\textcolor{blue}{f = \{f_i\}^N_{i=1}}\)通过梯度下降进行优化
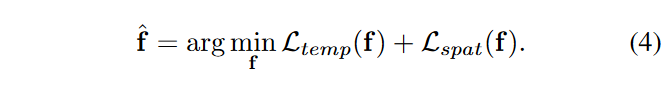
更新后的\(\textcolor{blue}{\hat{f}}\)替换\(\textcolor{blue}{f}\)以进行或许处理,对于时间一致性损失\(\textcolor{blue}{L_{temp}}\),并且我们希望每两个相邻帧之间对应位置的特征值保持一致。
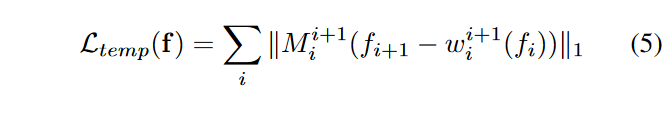
对于空间一致性损失\(\textcolor{blue}{L_{spat}}\),利用特征空间中的余弦相似度来度量 \(\textcolor{blue}{I_i}\) 的空间对应关系。具体来说,对 \(\textcolor{blue}{I_i}\) 执行单步 DDPM 前向和后向处理,并提取 U-Net 解码器特征,表示为 \(\textcolor{blue}{f^r_i}\) 。由于单步前进过程增加的噪声可以忽略不计,因此 \(\textcolor{blue}{f^r_i}\) 可以作为 \(\textcolor{blue}{I_i}\) 的语义有意义的表示来计算语义相似性。然后,可以简单地将所有元素对之间的余弦相似度计算为归一化特征的gram矩阵。设 \(\textcolor{blue}{\tilde{f}}\) 表示归一化的 \(\textcolor{blue}{f}\),使 \(\textcolor{blue}{\tilde{f}}\) 的每个元素都是一个单位向量。我们希望 \(\textcolor{blue}{\tilde{f}_i}\)的 gram 矩阵接近\(\textcolor{blue}{\tilde{f}^r_i}\) 的 gram 矩阵,
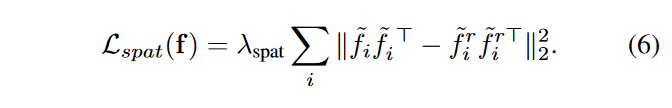
3.FRESCO-Guided Attention
FRESCO引导的注意力层包含三个连续的模块:空间引导注意力、高效跨帧注意力和时间引导注意力,如图3所示。
空间引导注意力(Spatial-guided attention):与自我注意力相反,空间引导注意力中的patches根据平移前patches的相似性而不是它们自身的相似性相互聚合。具体来说,与第 3.2 节中计算 \(\textcolor{blue}{L_{spat}}\) 一致,对 \(\textcolor{blue}{I_i}\) 执行单步 DDPM 前向和后向过程,并提取其自注意力查询向量 \(\textcolor{blue}{Q^r_i}\) 和关键向量 \(\textcolor{blue}{K^r_i}\) 。然后,空间引导的注意力聚集了\(\textcolor{blue}{Q_i}\)
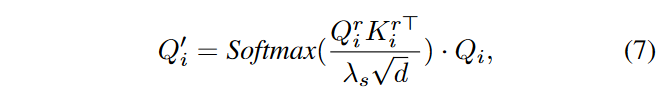
其中 \(\textcolor{blue}{λ_s}\) 是比例因子,\(\textcolor{blue}{d}\) 是query向量维度。如图4所示,前景patch将主要聚合\(\textcolor{blue}{C}\)形前景区域的特征,而较少关注背景区域。因此,\(\textcolor{blue}{Q^\prime}\) 与输入帧的空间一致性优于 \(\textcolor{blue}{Q}\)。
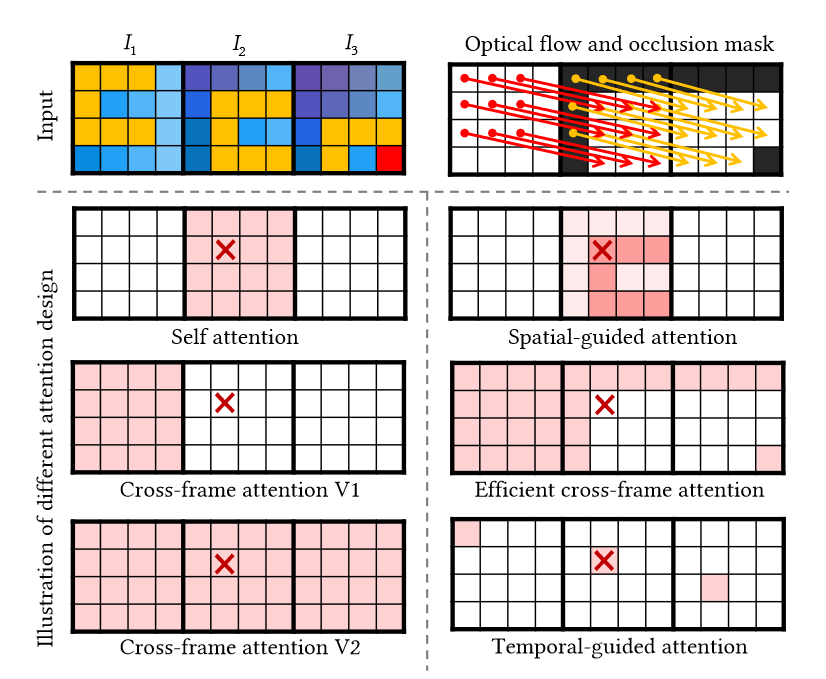
图4.注意力机制的图示。标有红叉的patch关注彩色patch并聚合其特征。与之前的注意力相比,FRESCO引导的注意力进一步考虑了输入的帧内和帧间对应关系。空间引导注意力:根据输入帧的自相似性聚合帧内特征(越暗表示权重越高)。高效的跨帧注意力:消除了冗余patches并保留了独特的patches。时间引导的注意力聚合同一流上的帧间特征。
高效的跨帧注意力(Efficient cross-frame attention):FRESCO使用跨帧注意力代替自我注意力,以规范全局风格的一致性。这里不是使用第一帧或前一帧作为参考(V1,图4),这不能处理新出现的物体(例如,图2(b)中的手指),或者使用所有可用的帧作为参考(V2,图4),这在计算上是低效的,我们的目标是同时考虑所有帧,但冗余尽可能少。因此,作者提出了高效的跨帧注意力:除了第一帧,只引用每个帧中在前一帧中未看到的区域(即遮挡区域)。因此,可以构造上述区域内所有patches的跨帧索引 \(\textcolor{blue}{p_u}\)。这些patches的Keys和Values可以采样为 \(\textcolor{blue}{K[p_u]}\)、\(\textcolor{blue}{V[p_u]}\)。然后跨帧注意力被应用于
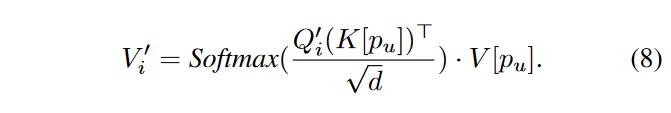
时间引导的注意力(Temporal-guided attention):本文受 FLATTEN的启发使用基于流引导的注意力来规范精细级别的跨帧一致性。在不同的帧中跟踪相同的patch,如图 4 所示。对于每个光流,构建了该光流上所有patches的跨帧索引 \(\textcolor{blue}{p_f}\)。在 FLATTEN 中,每个 Patch 只能处理其他帧中的 Patch,当一个流包含很少的 Patch 时,这是不稳定的。与它不同的是,时间引导的注意力没有这样的限制,
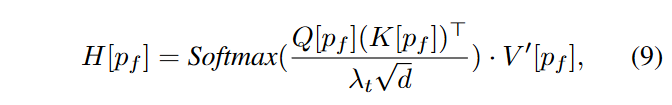
其中 \(\textcolor{blue}{λ_t}\) 是比例因子。\(\textcolor{blue}{H}\) 是 FRESCO 引导注意力层的最终输出。
4.长视频翻译
一次可以处理的帧数 \(\textcolor{blue}{N}\) 受 GPU 内存的限制。对于长视频翻译,本文的做法是仅对关键帧进行零镜头视频翻译,并使用 Ebsynth 根据转换的关键帧插入非关键帧。
关键帧的选择:如算法 1 所示。作者将固定采样步骤放宽到一个间隔 \(\textcolor{blue}{[s_{min}, s_{max}]}\),并在运动较大时密集采样关键帧(通过帧之间的 \(\textcolor{blue}{L_2}\) 距离测量)。

关键帧转换:对于超过 \(\textcolor{blue}{N}\) 个关键帧,将它们拆分为几个 \(\textcolor{blue}{N}\) 帧批次。每个批次都包括前一个批次中的第一帧和最后一帧,以强制执行批次间一致性,即第 \(\textcolor{blue}{k}\) 个批次的关键帧索引为 \(\textcolor{blue}{\{1,(k − 1)(N − 2) + 2, (k − 1)(N − 2) + 3,..., k(N − 2) + 2\}}\)。此外,在整个去噪步骤中,还记录了每批第一帧和最后一帧的潜在特征 \(\textcolor{blue}{x^′_t}\)(使用UNet预测出潜在特征的噪声进行迭代得到),并用它们替换下一批中相应的潜在特征。
三、实验
1.实验设置
实现细节:该实验在一个 NVIDIA Tesla V100 GPU 上进行。默认情况下,根据输入视频分辨率设置批次大小 \(\textcolor{blue}{N ∈ [6,8]}\),损失权重 \(\textcolor{blue}{λ_{spat} = 50}\),比例因子 \(\textcolor{blue}{λ_s = λ_t = 5}\)。对于特征优化,使用 Adam 优化器和 0.4 的学习率更新 \(\textcolor{blue}{K = 20}\) 次迭代的 UNet各解码层的输入特征\(\textcolor{blue}{f}\)。当 \(\textcolor{blue}{K = 20}\) 时,优化大多收敛,而较大的 \(\textcolor{blue}{K}\) 不会带来明显的增益。GMFlow 用于估计光流和遮挡掩模。应用背景平滑来改善背景区域的时间一致性。
2.比较 State-of-the-Art 方法
在这里比较了三种最近的无反转零样本方法:Text2Video-Zero、ControlVideo、Rerender-A-Video。为了确保公平的比较,所有方法都采用相同的 ControlNet、SDEdit 和 LoRA 设置。如图 5 所示,所有方法都根据提供的文本提示成功翻译视频。但是,由于散焦或运动模糊等问题,如果条件质量低下,则依赖于 ControlNet 条件的无反转方法可能会遇到视频编辑质量下降的情况。例如,ControlVideo 无法生成狗和拳击手的合理外观。Text2Video-Zero 和 Rerender-A-Video 努力保持猫的姿势和拳击手手套的结构。相比之下,本文的方法可以基于所提出的鲁棒FRESCO指导生成一致的视频。

图5.与无反转零样本视频翻译方法的视觉对比。
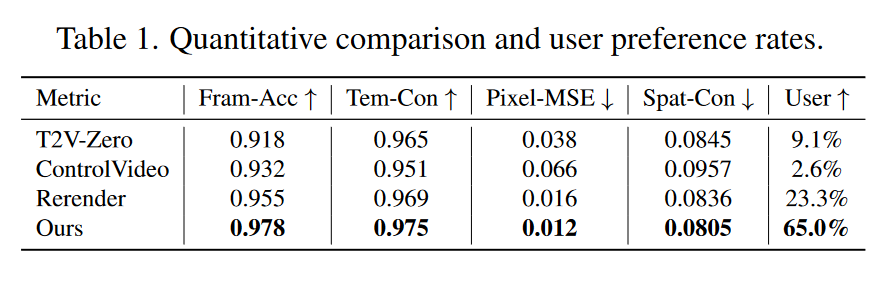
对于定量评估,本文采用Fram-Acc(基于CLIP的逐帧编辑精度),Tmp-Con(连续帧之间基于CLIP的余弦相似度)和Pixel-MSE(对齐的连续帧之间的平均均方像素误差)的评估指标。并进一步报告了 Spat-Con(关于 VGG 特征的 \(L_{spat}\))的空间一致性。表 1 报告了 23 个视频的平均结果。值得注意的是,本文的方法达到了最佳的编辑准确性和时间一致性。作者进一步对 57 名参与者进行了一项用户研究。参与者的任务是在四种方法中选择最可取的结果。表 1 显示了 11 个测试视频的平均偏好率,而本文的方法成为最受欢迎的选择。
3.消融研究
为了验证不同模块对整体性能的贡献,在这里系统地停用了框架中的特定模块。图 6 说明了合并空间和时间对应关系的效果。基线方法仅使用跨帧注意力来保持时间一致性。通过引入与时间相关的适应,我们观察到一致性的改进,例如纹理的对齐和太阳位置在两个帧上的稳定性。同时,与空间相关的适应有助于在翻译过程中保持姿势。
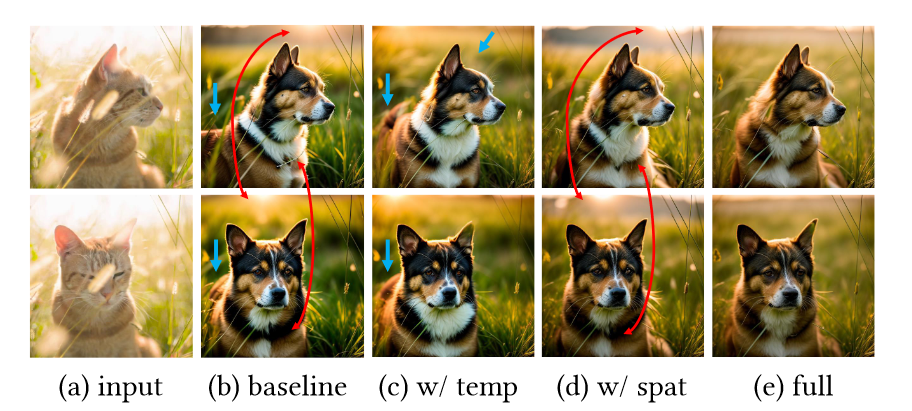
图6.结合空间和时间对应关系的效果。蓝色箭头表示与输入帧的空间不一致。红色箭头表示两个输出帧之间的时间不一致。
在图7中,研究了注意力适应和特征适应的影响。显然,每个增强功能都在一定程度上单独提高了时间一致性,但两者单独使用都无法实现完美。只有两者的结合才能完全消除在发丝中观察到的不一致,图7(b)-(e)的Pixel-MSE得分分别为0.037、0.021、0.018和0.015。

图7.注意适应性和特征适应性的影响。第一行:(a) 输入。其他行:分别通过(b)仅跨帧注意力,(c)attention adapation,(d)feature adapation,(e)注意力和特征适应获得的结果。蓝色区域被放大,右侧的对比度增强,以便更好地比较。提示:CG风格的美女。
关于attention adapation,进一步深入研究了时间引导注意力和空间引导注意力。它们施加的约束强度分别由 \(\textcolor{blue}{λ_t}\) 和 \(\textcolor{blue}{λ_s}\) 决定。如图 8-9 所示,\(\textcolor{blue}{λ_t}\) 的增加有效地增强了背景区域中两个变换帧之间的一致性,而 \(\textcolor{blue}{λ_s}\) 增幅的增加则使变换后的 cat 和原始 cat 之间的一致性。
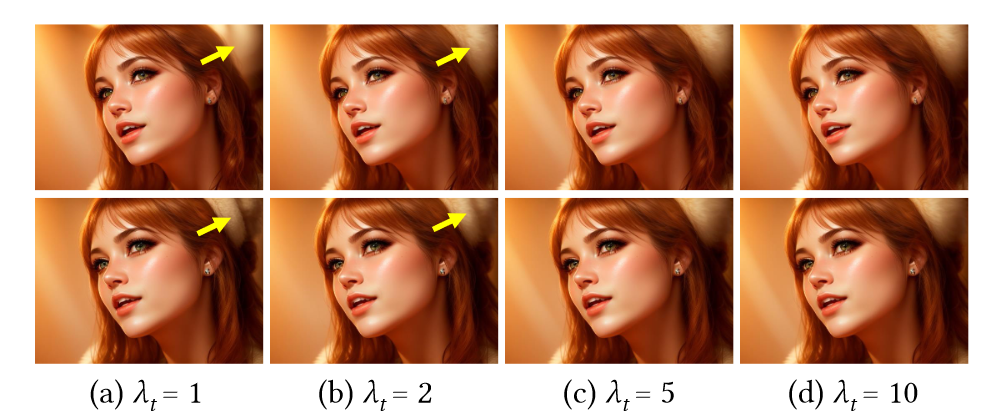
图8.\(λ_t\)的作用。从定量上看,Pixel-MSE得分为(a)0.016,(b)0.014,(c)0.013,(d)0.012。黄色箭头表示两个帧之间的不一致。
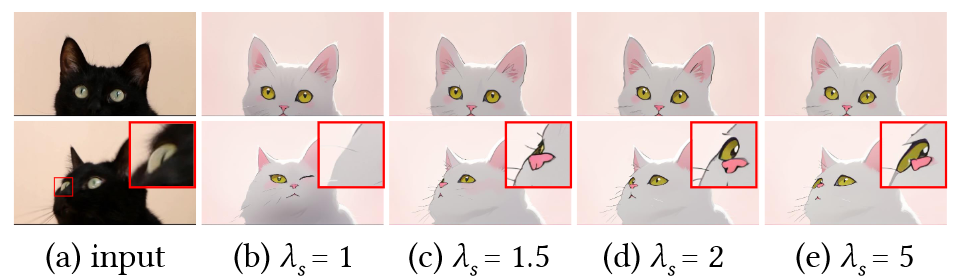
图9.\(λ_s\)的影响。红色框中的区域被放大并显示在右上角,以便更好地进行比较。提示:粉红色背景的卡通白猫。
除了空间引导的注意力之外,本文提出的空间一致性损失也起着重要作用,如图10所示。在此示例中,快速运动和模糊使光流难以预测,从而导致较大的遮挡区域。空间对应引导对于约束该区域的渲染尤为重要。显然,每一次调整都做出了独特的贡献,例如消除了不需要的滑雪杖和不一致的雪纹理。将两者结合起来会产生最一致的结果,图10(b)-(e)的Pixel-MSE分数分别为0.031、0.028、0.025和0.024。

图10.结合空间对应关系的效果。(a) 输入被红色遮挡掩码覆盖。(b)-(d)空间引导注意力和空间一致性损失分别有助于减少滑雪杖(黄色箭头)和雪纹理(红色箭头)的不一致。提示:卡通蜘蛛侠正在滑雪。
表2提供了对每个模块影响的定量评估。与视觉结果一致,很明显,每个模块都有助于整体增强时间一致性。值得注意的是,所有改编的组合产生了最佳性能。
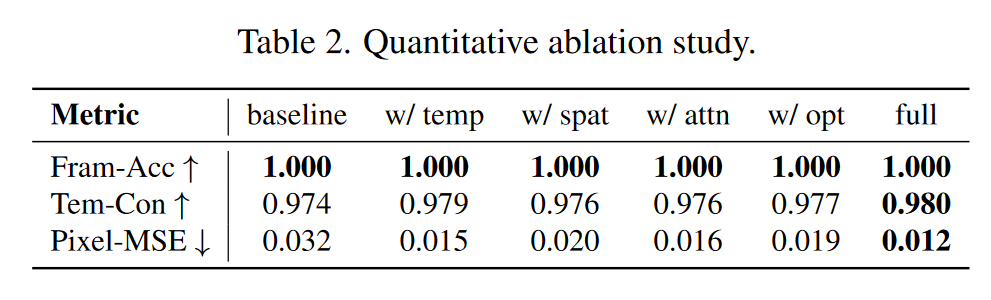
图 11 总结了所提出的高效跨帧注意力。与图2(b)中的Rerender-A-Video一样,顺序逐帧转换容易受到新出现的对象的影响。

图11.有效跨帧注意力的效果:(a) 输入。(b) 跨帧注意力 V1 只关注前一帧,因此无法合成新出现的手指。(d) 有效的跨帧注意力与 (c) 跨帧注意力 V2 的性能相同,但在本例中需要注意的区域减少了 41.6%。提示:一个美丽的女人拿着她的CG风格的眼镜。
跨帧注意力允许关注批处理帧内的所有独特对象,这不仅高效而且更可靠,如图 12 所示。
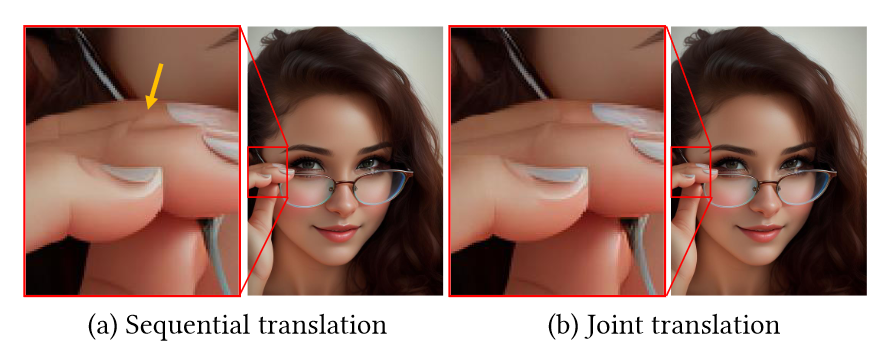
图12.联合多帧平移的效果。Sequential仅依赖于前一帧。Joint translation使用批次中的所有帧相互引导,从而通过参考图 11 中的第三帧来实现准确的手指结构
FRESCO 在注意力层之前使用扩散特征进行优化。由于 U-Net 经过训练可以预测噪声,因此注意力层(靠近输出层)之后的特征会发出噪声,从而导致故障优化( 图 13(b))。同时,四通道 \(\textcolor{blue}{\hat{x}^\prime_0}\) 高度紧凑,不适合翘曲或插值。优化\(\textcolor{blue}{\hat{x}^\prime_0}\)会导致严重的模糊和过度饱和伪像(图 13(c))。

图13.优化扩散特征
4.更多结果
长视频翻译:图 1 显示了长视频翻译的示例。处理包含 400 帧的 16 秒视频,其中 32 帧被选为基于扩散的翻译的关键帧,其余 368 帧进行插值。由于FRESCO 指导生成相干关键帧,非关键帧表现出相干插值,如图 14 所示。

图14.通过根据转换的关键帧插值非关键帧来生成长视频。
视频上色:本文的方法可以应用于给视频上色。如图 15 所示,通过将输入的 \(L\) 通道和翻译视频的 \(AB\) 通道相结合,我们可以在不改变其内容的情况下对输入进行着色。

图15.视频着色。提示:海滩上的一只蓝色海豹。。
5.局限和未来工作
在局限性方面,通过强制与输入视频的空间对应一致性,该方法不支持大的形状变形和明显的外观变化。较大的变形使得使用原始视频的光流作为自然运动的可靠先验变得具有挑战性。这种限制是零样本模型所固有的。未来的潜在方向是纳入学习的运动先验。
四、总结
本文提出了一个零样本框架,用于调整图像扩散模型进行视频翻译。并展示了保留帧内空间对应关系以及帧间时间对应关系的重要作用,这在以前的零拍摄方法中较少探索。文章当中的综合实验验证了该方法在翻译高质量和连贯视频方面的有效性。所提出的FRESCO约束与现有的图像扩散技术表现出高度的兼容性,表明其在其他文本引导视频编辑任务中的潜在应用,如视频超分辨率和着色。