

一、介绍
视频虚拟试穿(try-on)旨在以视频序列的形式将给定的衣服穿在目标人身上。它的目标是需要保持衣服的外观和人的动作。这是为消费者提供了互动体验,使他们能够探索服装选择,而不需亲自试穿,这引起了时尚界和消费者的关注。
虽然关于视频试穿的研究并不多,但基于图像的试穿已经得到了广泛的研究。许多工作依赖于生成对抗网络(GAN)。这些方法通常包括两个主要组件:一个扭曲模块(warping module)用于扭曲衣服以在语义层面上适合人体,以及一个将扭曲的衣服与人体图像融合的试穿生成器。近年来,随着扩散模型的发展,图像和视频生成的质量得到了显著提高。已经提出了一些基于扩散的图像虚拟试穿方法,这些方法没有明确地包含扭曲模块,而是将扭曲和混合过程集成到一个统一的流程中。利用预先训练的文本到图像扩散模型,这些基于扩散的模型实现了超过基于 GAN 的模型的保真度。
很明显,与图像试穿相比,视频试穿可以更全面地展示不同条件下的试穿服装。比较直接的方法是应用图像试戴方法逐帧处理视频。但是,这会导致严重的帧间不一致,从而导致不可接受的生成结果。视频试穿的主要挑战是保留服装的精细细节,同时产生连贯的动作。
在本文中,为了解决复杂自然场景中的上述挑战,作者提出了一种称为”Tunnel Try-on“的新框架。从基于图像的虚拟试妆的强大基线开始。它利用一个修复UNet(记为Main U-Net)作为主分支,并利用参考U-Net(记为Ref U-Net)来提取和注入给定服装的细节。通过在主 U-Net 的每个阶段后插入 Temporal-Attention,并扩展了该模型以在视频中进行虚拟试穿。然而,这种基本解决方案不足以处理真实视频中具有挑战性的案例。
特别的,人类在视频中经常占据一小块区域,并且该区域或位置可能会随着摄像机的移动而剧烈变化。因此,作者建议在给定的视频中挖掘一条“Tunnel”,以提供服装区域的稳定特写镜头。具体来说,我们在每一帧中进行区域裁剪,并放大裁剪区域,以确保个体适当居中。这种策略最大限度地提高了模特保留参考服装精细细节的能力。同时,利用卡尔曼滤波技术重新计算裁剪框的坐标,并将焦点隧道的位置嵌入注入到时间注意力中。通过这种方式,我们可以保持裁剪视频区域的平滑度和连续性,并帮助生成更一致的运动。此外,尽管隧道内的区域值得更多关注,但外部区域可以为服装周围的背景提供全球背景。因此,作者开发了一种环境编码器(environment encoder)。它提取隧道外的全局高级特征,并将它们合并到主UNet中,以增强背景生成。

图1.生成隧道试穿结果:Tunnel Try-on模型在视频试穿任务中实现了最先进的性能。它不仅可以处理复杂的服装和背景,还可以适应视频中不同类型的人体运动(第一排和第二排)和摄像机角度变化(第三排)。
二、方法
1.总体架构
Tunnel try-on整体架构如图2所示。
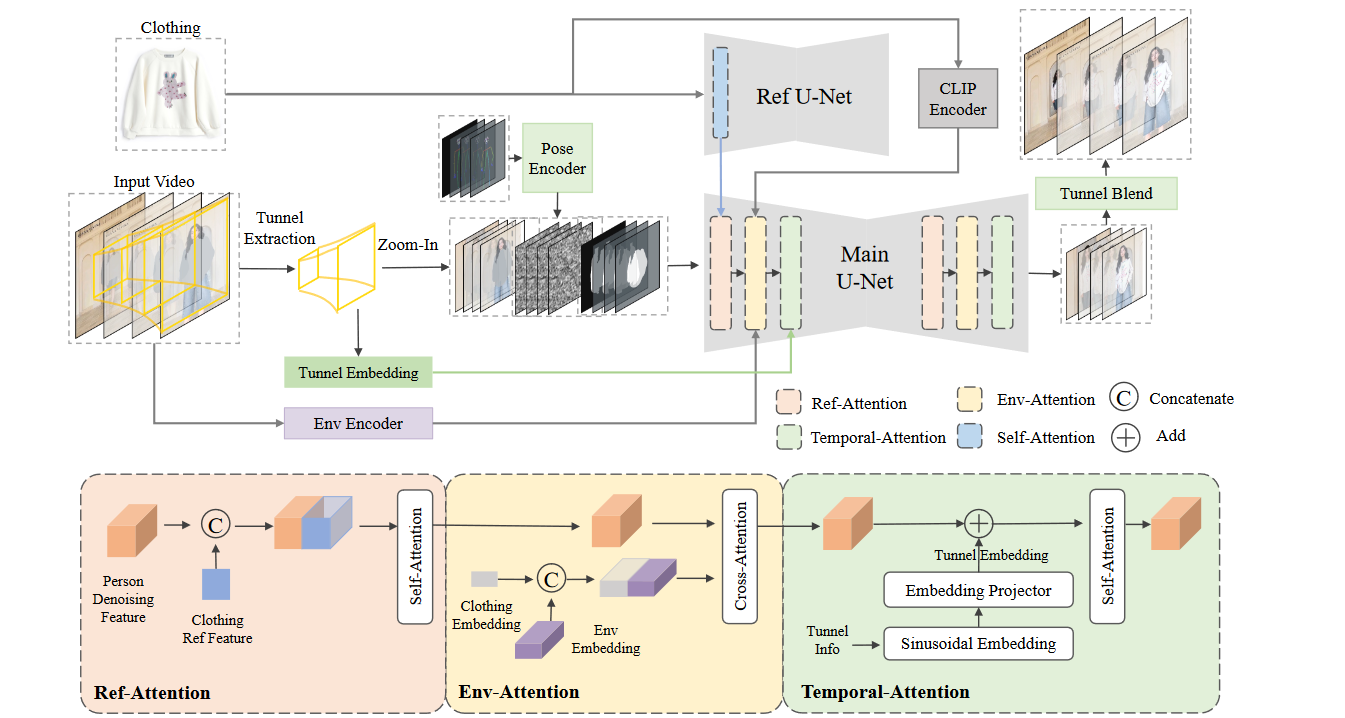
图2.给定输入视频和服装图像,首先提取对焦通道(focus tunnel)以放大服装周围的区域,以更好地保留细节。缩放区域由一系列张量表示,这些张量由背景潜在噪声、潜在噪声和服装掩码组成,这些张量被连接并馈送到主 U-Net 中。同时,使用 Ref U-Net 和 CLIP 编码器来提取服装图像的表示。然后,使用 ref-attention 将这些服装表示添加到主 U-Net。此外,将人体姿态信息添加到潜在特征中以协助生成。隧道嵌入(Tunnel embedding)也被集成到时间注意力中,以产生更一致的运动,并开发了一个环境编码器来提取全局上下文作为额外的指导。
1️⃣Image try-on baseline:Tunnel Try-on 的基线(灰色模块)由两个 U-Net 组成:主 UNet 和 Ref U-Net。主 U-Net 使用修复模型进行初始化。文献U-Net已被证明在保存参考图像的详细信息方面是有效的。因此,Tunnel Try-on 利用 Ref U-Net 对参考服装的细粒度特征进行编码。此外,Tunnel Try-on 还使用 CLIP 图像编码器来捕获目标服装图像的高级语义信息,例如整体颜色。具体来说,主 U-Net 采用形状为 B × 9 × H × W 的 9 通道张量作为输入,其中 B、H 和 W 表示批量大小、高度和宽度。9 个通道由衣服遮掩视频帧(4 个通道)、潜在噪声(4 个通道)和服装掩码掩码(1 个通道)组成。为了增强对生成视频运动的指导并进一步提高其保真度,将姿态(pose)贴图作为额外的控制调整。这些姿态图由包含多个卷积的姿态编码器编码(pose Encoder),被添加到潜在空间中的串联(concatenated)特征中。
2️⃣Adaption for videos:为了调整图像试穿模型以处理视频,在主 U-Net 的每个阶段后插入 Temporal-Attention。具体来说,Temporal Attention 对不同帧中相同空间位置的特征进行自注意力机制,以确保帧之间的平滑过渡。主U-Net的特征图以f的时间维度扩展,表示帧。因此,输入形状变为 B × 9 × f × H × W 。如 Ref-Attention 所示,来自 Ref U-Net 的特征图将重复 f 次(特征图维度变成[(B * f) x 9 x h x w]),并沿空间维度进一步连接。随后,沿空间维度展平后,将串联的特征输入到自注意力模块中,输出的特征仅保留原始去噪特征图部分。
3️⃣Novel designs of Tunnel Try-on:在输入视频中挖掘了一个焦点隧道,并放大了该区域以强调服装。为了增强视频的一致性,利用卡尔曼滤波器对隧道进行平滑处理,并将隧道嵌入到时间注意力层中。同时,设计了一个环境编码器(图 2 中的 Env 编码器)来捕获每个视频帧中的全局上下文信息作为补充线索。这样,主U-Net主要利用三种类型的注意力模块来整合不同层次的控制条件,增强生成视频的时空一致性。这些模块如图 2 底部彩色框所示。以下各节将详细介绍每个新模块。
2.聚焦隧道提取(Focus Tunnel Extraction)
在典型的图像虚拟试穿数据集中,目标人物通常居中并占据图像很大的一部分。然而,在视频虚拟试穿中,由于人物的移动和摄像机的平移,视频帧中的人可能会出现在边缘或占据较小的部分。这可能会导致视频生成结果的质量下降,并减少保持服装当中的内容以及细节。为了增强模型保留细节的能力并更好地利用从图像试穿数据中学习的训练权重,作者提出了”焦点隧道策略“,如图2所示。
具体来说,根据试穿服装的类型,利用姿势图来识别上半身或下半身的最小边界框。然后,根据预定义的规则扩展获得的边界框的坐标,以确保覆盖所有衣服。由于扩展的边界框序列类似于以人为中心的信息隧道,因此作者将其称为输入视频的“焦点隧道”。接下来,放大隧道:对焦通道中的视频帧进行裁剪、填充并调整为输入分辨率。然后将它们组合在一起,形成主UNet的新序列输入。然后,使用高斯模糊将主U-Net生成的视频输出与原始视频混合,以实现自然集成。
3.聚焦隧道增强(Focus Tunnel Enhancement)
由于对焦通道提取过程仅在单个帧内计算,而不考虑帧间关系,因此在应用于视频时,由于人员和摄像机的移动,边界框序列可能会出现轻微的抖动或跳跃。与自然捕获的视频相比,这些抖动和跳跃会导致焦点隧道看起来不自然,从而增加了时间注意力收敛的难度,并导致生成的视频中时间一致性降低。为了应对这一挑战,作者提出了隧道平滑(Tunnel smoothing)和将隧道嵌入(Tunnel embedding)到注意力层中的方法。
Tunnel smoothing:为了平滑对焦通道并实现类似于自然相机运动的变化效果,作者提出了对焦通道平滑策略。具体来说,首先使用卡尔曼滤波来校正焦点隧道,可以表示为算法 1。

\(\textcolor{blue}{\hat{x}_t}\) 表示时间 \(\textcolor{blue}{t}\) 处焦点隧道的平滑坐标,使用卡尔曼滤波的预测方程计算。\(\textcolor{blue}{x_t}\) 表示隧道在时间 \(\textcolor{blue}{t}\) 处的观测位置,即平滑前隧道的坐标。在卡尔曼滤波器之后,使用低通滤波器进一步滤除由特殊情况引起的高频抖动。
Tunnel embedding:对焦通道的输入形式增加了相机运动的幅度。为了减轻时间注意力模块在平滑如此重要的摄像机运动方面面临的挑战,作者引入了隧道嵌入。隧道嵌入接受三元组输入,包括原始图像大小、隧道中心坐标和隧道大小。受SDXL中分辨率嵌入设计的启发,隧道嵌入首先将三元组编码为一维绝对位置编码,然后通过线性映射和激活函数获得相应的嵌入。随后,将焦点隧道嵌入作为位置编码添加到时间注意力中。通过隧道嵌入,时间注意力集成了有关对焦通道大小和位置的详细信息,有助于防止因相机移动过大而影响的焦点通道错位。此增强功能有助于提高对焦通道内视频生成的时间一致性。
4.环境要素编码(Environment Feature Encoding)
应用焦点隧道策略后,上下文往往会丢失,这给在遮罩区域内生成合理的背景带来了挑战。为了解决这个问题,作者提出了环境编码器。它由一个冻结的 CLIP 图像编码器和一个可学习的线性映射层组成。最初,屏蔽的原始图像由冻结的 CLIP 图像编码器编码,以捕获有关环境的整体信息。随后,通过可学习的线性投影层对输出 CLIP 特征进行微调。如图 2 的 Env-Attention 所示,Environment Encoder 的输出特征作为键和值,通过交叉注意力注入到去噪过程中。
5.Train and Test Pipeline
Training process:训练阶段可分为两个阶段。🅰在第一阶段,模型排除了时间注意力、环境编码器和隧道嵌入。此外,冻结了VAE编码器和解码器(为简单起见,在图2中省略)以及CLIP图像编码器的权重,并且仅更新主U-Net,Ref U-Net和姿态引导器的参数。在此阶段,模型使用配对图像试戴数据进行训练。本阶段的目标是学习使用与视频数据相比更大、更高质量、更多样化的配对图像数据来提取和保存服装特征,旨在实现高保真图像级试穿生成结果作为坚实的基础。
🅱在第二阶段,所有策略和模块都被合并,模型在视频试戴数据集上进行训练。在此阶段,仅更新 Temporal-Attention, Environment Encoder 的参数。此阶段的目标是利用第一阶段学习的图像级试妆功能,同时使模型能够学习与时间相关的信息,从而在试妆视频中实现高度的时空一致性。
Test process:在测试阶段,输入视频进行隧道提取以获得焦点隧道。然后,输入视频与条件视频一起放大对焦通道并馈送到主 U-Net。在 Ref U-Net、CLIP 编码器、环境编码器和隧道嵌入的输出引导下,主 UNet 逐渐从噪声中恢复试戴视频。最后,对生成的试戴视频进行Tunnel-Blend后处理,获得所需的完整试戴视频。
三、实验
1.数据集
作者在两个视频试戴数据集上评估了Tunnel Try-on:VVT数据集和作者收集的数据集。VVT 数据集是一个标准的视频虚拟试穿数据集,包括 791 个配对人物视频和服装图像,分辨率为 192×256。视频中的模特在纯白色背景上有相似而简单的姿势和动作,而衣服都是合身的上衣。由于这些限制,VVT数据集无法反映视觉视频试戴的真实应用场景。因此,作者从真实的电子商务应用场景中收集了一个数据集,该数据集具有复杂的背景、多样化的动作和身体姿势以及各种类型的服装。该数据集由5,350个视频-图像对组成。作者将其分为 4,280 个训练视频和 1,070 个测试视频,每个视频分别包含 776,536 帧和 192,923 帧。
2.实施细节
模型配置:主 U-Net 使用 Stable Diffusion-1.5 的修复模型权重进行初始化。Ref U-Net 使用标准文本到图像 SD-1.5 进行初始化。Temporal-Attention 是从 AnimateDiff 的运动模块初始化的。
训练和测试设置:训练阶段分为两个阶段。在这两个阶段,将输入调整大小并填充到 512x512 像素的统一分辨率,并采用 1e-5 的初始学习率。这些模型在 8 个 A100 GPU 上进行训练。在第一阶段,利用从视频数据中提取的图像试穿对,并将它们与现有的图像试戴数据集VITON-HD 合并进行训练。然后,对视频中由 24 帧组成的剪辑进行采样,作为第 2 阶段训练的输入。在测试阶段,使用时间聚合技术来组合不同的视频片段,从而产生更长的视频输出。
3.与现有替代方案的比较
作者在VVT数据集上与其他视觉试穿方法进行了全面比较,包括定性、定量比较和用户研究。其中收集了几种视觉试穿方法,包括基于GAN的方法,如FW-GAN、PBAFN和ClothFormer,以及基于扩散的方法,如Anydoor和StableVITON。为了确保公平的比较,作者利用VITON-HD 数据集进行第一阶段训练,并在VVT 数据集上进行第二阶段训练,而不使用作者自己的数据集。
图 3 显示了各种方法在 VVT 数据集上的定性结果。从图 3 中可以明显看出,基于 GAN 的方法(如 FW-GAN 和 PBAFN)利用翘曲模块,难以有效适应视频中个体大小的变化。只有在特写镜头中才能获得令人满意的结果,衣服的翘曲会产生可接受的结果。然而,当模特移得更远、变小时,翘曲模块会产生不准确的包裹服装,导致单帧试穿效果不理想。ClothFormer可以处理以下情况:人的比例相对较小,但其生成的结果模糊不清,颜色偏差明显。

图3.与 VVT 数据集上现有替代方案的定性比较。服装和目标人员如(a)所示。(b) FW-GAN、(c) PBAFN、(d) ClothFormer、(e) StableVITON 和 (f) Tunnel Try-on 的结果分别表示。
作者还将一些基于扩散的图像试戴方法(例如,AnyDoor和StableVITON)扩展到按帧生成的视频。并观察到它们可以生成相对准确的单帧结果。然而,由于缺乏对时间连贯性的考虑,连续帧之间存在差异。如图3(e)所示,衣服上的字母在不同的框架中会发生变化。此外,在这些方法中,相邻帧之间有很多抖动,可以在视频中更直观地观察到。
与现有解决方案相比,Tunnel try-on无缝集成了基于扩散的模型和视频生成模型,能够生成具有高帧间一致性的准确单帧试戴视频。如图3(f)所示,当人靠近时,衣服胸前的字母保持一致和正确。
在表 1 中,作者使用基于图像和基于视频的指标进行定量实验。对于基于图像的评估,利用结构相似性(SSIM)和学习感知图像贴片相似性(LPIPS)。这两个指标用于评估配对设置下单图像生成的质量。SSIM越高,LPIPS越低,生成的图像与原始图像之间的相似性越大。
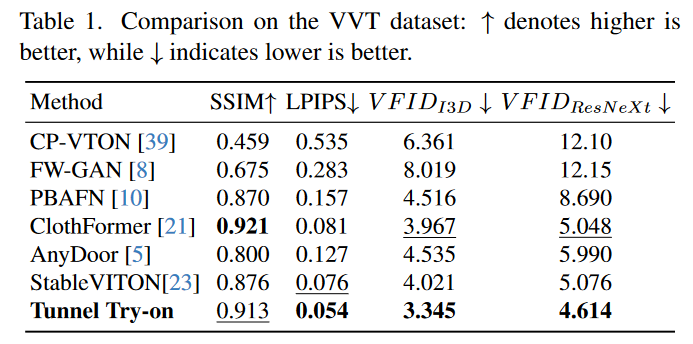
对于基于视频的评估,作者采用视频Frechet初始距离(VFID)来评估视觉质量和时间一致性。FID 测量生成样本的多样性。此外,VFID 采用 3D 卷积来提取时间和空间维度的特征,以便更好地进行测量。采用两种CNN骨干模型,即I3D和3D-ResNeXt101作为VFID的特征提取器。
表 1 表明,在 VVT 数据集上,Tunnel try-on在 SSIM、LPIPS 和 VFID 指标方面优于其他方法,进一步证实了Tunnel try-on在图像视觉质量(相似性和多样性)和时间连续性方面优于其他方法。值得注意的是,与其他方法相比,Tunnel try-on在LPIPS方面具有很大的优势。考虑到与SSIM相比,LPIPS更符合人类的视觉感知,这凸显了Tunnel try-on的卓越视觉质量。
考虑到定量指标不能完全符合人类对生成任务的偏好,作者进行了一项用户研究,以提供更全面的比较。作者组织了一个由 10 名注释者组成的小组,对 VVT 测试集的 130 个样本进行比较。让不同的方法为相同的输入生成视频,并让注释者选择最好的一个。评审标准包括质量、保真度、平滑度三个方面。具体来说,“质量”表示图像质量,包括伪像、噪点水平和失真等方面。“保真度”衡量的是与参考服装图像相比保留细节的能力。“平滑度”评估生成的视频的时间一致性。请注意,ClothFormer 不是开源的,但它提供了 25 代结果。在表 1 的底部对 ClothFormer 和Tunnel try-on之间的 25 个结果进行了单独比较。结果表明,Tunnel try-on明显优于其他方法。
4.定性比较
由于 VVT 数据集中样本的多样性和简单性有限,它无法表示实际视频试戴应用中遇到的场景。因此,在自己的数据集上提供了额外的定性结果,以突出隧道试穿的强大试穿能力和实用性。图 1 说明了 Tunnel Try-on 生成的各种结果,包括由于人与摄像机的距离变化而导致的个体大小变化、相对于摄像机的平行运动以及摄像机角度变化引起的背景和视角变化等场景。通过整合对焦通道策略和对焦通道增强,Tunnel try-on展示了有效适应不同类型的人体运动和相机变化的能力,从而在生成的试穿视频中实现高细节保留和时间一致性。
此外,与之前仅限于试穿紧身上衣的视频试穿方法不同,Tunnel try-on可以根据用户的选择对不同类型的上衣和下装执行试穿任务。图 4 显示了不同类型下装的一些试穿示例。

图4.Tunnel Try-on 在自己的数据集上的定性结果。其中展示了裤子和裙子的试穿结果,以及跨品类的试穿结果。
5.消融实验
本节隧道试穿的消融实验,以探索焦点隧道提取、焦点隧道增强和环境编码的影响。作者对收集的数据集进行定性和定量消融,以评估其性能。
在表3中,提供了与消融实验相关的定量指标。Focus Tunnel 策略显著改善了模型的 SSIM 和 LPIPS 指标,但会导致 VFID 指标出现一定程度的下降。这表明对焦通道可以有效提高帧生成的质量,但可能会引入更多的闪烁,从而降低视频的时间一致性。然而,随着隧道的增强,网络的VFID显示出显着的改善,而SSIM也有所增加。最后,尽管环境编码器对定量指标没有显著影响,但观察到它有助于生成服装周围的背景环境,如图 7 所示。我们在以下段落中对每个组件进行了详细分析。

图7.环境编码器的定消融。全球背景有助于服装地区周围背景的恢复。
如图 5 所示,焦点隧道策略的影响是显而易见的。如果没有对焦通道,徽标的细节就会出现明显的失真。然而,在用衣服的特写镜头放大隧道区域之后。服装的详细信息可以得到更好的保存。

图5.焦点隧道的定性消融。这种放大策略为保留服装的精细细节带来了显着的改进。
在图 6 中,作者研究了隧道增强的有效性。如红色框区域所示,当不使用隧道增强(第一行)时,服装纹理会随着时间的推移而变化和闪烁,从而导致生成的视频的时间一致性降低。

图6.隧道增强的定性消融。它有助于生成更稳定和连续的纹理。
隧道增强的定性消融。它有助于生成更稳定和连续的纹理。图 7 说明了环境编码器对生成结果的影响。由于环境编码器可以在焦点隧道之外提取整体上下文信息,因此可以增强服装周围背景的质量,使其与有关环境的高级语义信息更加一致。如图 7 所示,当添加环境编码器时,会校正人体附近墙壁和斑马线纹理中的生成错误
四、总结
本文中介绍了第一个基于扩散的视频视觉试穿模型,即隧道试穿。它在定性和定量比较中都优于所有现有的替代方案。利用对焦通道、通道增强和环境编码,该模型可以适应视频中不同的摄像机运动和人体运动。在真实数据集上训练后,该模型可以处理具有复杂背景和不同服装类型的视频中的虚拟试穿,从而产生高保真试穿结果。作为时尚行业的实用工具,Tunnel Try-on 为虚拟试穿应用的未来研究提供了新的见解。