
不成对的图像到图像(Unpaired I2I)转换——仅使用不成对的训练数据将图像从某个输入域转换到输出域的任务在医学图像分析中提供了广泛的应用。一个重要的案例是促进不同成像模式(例如 CT 和 MRI)之间的分割,适用于大脑、腹部和骨盆等解剖位置。由于在每种单独模态中注释图像需要大量的时间和劳动力投入,因此这一点特别有用,因为一种模态的注释可以直接应用于翻译成另一种模态的图像。然而,这样做需要通过翻译保持解剖学的一致性。
确保不配对 I2I 翻译的解剖学一致性具有挑战性,特别是当输入和输出域表现出严重的结构偏差时。一个例子是标准检查中捕获的腿部和脊柱区域的 CT 和 MRI 之间的巨大视觉差异(如图 1所示),其中通常 CT 图像显示两条腿,而 MRI 扫描仅显示一条腿,CT 图像捕获整个腹部,而MRI 分别聚焦于腰部区域。由于翻译模型学习这些结构偏差,缺乏这种一致性可能会导致翻译图像与其相应的分割掩模之间不对齐,从而可能导致在翻译图像上训练的分割模型不可靠。事实上,当模态之间存在如此严重的不一致时,像 CycleGAN 这样的流行翻译方法可能会产生不良结果。
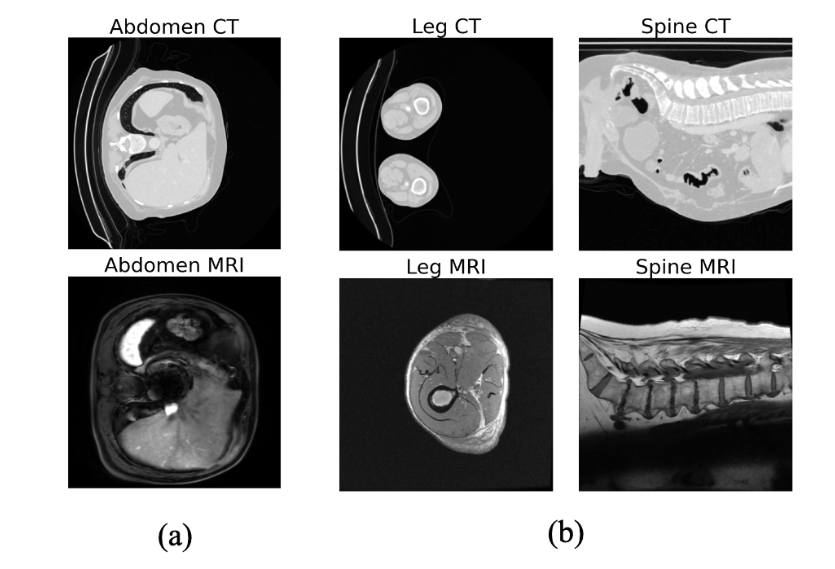
图1:在某些解剖区域,CT 和 MRI 模式之间存在结构偏差:从轴向视图 (a) 来看,腹部区域的偏差较小,但从轴向视图来看,腿部的偏差很严重;从矢状视图来看,脊柱区域的偏差很严重 (b)。
受到先前空间条件扩散模型研究的启发,本文提出了一种平移扩散模型“ContourDiff”,它使用图像的域不变解剖轮廓表示来指导翻译过程,即使在模态之间也能保证精确的解剖一致性严重的结构性偏差。该模型还有一个额外的好处,即它是“无源”的:它只需要一组未标记的输出域图像进行训练。因此,它可以在推理时翻译来自任意看不见的输入域的图像。据作者所知,这是第一个不需要输入域信息进行训练的不配对图像翻译模型。
二、方法
问题定义:在不配对图像翻译中,只有输入和输出域示例的不配对数据集可用于训练。本文的方法实现了无源图像转换,其中只有未标记的数据集 \(\textcolor{blue}{N_{out}}\) 输出域(示例 \(\textcolor{blue}{x^{out}_n (n = 1, ..., N_{out}) }\))可用于训练。然后,目标是在推理时使用经过训练的模型将未见过的输入域数据 \(\textcolor{blue}{x^{in}_n}\) 转换到输出域。在本文的案例中,目标是将 CT 图像转换为 MRI 领域,以便与 MRI 训练的分割模型一起使用。为此,作者提出了一种新颖的基于扩散模型的图像翻译框架,该框架基于图像的域不变解剖轮廓表示。
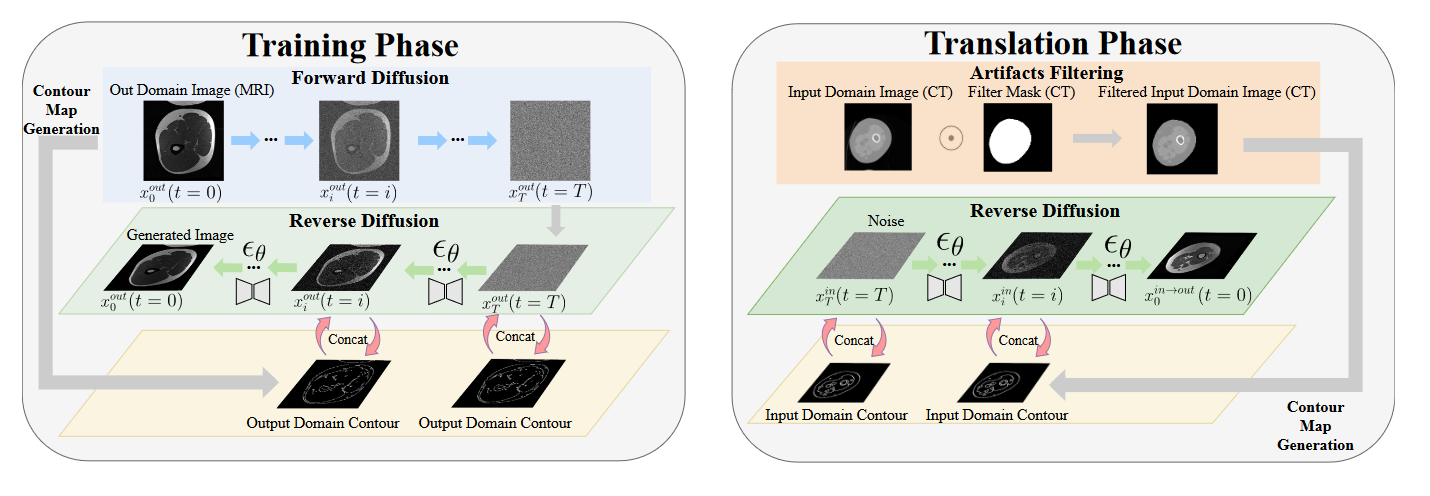
图2:ContourDiff 架构图。
1.向扩散模型添加轮廓引导
对于标准扩散模型,如何约束生成图像的语义/解剖结构尚不清楚。为了解决这个问题,作者建议利用图像的轮廓表示来提供生成图像的指导。在训练模型时,使用 Canny 边缘检测滤波器提取每个训练图像 \(\textcolor{blue}{x_0}\) 的轮廓表示 \(\textcolor{blue}{c}\),并将其与每个去噪步骤的网络输入连接起来,这种做法类似于SegGuidedDiff、ControlNet。这将网络修改为 \(\textcolor{blue}{ε_θ(x_t, t|c)}\) 并将扩散训练目标修改为
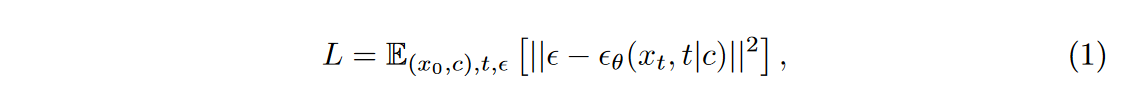
其中\(\textcolor{blue}{(x_0, c)}\) 是训练集图像及其轮廓。
2.轮廓引导图像翻译
轮廓的一个重要特征是它们可以被视为域不变但保留解剖结构的图像表示。这允许在某些输出域中训练的轮廓引导扩散模型充当无源图像转换方法,如下所示。
首先,在带有计算轮廓 \(\textcolor{blue}{(x^{out}_n, c^{out}_n) }\)的输出域图像上训练轮廓引导扩散模型,如算法 1 所示。接下来,为了将一些输入域图像 \(\textcolor{blue}{x_{in}}\) 转换到输出域,提取其轮廓 \(\textcolor{blue}{c_{in}}\)使用Ffilter去除不相关背景后,使用以 \(\textcolor{blue}{c_{in}}\) 为条件的输出域训练模型 \(\textcolor{blue}{ε_θ}\) 生成图像 \(\textcolor{blue}{x^{in→out}_0}\)。因此,\(\textcolor{blue}{x^{in→out}_0}\) 保持了 \(\textcolor{blue}{x_{in}}\) 的解剖内容,同时拥有输出域的视觉域特征。该翻译算法如算法 2 所示,其中 \(\textcolor{blue}{α_t = 1−β_t}\) 具有加性预调度噪声 \(\textcolor{blue}{β_t}\) 的方差,且\(\textcolor{blue}{\bar{α}_t = \prod^t_{s=1} α_s}\)。

过滤掉图像伪影。作者还对所有网络输入图像 \(\textcolor{blue}{x}\) 应用额外的预处理,以过滤掉非解剖特征/伪影(例如 CT 中的电动床),通过应用二进制掩码 \(\textcolor{blue}{M_{filter}}\) 作为 \(\textcolor{blue}{x ← M_{filter} ⊙ x}\)。 \(\textcolor{blue}{M_{filter}}\) 是通过在 \(\textcolor{blue}{x}\) 上顺序计算以下 Scikit-Image 函数来定义的:threshold_multiotsu、binary_erosion、remove_small_objects 和 remove_small_holes。
强制相邻切片的翻译一致性。此外,作者建议强制将从 3D 图像(例如 CT)获取的相邻输入域图像切片转换到输出域的一致性,如下所示。首先,将 3D 体积中的第一个切片图像 \(\textcolor{blue}{x^{in}_1}\) 转换为其输出域版本 \(\textcolor{blue}{x^{in→out}_1}\)。重复生成,直到生成的一幅图像的平均值小于指定的阈值 \(\textcolor{blue}{m_{thresh}}\)。然后,通过生成不同的候选翻译 \(\textcolor{blue}{x^{in→out}_i}\)(使用模型的不同采样噪声输入)来翻译连续的切片 \(\textcolor{blue}{x^{in}_i (i = 2, . . . , N_{slices})}\),直到一个在 \(\textcolor{blue}{δ}\) 的 \(\textcolor{blue}{L_2}\) 距离内。先前的切片翻译 \(\textcolor{blue}{x^{in→out}_{i-1}}\),并将其用于最终的\(\textcolor{blue}{x^{in→out}_i}\)。作者分别对腰椎使用 \(\textcolor{blue}{m_{thresh} = 110}\)、\(\textcolor{blue}{δ = 50}\),对臀部/大腿解剖视图使用 \(\textcolor{blue}{m_{thresh} = 100}\)、\(\textcolor{blue}{δ = 40}\)。在每次迭代期间,如果多个候选满足 \(\textcolor{blue}{L_2}\) 距离标准,作者选择 \(\textcolor{blue}{δ}\) 最小的一个。每次迭代生成 4 个候选,最多允许 5 次尝试;如果此后没有候选人满足指定要求,将选择 \(\textcolor{blue}{δ}\) 最小的候选人。
三、实验
1.实验设置
数据集。在本文中,我们研究最常见的转换场景之一:CT 到 MRI。对于训练轮廓引导扩散模型的 MRI 数据集,收集具有 T-1 加权腰椎 (L) 和臀部和大腿 (H&T) 身体区域的私有数据集。选择 40 个矢状腰椎 MRI 体积(670 个 2D 切片)和来自大腿和臀部的 10 个轴向 MRI 体积(404 个 2D 切片)。相应地,分别从 L 和 H&T 中的 TotalSegmentator 项目 获得 54 个矢状(2,333 个 2D 切片)和 29 个轴向(4,937 个 2D 切片)CT 体积。该实验设置模仿了利用外部标签信息来加速内部数据集的注释过程的重要现实应用。为了训练骨分割的下游任务模型,作者进一步按患者随机分割两个 CT 集(L 为 43:11,H&T 为 23:6)进行训练和验证。使用保留的带注释的 MRI 集(10 L 体积,包括 158 个 2D 切片,12 H&T 体积,包括 426 个 2D 切片)评估分割模型的测试性能。此外,为了研究该方法的泛化能力,在 SPIDER 腰椎 (L-SPIDER) 公共数据集 的 40 个体积(731 个 2D 切片)上测试了腰椎分割模型。
评估指标。对于评估指标,使用 Dice 系数 (Dice) 和平均对称表面距离 (ASSD) 定量评估翻译图像上的 MRI 分割模型性能。由于没有配对图像,作者计算了翻译图像和真实输出域图像分布之间的 FID 以供参考,尽管我们发现它没有捕获全局解剖真实性。
实施细节。对于图像翻译模型,作者采用UNet架构作为具有两通道输入(灰度图像及其轮廓)的去噪模型 \(\textcolor{blue}{ε_θ}\)。扩散模型的训练设置与SegGuidedDiff中的相同。作者使用DDIM算法进行采样,有50步。对于分割模型,使用基于卷积的 UNet 和基于 Transformer 的 SwinUNet 。所有图像的大小均调整为 256 × 256 并标准化为 [0, 255]。对于其他基线的训练,大多遵循各个官方GitHub的默认设置。如果提供了方法,训练最多 200 个 epochs,并设置 \(λ_{idt} = 0.5\) 以包含identity loss。对于 CycleGAN 和 MaskGAN,使用余弦学习率调度器训练分割模型,最多 100 个时期,初始学习率为 \(1 × 10^{−3}\)。
2.图像翻译性能
与其他方法的比较。通过输出域训练的下游任务分割模型在翻译图像上的性能,将本文的框架与其他翻译/适应方法进行比较,包括 CycleGAN、SynSeg-Net、CyCADA 和 MaskGAN。 CycleGAN 和 SynSeg-Net 仅在图像级别转换图像,而 CyCADA 还对齐下游任务模型编码器的潜在特征输出。 MaskGAN 结合了自动提取的粗掩模,以便在将输入图像转换到输出域时更好地保留结构。对于 CyCADA, 作者利用与其他模型相同的分段架构,没有跳过连接来实现特征级对齐。就其他方法而言,根据图像转换器在多个训练时期生成的图像来训练和评估分割模型的性能,并报告最佳模型。作者表示:这些方法都是不配对的(在输入和输出域图像上训练),而我们的无源方法只需要输出域图像进行训练;这是因为没有其他无源图像级适应(翻译)方法可以比较,因为本文的方法是同类中的第一个。
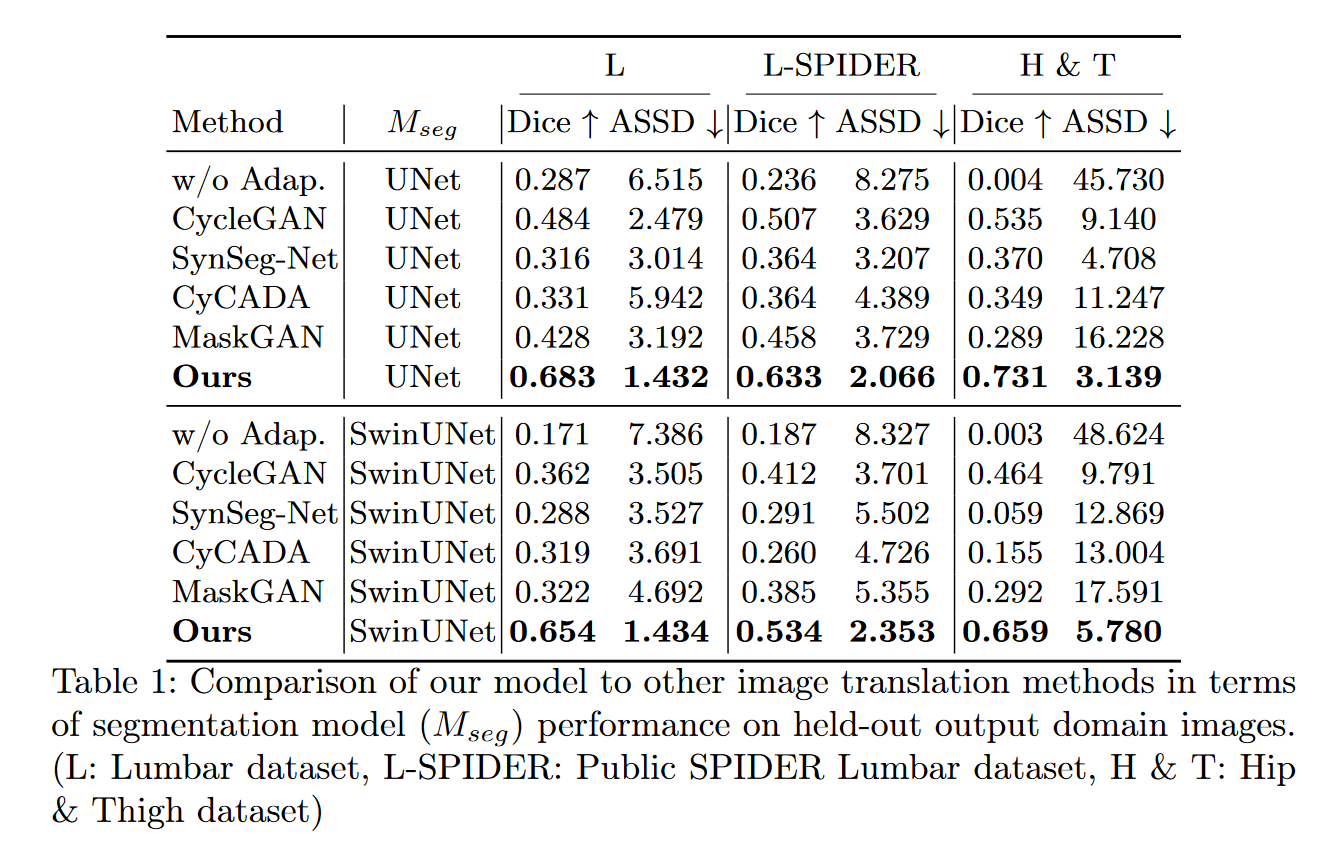
分割模型结果如表 1 所示。“w/o Adap”。是一个基线,指的是在 CT 上训练的模型,无需任何调整,并直接在 MRI 上进行测试。对于三个测试集,本文的方法明显优于以前的图像适应方法:例如,UNet 的 L、L-SPIDER 和 H&T 的输出域模型 Dice 分别高出至少 0.199、0.126 和 0.196。
在图 3 中提供了示例图像翻译。这些数据集构成了一项具有挑战性的任务,因为 (1) 输入域和输出域之间图像特征的显着变化以及 (2) 不同扫描之间的高解剖变异性。
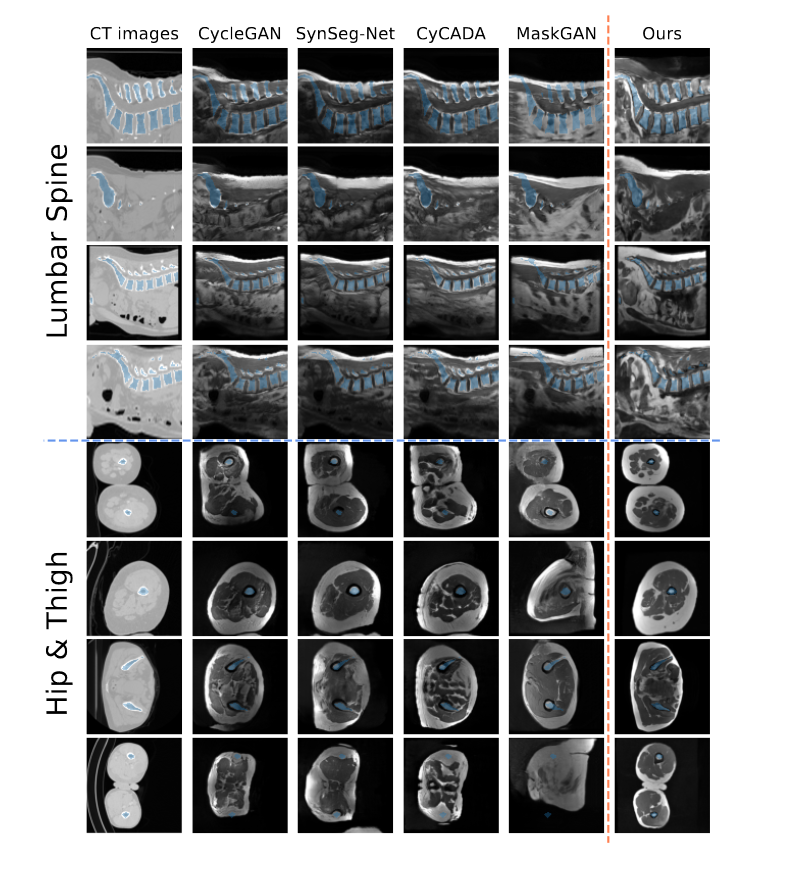
图3:根据不同翻译模型的腰部、髋部和大腿区域的 CT 生成 MRI。原始 CT 中的掩模(蓝色)被添加到所有生成的图像中以可视化对齐情况。
此外,作者还发现对抗训练模型(例如 CycleGAN)在输入域和输出域之间存在一致的结构偏差方面存在问题,即当一个域缺乏在另一个域中看到的某些特征时。如图 1 和附录 D.1、D.2、D.3 和 D.4 所示,这在H&T 数据集中尤其明显,其中 MRI 以单腿为主,而 CT 通常包含两条腿。这种偏见可能会导致对抗机制过度强调这些特征,因此倾向于将两条腿的 CT 转化为仅描绘一条腿的 MRI。对于从矢状面看的腰椎,MRI 通常从最低的胸椎开始,到骶骨结束。另一方面,CT 通常包括大腿,有时还包括腹部。尽管通过轮廓引导存在这些域特征差异,本文的模型通过翻译明确地强制执行解剖学一致性,生成严格遵循输入 CT 图像的 MRI,从而实现更好的掩模对齐和更好的分割模型性能。
此外,FID 分数似乎不能可靠地反映翻译后的输出域图像和实际输出域图像之间的解剖学一致性。根据表 1 和表 3,尽管在 FID 中获得了最高分数,但与其他模型相比,ContourDiff 的翻译图像在定量和定性方面似乎都最符合解剖保真度。
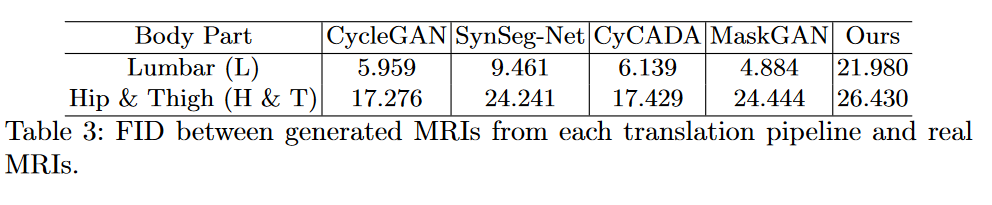
消融研究。 (1) 通过在空图(即全零)上进行条件训练并在翻译步骤中添加 CT 轮廓来验证在训练期间将轮廓引入每个去噪步骤的有效性。图 4 显示,在没有轮廓的情况下训练的去噪模型 \(\textcolor{blue}{ε_θ}\) 很难遵循引入的 CT 轮廓。此外,在这些无条件生成的 MRI 上训练的 UNet 的性能出现了急剧下降(参见附录 A)。 (2) 直接生成图像(即通过单个候选),而不强制相邻切片的翻译一致性。定性结果显示,使用单个候选图像生成的图像质量有所下降(参见附录 B)。
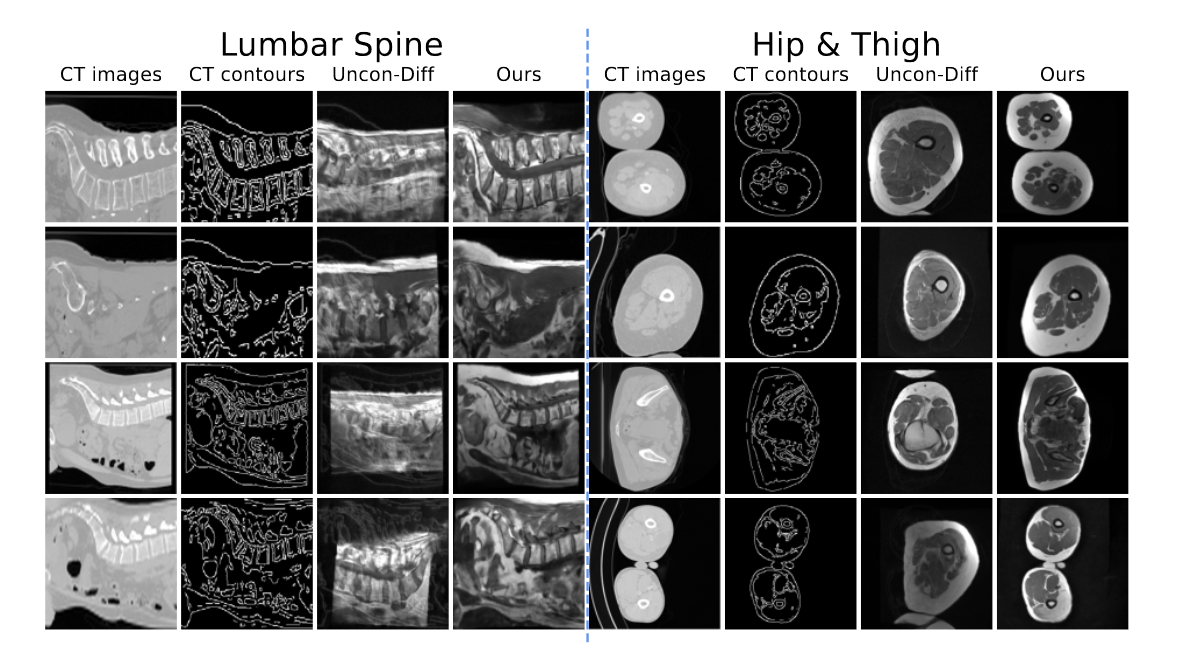
图4:消融研究1:无条件扩散模型与轮廓引导扩散模型生成的图像比较
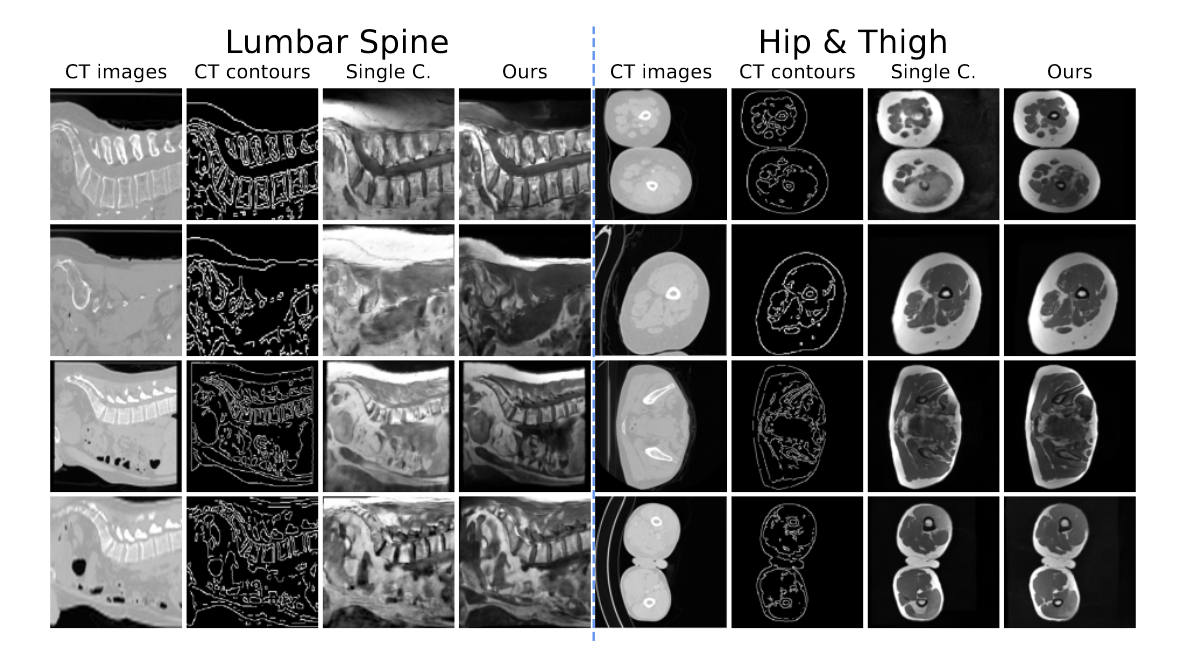
图5:消融研究2:比较单个候选(Single C.)生成的图像,而不使用多个候选进行选择和生成
四、结论
在本文中,作者引入了一种新颖的框架(ContourDiff)来保持不成对图像翻译中的解剖保真度。本文的方法限制输出域中生成的图像与输入域图像的解剖轮廓对齐。医学数据集的定量和定性结果都表明,ContourDiff 在维护解剖结构方面明显优于多种现有的图像翻译方法。