

一、介绍
文本到视频编辑的一个关键挑战是视觉一致性,即编辑视频中的内容在视频当中具有平滑且不变的视觉外观,编辑后的视频不仅应保留源视频的运动,并将结构失真降至最低。
一些视频生成工作,例如Tune-a-video,Text2video-zero,Pix2video。它们试图通过将空间自注意力扩展为时空自注意力,将现有的文本到图像生成的高级扩散模型(SD)扩展到文本到视频编辑模型。具体来说,视频中不同帧的patch特征被组合在扩散的时空注意力模块当中,如图2所示。

图2.空间注意力、时空注意力和光流引导注意力的图示。标有十字的蓝色patches关注蓝色patches并聚合其特征。\(F_k\) 表示第 k 个视频帧的特征图。
通过以这种方式捕获空间和时间上下文,这些方法只需要几个微调步骤,甚至不需要训练即可完成 T2V 编辑。然而,这种简单的扩展操作引入了不相关的信息:因为每个patches都关注视频中的所有其他patches,并在密集的时空注意力中聚合它们的特征。视频中不相关的pathes可能会误导注意力过程,对编辑视频的一致性控制构成威胁。因此,这些方法仍然无法应对文本到视频编辑中的视觉一致性挑战。
在本文中,作者首次提出了FLATTEN,这是一种新颖的(光学)FLow引导ATTENtion,它能够与文本到图像的扩散模型无缝集成,并隐式利用光流进行文本到视频编辑,以解决以前作品中的视觉一致性限制。
FLATTEN 在不同帧的同一流路上强制执行patches,以便在注意力模块中相互关注,从而提高编辑视频的视觉一致性。该方法的主要优点是,在光流的引导下,信息能够在多个帧之间准确通信,从而稳定编辑视频的提示生成的视觉内容。具体地说,作者首先使用预先训练的光流预测模型来估计源视频的光流。然后,估计的光流用于计算patches的轨迹,并引导同一轨迹上pathes之间的注意力机制。同时,作者还提出了一种将光流引导注意力集成到现有扩散过程中的有效方法,即使没有任何训练,也可以保留每帧的特征分布。作者提出了一个以 FLATTEN 为基础并采用 T2I 编辑技术的 T2V 编辑框架,例如 DDIM 反转和特征注入。如图 1 所示,我们可以观察到高质量和高度一致的文本到视频编辑。此外,FLATTEN可以很容易地集成到其他基于扩散的文本到视频编辑方法中,并提高其编辑视频的视觉一致性。

图1.FLATTEN能够生成视觉上一致的视频,这些视频遵循不同类型的(样式、纹理和类别)的文本提示,同时忠实地保留了源视频中的动作。
二、方法
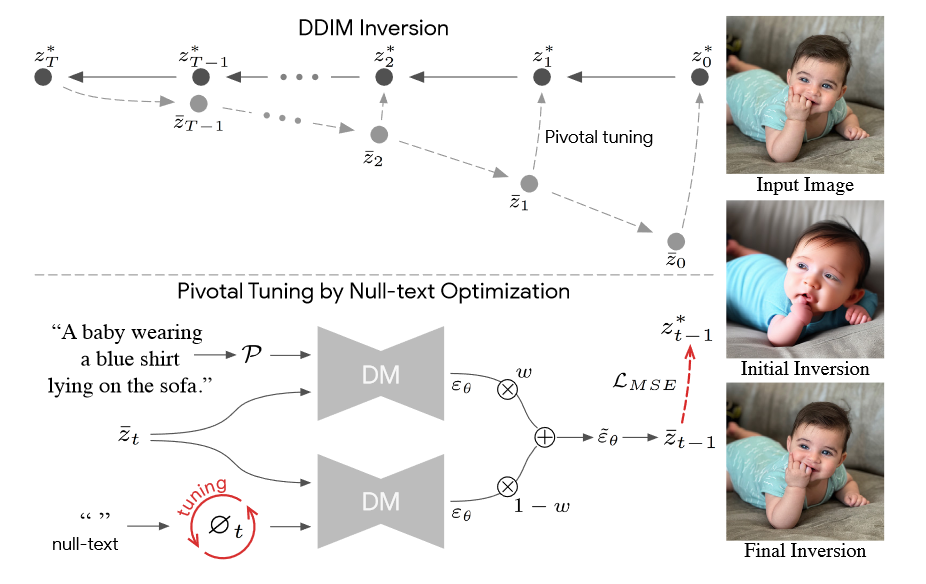
DDIM inversion:
DDIM Inversion:首先在输入图像上应用初始 DDIM Inversion(扩散过程),该反演估计扩散轨迹 \(\{z^∗_t\}^T_0\) 。从最后一个潜在 \(z^*_T\) 开始进行扩散去噪过程会导致不令人满意的重建,因为潜在编码离原始轨迹越来越远。使用初始轨迹作为优化的枢轴,使扩散向后轨迹 \(\{\bar{z}_t\}^T_1\) 更接近原始图像编码 \(z^∗_0\) 。
底部:空文本优化。无分类器指导包括执行两次预测 \(θ\) :使用文本条件嵌入和无条件使用 null 文本嵌入\(∅\)(左下角)。然后,用指导量表 w(中间)推断这些。我们仅优化无条件嵌入 \(∅_t\),方法是在被预测的潜在代码 \(z_{t−1}\) 和枢轴\(z^∗_{t−1}\) 之间采用重构 MSE 损失(红色)。
1.整体框架
FLATTEN框架旨在根据编辑文本提示 \(\textcolor{blue}{τ}\) 编辑源视频,并输出视觉上一致的视频。为此,作者沿时间轴扩展了 T2I 扩散模型的 U-Net 架构。此外,为了促进一致的 T2V 编辑,作者将光流引导注意力 (FLATTEN) 合并到 U-Net 模块中,而无需引入新参数。为了保持生成视频的高保真度,作者在潜在空间中使用了DDIM反转,并重新设计了U-Net来估计源视频的潜在噪声\(\textcolor{blue}{z_T}\)。首先使用空文本进行 DDIM 反转,而无需为源视频定义字幕。最后,使用 DDIM 过程生成一个编辑后的视频,其中包含来自潜在噪声 \(\textcolor{blue}{z_T}\) 和目标提示 \(\textcolor{blue}{τ}\) 的输入。如图 3 所示,FLATTEN框架是免训练的,因此可以轻松减少额外的计算。
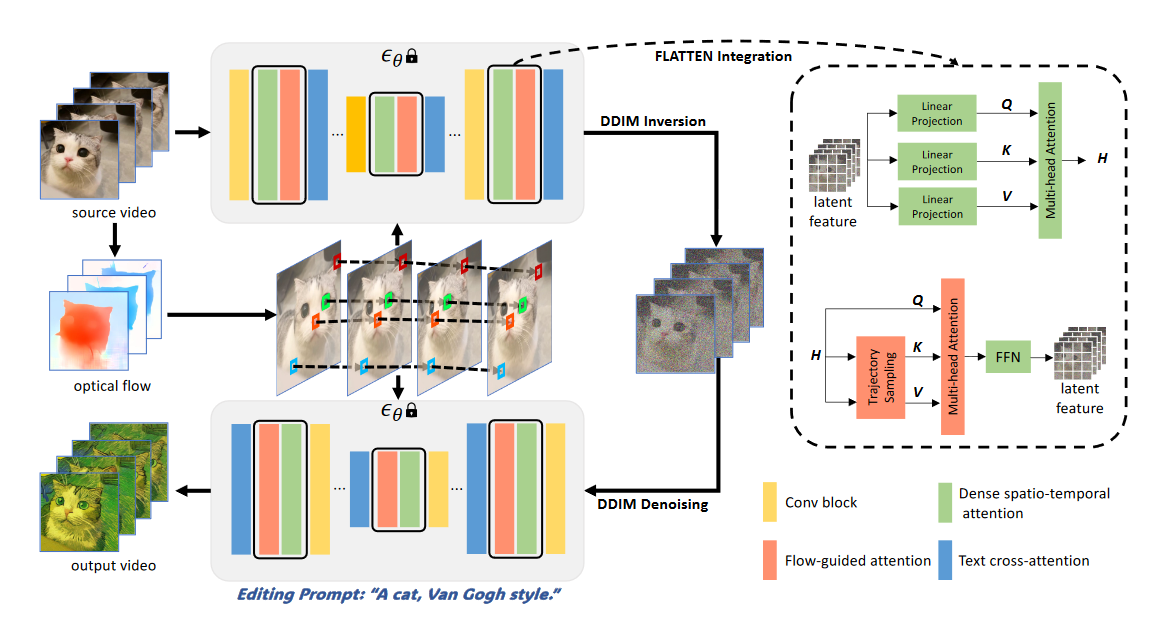
图3.框架概述:该框架沿时间轴膨胀了现有的 U-Net 架构,并将流引导注意力 (FLATTEN) 与密集的时空注意力相结合,以避免引入任何新参数。密集时空注意力\(H\)的结果进一步用于FLATTEN。FLATTEN 的Key和value是根据从光流采样的patches轨迹从 \(H\) 收集的。U-Net \(ε_θ\) 的权重被冻结。
🦁U-Net 扩展: 基于图像的扩散模型中采用的原始 U-Net 架构包括一堆 2D 卷积残差块、空间注意力块和包含文本提示嵌入的交叉注意力块。为了使T2I模型适应T2V编辑任务,作者扩展了卷积残差块和空间注意力块。通过添加伪时间通道,将卷积残差块中的 3 × 3 个卷积核转换为 1×3×3 个核。此外,空间注意力被密集的时空注意力范式所取代。与应用于单个帧中的patches的空间自注意力策略相比,采用整个视频中的所有patch embedding作为查询 (Q)、键 (K) 和值 (V)。这种密集的时空注意力可以在整个视频中提供全局的信息。请注意,新的密集时空注意力块中的线性投影层和前馈网络的参数是从原始空间注意力块中的参数继承而来的。
🐋FLATTEN 集成: 为了进一步提高输出帧的视觉一致性,作者将流引导注意力(Flow guided attention)集成到扩展的 U-Net 块中。并且将FLATTEN与密集的时空注意力结合起来,因为这两种注意力机制都是为了聚合视觉环境而设计的。
鉴于潜在的视频特征,首先进行密集时空注意力。采用特定的线性投影图层将latent features patches embedding分别转换为query、key和value。密集时空注意力的结果用\(H\)表示。为了避免引入新的可训练参数并保留特征分布,不应用新的线性变换来重新计算query、key和value。而是直接使用 \(H\) 作为流引导注意力的输入。请注意,没有引入位置编码。当patches embedding作为query时,根据从光流采样的patches轨迹,从密集时空注意力的输出中\(H\)得到相应的键和值。在执行流引导注意力后,输出从密集的时空注意力块转发到前馈网络。作者是通过在 DDIM 采样期间激活 FLATTEN,并且也在执行 DDIM inversion时也激活 FLATTEN,因为在 DDIM inversion中使用 FLATTEN 可以通过引入额外的时间依赖关系来更有效地inversion。
1.流引导注意力
光流估计:给定源视频中的两个连续RGB帧,使用RAFT来估计光流。两帧之间的光流表示密集的像素位移场\(\textcolor{blue}{(f_x, f_y)}\)。第\(\textcolor{blue}{k}\)帧中每个像素\(\textcolor{blue}{(x_k, y_k)}\)的坐标可以根据位移场投影到\(\textcolor{blue}{(k+1)}\)帧中的相应坐标。第\(\textcolor{blue}{(k+1)}\)中的新坐标可以表示为:
\[\huge (x_{k+1}, y_{k+1}) = (x_k+f_x(x_k,y_k),y_k+fy(x_k,y_k))\]
为了隐式地使用光流来引导注意力模块,需要将所有帧对的位移场下采样到潜在空间的分辨率。
Patch 轨迹采样:基于下采样\(\textcolor{blue}{(\hat{f_x},\hat{f_y})}\)对潜在空间中的patch轨迹进行采样。从第一帧的patch开始迭代,对于在第一帧上具有\(\textcolor{blue}{(x_0, y_0)}\)的patch,其在所有后续帧上的坐标都可以从位移场中导出。这些坐标是链接起来的,轨迹序列可以表示为:
\[\huge traj = {(x_0,y_0),(x_1,y_1),(x_2,y_2),...,(x_K,y_K)}\]
其中\(\textcolor{blue}{K}\)表示源视频的帧数。对于大小为\(\textcolor{blue}{H \times W}\)的潜在空间,理想情况下有一个轨迹集表示为\(\textcolor{blue}{\{traj_1,traj_2,...,traj_N\}}\),其中\(\textcolor{blue}{N = HW}\)。但是,某些patch会随着时间的推移而消失,并且视频中还会有新的patch出现。对于视频中出现的每个新patch,都会创建一个新的轨迹。因此,轨迹集N的大小通常大于\(\textcolor{blue}{HW}\)。为了简化流引导注意力的实现,当发生遮挡时,随机选择一条轨迹继续采样并停止其他相互冲突的轨迹。此策略可确保视频中的每个patch唯一地分配给单个轨迹,不会出现一个patch位于多个轨迹上的情况。
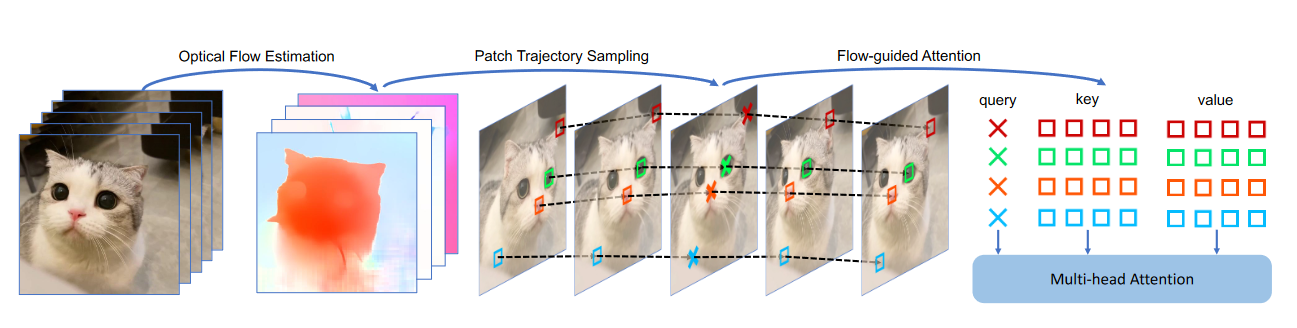
图4.FLATTEN的插图。第一步使用RAFT来估计源视频的光流,并将它们下采样到潜在空间的分辨率。基于位移场对潜在空间中patch的轨迹进行采样。对于每个query,从潜在特征中收集在同一条轨迹上的patch embedding的与之相应key和value。然后执行多头注意力,并更新patch embedding。
注意力过程:流引导注意力在采样的patch轨迹上执行。图4显示了FLATTEN的概述。从潜在特征 \(\textcolor{blue}{z}\) 得到相同轨迹上的patches embedding。轨迹\(\textcolor{blue}{traj}\)上的patch embedding 可以表示为:
\[\huge traj = {(x_0,y_0),(x_1,y_1),(x_2,y_2),...,(x_K,y_K)}\]
其中 \(\textcolor{blue}{z(x_k, y_k)}\) 表示embedding在第 \(\textcolor{blue}{k}\) 帧坐标 \(\textcolor{blue}{(x_k, y_k)}\) 处的patch。之后,在同一轨迹上的patch embeddings使用多头注意力。对于query \(\textcolor{blue}{z(x_k, y_k)}\),相应的key和value是同一轨迹 \(\textcolor{blue}{traj}\) 上的其他patch embedding。没有引入额外的位置编码。流引导注意力可以表述如下:
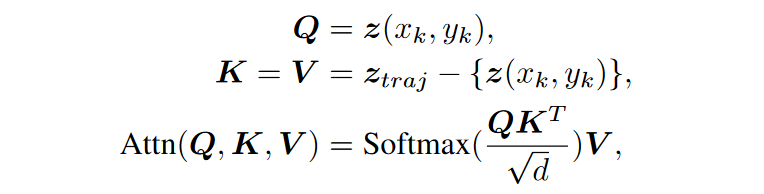
其中 \(\textcolor{blue}{\sqrt{d}}\) 是比例因子。通过流引导注意力对潜在特征 \(\textcolor{blue}{z}\) 进行更新,以消除密集时空注意力中不相关patches的特征聚合的负面影响。重要的是,这确保在patch轨迹采样期间,嵌入潜在特征的每个patch embedding都被唯一地分配给单个轨迹。此分配解决了冲突,并允许全面更新所有patch embedding。
利用光流连接不同帧中的patch,并对patch轨迹进行采样。流引导注意力促进了同一轨迹上的patches之间的信息交换,从而提高了视频编辑的视觉一致性。由FLATTEN 集成的框架下,无需任何额外训练即可实现文本到视频的编辑。此外,FLATTEN 还可以很容易地集成到任何基于扩散的 T2V 编辑方法中。
三、实验
1.实验设置
数据集:作者使用 53 个来自 LOVEUTGVE 的视频来评估该文本到视频编辑框架。这些视频中有 16 个来自 DAVIS,将此子集表示为 TGVE-D。其他 37 个视频来自 Videvo,表示为 TGVE-V。视频的分辨率重新缩放为 512 × 512。每个视频由 32 帧组成,标有真实字幕和 4 个用于编辑的创意文本提示。
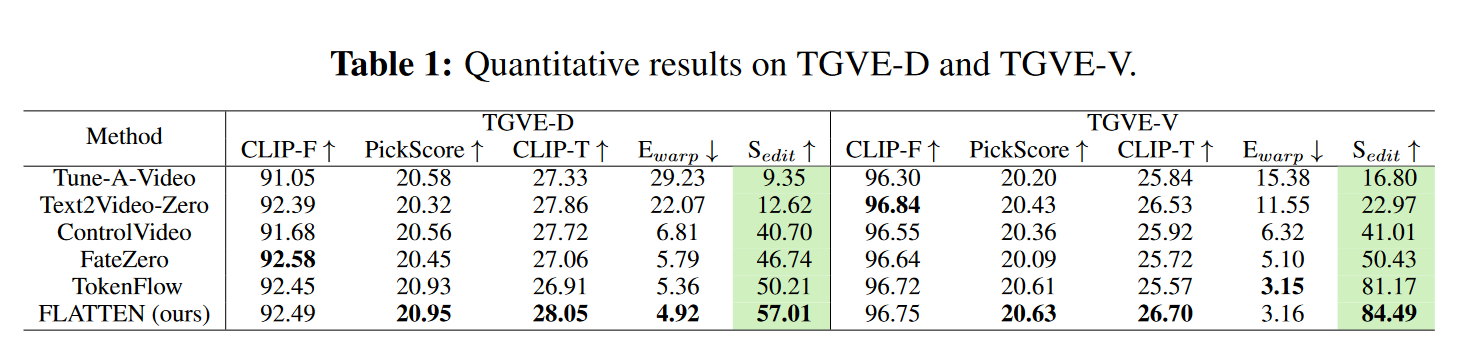
评估指标:本文使用以下自动评估指标:1️⃣ 对于文本对齐,使用 CLIP 来测量编辑帧和文本提示之间的平均余弦相似度,表示为 CLIP-T。2️⃣为了评估视觉一致性,我们采用了流歪曲误差\(E_{warp}\),它根据源视频的估计光流对编辑后的视频帧进行歪曲,并测量像素级差异。单独使用这些指标并不能全面代表编辑效果。例如,当编辑的视频完全是源视频时,Ewarp 报告 0 个错误。因此,3️⃣作者建议将 \(S_{edit}\) 作为主要评估指标,它将 CLIP-T 和 \(E_{warp}\) 组合为统一分数。具体来说,编辑分数的计算方式为 \(S_{edit} = CLIP-T/E_{warp}\)。4️⃣同时,还采用了 CLIP-F 和 PickScore,它们分别计算视频中所有帧之间的平均余弦相似度以及与人类偏好的估计一致性。为简洁起见,本文中显示的 CLIP-F/CLIP-T/Ewarp 数量按比例放大了 100/100/1000。
实现细节:作者扩展了一个预先训练的文本到图像扩散模型,并将 FLATTEN 集成到 U-Net 中,以实现 T2V 编辑,而无需任何训练或微调。为了估计源视频的光流,利用RAFT。在DDIM inversion中应用流引导注意力还可以通过引入额外的时间依赖性来改善潜在噪声估计。因此,在DDIM采样和 inversion中都使用流引导注意力。作者实现了 100 个 DDIM inversion时间步长和 50 个 DDIM 采样时间步长。按照图像编辑方法,扩散特征在DDIM inversion期间保存,并在采样过程中进一步注入。为了在修改后的 U-Net 中有效地执行密集的时空注意力,使用了 xFormers ,它可以减少 GPU 内存消耗。
2.定量比较
作者将该方法与 5 种公开可用的文本到视频编辑方法进行了比较:Tune-A-Video、FateZero)、Text2Video-Zero、ControlVideo和 TokenFlow。在这些方法中,Tune-A-Video需要对源视频进行微调。Tune-A-Video 和 FateZero 都需要源视频的额外字幕,而作者所提出的模型不需要。Text2Video-Zero和ControlVideo使用ControlNet来保存结构信息。在实验中,边缘图被用作条件,其性能优于深度图。TokenFlow 根据源视频特征的对应关系,线性组合扩散特征。
表1显示了TGVE-D和TGVE-V的定量比较。在两个数据集上,FLATTEN在 CLIP-T、PickScore 和编辑分数 Sedit 方面优于其他比较方法。在变形误差 \(E_{warp}\) 方面,FLATTEN比 TokenFlow 略低 \(0.1 × 10^{−3}\)。在考虑文本忠实度时,FLATTEN的 CLIP-T 分数明显更高。因此,FLATTEN总体上具有更高的编辑分数。Text2Video-Zero 具有较高的 CLIP-F 和 CLIP-T,但在视觉一致性方面表现不佳。尽管 FateZero 在 TGVE-D 上具有最高的 CLIP-F,但由于超参数设置问题,其输出视频有时与源视频非常相似。FLATTEN在所有评估指标上都表现出卓越的性能。
3.定性结果
定性比较如图 5 所示。顶部的源视频来自TGVE-D,底部的源视频来自TGVE-V。Tune-A-Video 生成每帧高质量的视频,但它很难保留源结构,例如,卡车数量错误。FateZero 有时无法根据提示编辑视觉外观,输出视频与源视频几乎相同,如上例所示。Text2Video-Zero 和 ControlVideo 都依赖于 ControlNet 提供的预先存在的功能(例如,边缘图)。如果源条件要素质量低下(例如,由于运动模糊),则会导致视频编辑质量整体下降。TokenFlow 对关键帧进行采样并执行特征的线性组合,以保持视觉一致性。但是,预定义的组合权重可能并不适合所有视频。在底部的示例中,白色太阳在 TokenFlow 编辑的帧中间歇性出现和消失。相比之下,FLATTEN可以根据提示生成一致的视频,并具有流引导的注意力。

图5.高级T2V编辑方法与FLATTEN之间的定性比较。第一列显示 TGVE-D(顶部)和 TGVE-V(底部)的源帧,而其他列显示通过不同方法编辑的相应帧。
4.即插即用 FLATTEN
FLATTEN 可以无缝集成到其他基于扩散的 T2V 编辑方法中。为了验证其兼容性,作者将 FLATTEN 合并到 ControlVideo 的 UNet 块中。使用 FLATTEN 编辑的 ControlVideo 视频的视觉一致性显著提高,如图 6 所示。使用FLATTEN时,由原始ControlVideo编辑的底帧中的鱼(青色框)会消失,从而确保一致的视觉外观。在TGVE-D上使用FLATTEN评估了ControlVideo。加入FLATTEN之后,\(E_{warp}\)的变形误差从6.81显著降低到4.78,而CLIP-T从27.72略微降低到26.97。\(S_{edit}\)的编辑得分从40.70提高到56.42,这表明FLATTEN可以提高其他T2V编辑方法的视觉一致性。

图6.FLATTEN 还可以提高其他方法的视觉一致性。
5.消融实验
为了验证不同模块对整体性能的贡献,停用了框架中的特定模块。最初,从框架中消融了密集时空注意力(DSTA)和流引导注意力(FLATTEN)。在预训练图像模型中,密集的时空注意力被原始的空间注意力所取代。这被视为我们的基线模型(Base)。如图 7 所示,编辑后的结构有时会失真。然后单独激活 DSTA 和 FLATTEN。它们都可以推理时间依赖关系,并增强结构保留和视觉一致性。

图7.流动引导注意力(FLATTEN)和密集时空注意力(DSTA)有效性的定性结果。本文还探索了 FLATTEN 和 DSTA 的两种组合。为了轻松比较视觉一致性,放大了不同帧中的鼻子区域。在右下角的画面中,结构和着色在时间上都是一致的。
作为进一步,以两种不同的方式将DSTA和FLATTEN结合起来,并探索它们的有效性:(I)将密集时空注意力的输出转发到线性投影层,以重新计算FLATTEN的query、key和value;(II) DSTA 的输出直接用作 FLATTEN 的query、key和value。我们发现第一种组合有时会导致模糊,从而降低编辑质量。第二种组合性能更好,并被采用为最终解决方案。TGVE-D消融研究的定量结果见表2。

四、总结
本文提出了 FLATTEN,这是一种新颖的流程引导注意力,可提高文本到视频编辑的视觉一致性,并提出了一个无需训练的框架,可在现有 T2V 编辑基准上实现新的最先进性能。此外,FLATTEN 还可以无缝集成到任何其他基于扩散的 T2V 编辑方法中,以提高其视觉一致性。本文进行了全面的实验,以验证该方法的有效性,并对文本到视频编辑的任务进行基准测试。本文的方法展示了卓越的性能,特别是在保持编辑视频的视觉一致性方面。