
一、介绍
大规模扩散模型在文本到图像合成方面取得了巨大的突破。因此一些工作(如VDM,Make-a-video)试图在视频任务上复制这一成功。即试图对高维复杂视频分布进行建模。然而,训练这样的文本到视频模型需要大量的高质量视频和计算资源,这限制了相关社区的进一步研究和应用,基本只有大公司才玩得起。
为了减少过多的训练要求,本文试图研究了一种新的有效形式:使用文本到图像模型的可控文本到视频生成。该任务旨在制作一个以文本描述和运动序列(例如深度或边缘图为条件的视频)。如图1所示,它可以利用预训练的文本到图像生成模型和运动序列的粗略时间一致性来生成生动的视频,而不是从头开始学习视频分布。

图1:免训练、可控的文本到视频生成。左图:ControlVideo 通过沿时间轴扩展使ControlNet 适应视频数据,旨在直接继承其高质量和一致的生成,而不需任何微调。右图:ControlVideo 可以合成以各种运动序列为条件的逼真视频,这些视频在结构和外观上都是时间一致的。在500%变焦下效果最佳。
最近的研究(Tune-a-video,Text2Video-Zero)探索了利用ControlNet或DDIM 的结构进行可控性视频生成。其中Tune-a-video,Text2Video-Zero这些工作不是独立地合成所有帧,而是通过用稀疏的跨帧注意力代替原始的注意力来增强外观的连贯性。但在生成视频的质量仍然落后于现实世界具有真实感的视频,具体表现为这几个方面:1️⃣某些帧之间的外观不一致(图4a),2️⃣大型运动视频中的可见伪像(图4b),3️⃣帧间过度期间的结构闪烁(图4b)。对于1️⃣和2️⃣,它们更稀疏的跨帧机制增加了自注意力模块中query 和 key之间的差异,从而阻碍了从预训练的文本到图像模型中继承高质量和一致的生成。对于3️⃣,输入运动序列仅提供视频的粗级结构,无法在连续帧之间平滑过渡。

图4:以深度图和边缘为条件的定性比较。ControlNet合成的视频比其他方法生成的视频具有更好的外观一致(a)和视频质量(b)。相比之下Tune-A-video无法继承源视频的结构,而Text2Video-Zero则在大型动态视频中带来了可见的伪影。在500%变焦下效果最佳。
在这项工作中,作者提出了一种无需训练的 ControlVideo,用于高质量和一致的可控文本到视频生成。它由完全跨帧交互、交错帧平滑器和分层采样器组成。其中交错帧平滑器以增强结构平滑度,即减少整个视频中的结构闪烁(flickers)。ControlVideo 直接继承了 ControlNet 的架构和权重,同时通过完全跨帧交互扩展自我注意力来使其适应视频数据。与之前的工作不同,完全跨帧交互将所有帧连接成一个“更大的图像”,从而直接继承了ControlNet的高质量和一致的生成。交错帧平滑器通过选定的对整个视频进行去闪烁(deflickers)。如图 3 所示,每个时间步的操作通过插值中间帧来平滑交错的三帧剪辑,并且两个连续时间步的组合使整个视频平滑。由于平滑操作仅在几个时间步长下执行,因此通过以下去噪步骤可以很好地保留插值帧的质量和个性。

图3:交错帧平滑器的图示。在时间步长 \(\textcolor{blue}{t}\) 处,预测的 RGB 帧 \(\textcolor{blue}{x_{t→0}}\) 通过中间帧插值平滑为\(\textcolor{blue}{\tilde{x}_{t→0}}\)。两个连续时间步长的组合减少了整个视频的结构闪烁。
为了实现高效的长视频合成,进一步引入了分层采样器,以生成具有长期连贯性的分离短片。具体来说,一个长视频首先被分割成多个具有所选关键帧的短视频剪辑。然后,以完全跨帧注意力预先生成关键帧,以实现远程连贯性。以成对的关键帧为条件,依次合成它们对应的中间短视频片段,并具有全局一致性。
二、ControlVideo
可控文本到视频生成旨在生成长度为N的视频,条件是运动序列\(\textcolor{blue}{c = \{c^i\}^{N-1}_{i=0}}\)以及文本提示\(\textcolor{blue}{τ}\)。如图 2 所示,作者提出了一个称为 ControlVideo 的无训练框架,以实现一致和高效的视频生成。

图2:ControlVideo框架图。为了在外观上保持一致,ControlVideo 通过在自注意力模块中添加完全跨帧交互来使 ControlNet 适应视频目标。考虑到结构上的闪烁,集成了交错帧平滑器,通过交错插值平滑所有帧间过渡(详见图3)。
首先ControlVideo由ControlNet改编而来,采用完全跨帧交互,确保了外观的一致性,减少了质量下降。其次,交错帧平滑器通过以连续的时间步长插值交替帧来对整个视频进行去闪烁。最后,分层采样器单独生成具有整体连贯性的短片,以实现长视频合成。
👩🏻🏭完全跨帧交互(Fully cross-frame interaction):使文本到图像模型适应视频目标的主要挑战是确保时间一致性。利用ControlNet的可控性,运动序列可以在结构上提供粗略的一致性。尽管如此,即使使用相同的初始噪声,使用 ControlNet 单独生成所有帧也会导致外观严重不一致(参见图 6 中的第 2 行)。为了保持视频外观的连贯性,将所有视频帧连接起来,形成一个“大图像”,以便它们的内容可以通过帧间交互共享。考虑到SD中的自我注意力是由外观相似性驱动的,可通过增加基于注意力的完全跨框架交互来增强整体连贯性。
具体来说,ControlVideo沿时间轴从SD中扩散主UNet,同时使辅助UNet远离ControlNet(作者为了区分,把SD当中的UNet命名为 主 UNet,而ControlNet当中的为辅助 UNet)。它通过将3x3的内核替换为1x3x3的内核,直接将2D卷积层替换为3D卷积层。在图 2(右)中,它通过在所有帧中添加交互来扩展自我注意力:
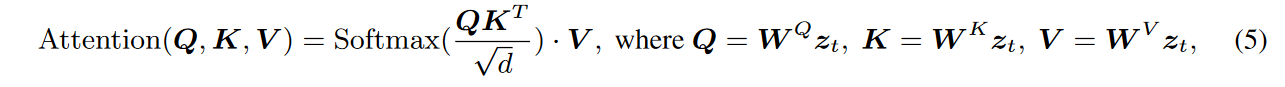
其中 \(\textcolor{blue}{z_t = \{z^i_t\}^{N-1}_{i=0}}\)表示时间步长 t 处的所有潜在帧,而 \(\textcolor{blue}{W^Q}\)、\(\textcolor{blue}{W^K}\) 和 \(\textcolor{blue}{W^V}\) 分别将 \(\textcolor{blue}{z_t}\) 投影到query,key和value中。
以前的工作(Tune-A-video,Text2Video-Zero)通常用更稀疏的跨帧机制代替自我关注,例如,所有帧都只关注第一帧。然而,这些机制会增加自注意力模块中query和key之间的差异,导致视频质量和一致性下降。相比之下,全跨帧机制(fully cross-frame mechanism)将所有帧组合成一个“大图像”,并且与文本到图像模型的代沟较小(参见图 6 中的比较)。此外,通过高效实现,在短视频生成(< 16 帧)中,完全跨帧注意力只会带来很少的内存和可接受的计算负担。
🦑交错帧平滑器:尽管完全跨帧交互产生的视频在外观上非常一致,但它们在结构上仍然明显闪烁。输入运动序列只能确保合成视频具有粗略的结构一致性,但不足以保持连续帧之间的平滑过渡。因此,作者进一步提出了一种交错帧平滑器来减轻结构中的闪烁效应。如图 3 所示,其关键思想是通过插值中间帧来平滑每个三帧剪辑,然后以交错方式重复它以平滑整个视频。
具体来说,交错帧平滑器是在连续时间步长的预测RGB帧上执行的。每个时间步的操作都会插值偶数或奇数帧,以平滑其相应的三帧剪辑。通过这种方式,来自两个连续时间步长的平滑三帧剪辑重叠在一起,以消除整个视频的闪烁。在时间步长\(\textcolor{blue}{t}\) 处应用交错帧平滑器之前,首先根据\(\textcolor{blue}{z_t}\)预测干净的视频潜在向量\(\textcolor{blue}{z_{t \rightarrow 0}}\):
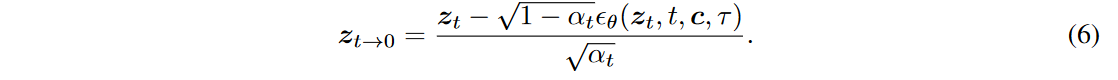
将\(\textcolor{blue}{z_{t \rightarrow 0}}\)投影到RGB视频\(\textcolor{blue}{x_{t \rightarrow 0} = \mathcal{D}(z_{t \rightarrow 0})}\)后,使用交错帧平滑器将器转换为平滑的视频\(\textcolor{blue}{\tilde{x}_{t \rightarrow 0}}\)。基于平滑视频潜在\(\textcolor{blue}{\tilde{z}_{t \rightarrow 0} = \mathcal{E}(\tilde{x}_{t \rightarrow 0})}\),之后再计算去噪后的在\(\textcolor{blue}{t-1}\)时刻的噪声潜在\(\textcolor{blue}{z_{t-1}}\):

值得注意的是,上述过程仅在选定的中间时间步长执行,这有两个优点:(i)新的计算负担可以忽略不计,(ii)插值帧的个性和质量通过以下去噪步骤得到很好的保留。
👾分层采样器由于视频扩散模型需要保持帧间交互的时间一致性,因此它们通常需要大量的 GPU 内存和计算资源,尤其是在制作更长的视频时。为了促进高效和一致的长视频合成,作者引入了一个分层采样器,以逐个剪辑的方式生成长视频。在每个时间步长,一个长视频\(\textcolor{blue}{z_{t}=\{z^i_t\}^{N-1}_{i=0}}\)被分成多个短视频剪辑,所选关键帧\(\textcolor{blue}{z_{t}^{key}=\{z^{kN_c}_t\}^{\frac{N}{N_c}}_{k=0}}\),其中每个剪辑的长度为\(\textcolor{blue}{N_c - 1}\)。第k个剪辑表示为\(\textcolor{blue}{\widehat{z}_t^k=\{z^j_t\}^{(k+1)N_c -1}_{j=kN_c + 1}}\)。然后,预先生成具有完全跨帧注意力的关键帧以实现远程一致性,其query、key和value计算如下:

根据每对关键帧,依次合成它们相应的剪辑,以保持整体一致性:
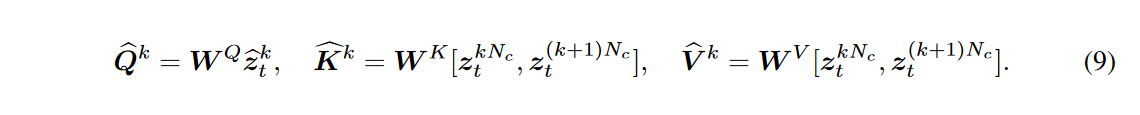
三、实验
1.实验设置
实验细节:ControlVideo 改编自 ControlNet,交错帧平滑器采用轻量级 RIFE 来插值每个三帧剪辑的中间帧。合成的短视频长度为 15 帧,而长视频通常包含大约 100 帧。除非另有说明,否则它们的分辨率均为 512 × 512。在采样过程中,采用具有 50 个时间步长的 DDIM 采样,默认情况下,在时间步长 {30, 31} 处对预测的 RGB 帧执行交错帧平滑器。通过高效实施 xFormers, ControVideo 可以分别在大约 2 分钟和 10 分钟内使用一台 NVIDIA RTX 2080Ti 制作短视频和长视频
数据:为了评估ControlVideo,从DAVIS数据集中收集了25个以对象为中心的视频,并手动注释了它们的源描述。然后,对于每个源描述,利用 ChatGPT 自动生成 5 个编辑提示,总共产生 125 个视频提示对。最后,我们采用Canny和MiDaS DPT-Hybrid模型来估计源视频的边缘和深度图,并形成125个运动提示对作为评估数据集。
Metrics:作者采用CLIP从两个角度评估视频质量。1️⃣帧一致性:所有连续帧对之间的平均余弦相似度,以及2️⃣提示一致性:输入提示和所有视频帧之间的平均余弦相似度。
baseline:ControlVideo与三种公开可用的方法进行了比较:1️⃣Tune-A-Video:通过对源视频进行微调,将Stable Diffusion扩展到视频对应物。在推理过程中,它使用源视频的DDIM反转代码来提供结构指导。2️⃣Text2Video-Zero: 基于 ControlNet,在 Stable Diffusion 上采用了第一个唯一的跨帧注意力,无需微调。3️⃣Follow-Your-Pose: 使用 Stable Diffusion 初始化,并在 LAION-Pose 上进行微调以支持人体姿势条件。之后,它对数百万个视频进行训练,以实现时间一致的视频生成。
2.实验设置
定性结果:图 4 首先说明了以 (a) 深度图和 (b) 精细边缘为条件的合成视频的视觉比较。如图 4 (a) 所示,ControlVideo 在外观和结构上都比其他竞争对手具有更好的一致性。Tune-A-Video 无法保持外观和细粒度结构的时间一致性,例如外套的颜色和道路的结构。利用来自深度图的运动信息,Text2Video-Zero在结构上实现了有希望的一致性,但仍然在视频中遇到不连贯的外观,例如外套的颜色。此外,ControlVideo在处理大型运动输入时也表现得更加稳健。如图 4 (b) 所示,Tune-A-Video 忽略了源视频中的结构信息。Text2Video-Zero 采用第一个唯一的跨帧机制来权衡帧质量和外观一致性,并生成具有可见伪影的后续帧。相比之下,通过建议的全跨帧机制和交错帧平滑器,ControlVideo 可以处理大运动以生成高质量和一致的视频。
图5进一步显示了以人体姿势为条件的比较。从图5中可以看出,Tune-A-Video仅保持源视频的粗略结构,即人体位置。Text2Video-Zero 和 Follow-Your-Pose 生成外观不一致的视频帧,例如,改变钢铁侠的面孔(第 4 行)或背景中消失的物体(第 5 行)。相比之下,ControlVideo 执行更一致的视频生成,展示了其优越性。

图5:姿势的定性比较。Tune-A-Video 只保留了原始的人体姿势,而 Text2Video-Zero 和 Follow-Your-Pose 生成了外观不连贯的帧,例如,改变钢铁侠的面孔。ControlVideo 在结构和外观上都实现了更好的一致性。
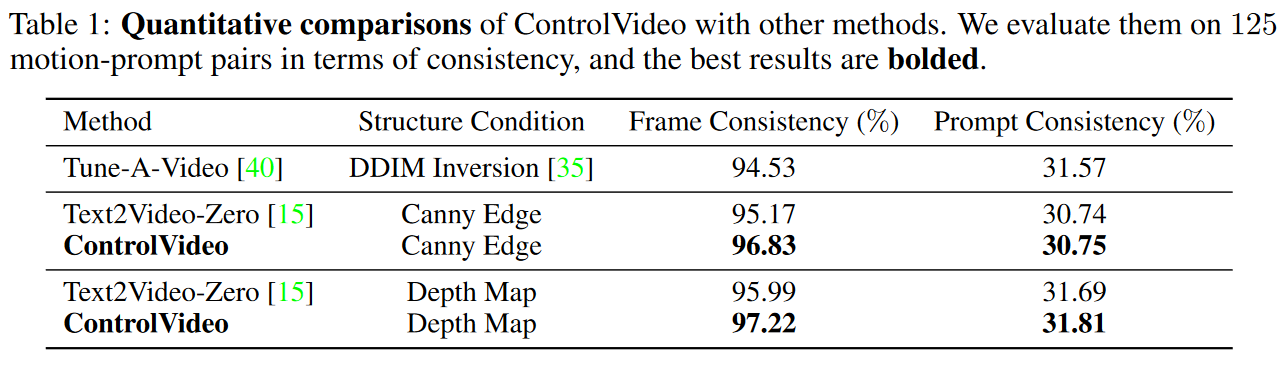
定量结果:作者在 125 个视频提示对上将 ControlVideo 与现有方法进行了定量比较。从表1中可以看出,以深度为条件的ControlVideo在帧一致性(Frame Consistency)和提示一致性(Prompt Consistency)方面优于最先进的方法,这与定性结果一致。相比之下,尽管对源视频进行了微调,但 Tune-A-Video 仍然难以制作出时间连贯的视频。尽管以相同的结构信息为条件,但 Text2Video-Zero 获得的帧一致性比我们的 ControlVideo 更差。对于每种方法,深度条件模型生成的视频都比 canny-condition 对应模型具有更高的时间一致性和文本保真度,因为深度图提供了更平滑的运动信息。
3.用户研究
然后,作者进行用户研究,将基于深度图的 ControlVideo 与其他竞争方法进行比较。具体来说,为每个评分者提供结构序列、文本提示和来自两种不同方法的合成视频(按随机顺序)。然后,要求他们为以下三个测量中的每个测量选择更好的合成视频:1️⃣视频质量,2️⃣所有帧的时间一致性,以及3️⃣提示和合成视频之间的文本对齐。评估集由 125 个具有代表性的结构提示对组成。每对由 5 名评分者进行评估,对最终结果进行多数投票。从表2中可以看出,评分者从这三个角度来看都非常支持ControlVideo合成视频,尤其是在时间一致性方面。另一方面,Tune-A-Video 无法生成一致且高质量的视频,仅通过 DDIM 反转进行结构指导,而 Text2Video-Zero 也生成质量和连贯性较低的视频。

4.消融研究
完全跨帧交互的效果:为了证明完全跨帧交互的有效性,作者与以下变体进行了比较:1️⃣个体(Individual):所有帧之间没有交互,2️⃣第一帧(First-only):所有帧都关注第一个帧,3️⃣稀疏因果关系(Sparse-causal):每个帧都关注第一帧和前一帧,4️⃣完全跨帧交互(Fully cross-frame):。上述所有模型都是从 ControlNet 扩展而来的,无需任何微调。定性和定量结果分别如图6和表3所示。
从图6中可以看出,1️⃣单个交叉帧机制存在严重的时间不一致,例如彩色帧和黑白帧。2️⃣第一仅因果机制和3️⃣稀疏因果机制通过添加跨帧交互来减少一些外观不一致。然而,他们仍然制作出结构不一致和可见伪影的视频,例如大象的方向和重复的鼻子(图 6 中的第 3 行)。相比之下,由于与 ControlNet 的代沟较小,完全跨帧交互具有更好的外观连贯性和视频质量。尽管引入的交互带来了额外的 1 ∼ 2× 时间成本,但对于高质量的视频生成来说是可以接受的。
交错帧的效果更平滑:进一步分析了所提出的交错帧平滑器的效果。从图 6 和表 3 可以看出,我们的交错帧平滑器大大减少了结构闪烁,提高了视频的平滑度。

图 6:关于跨帧机制和交错帧平滑器的定性消融研究。鉴于第一行的边缘很巧妙,完全跨帧交互产生的视频帧比其他机制具有更高的质量和一致性,并且添加平滑器可以进一步增强视频的流畅度。
5.扩展为长视频生成
制作长视频通常需要具有高内存的高级 GPU。通过建议的分层采样器,ControlVideo 以节省内存的方式实现了长视频生成(超过 100 帧)。如图 7 所示,ControlVideo 可以生成始终如一的高质量长视频。它只需大约 10 分钟即可在一台 NVIDIA RTX 2080Ti 中生成分辨率为 512 × 512 的 100 帧。

图 7:使用我们的分层采样制作的长视频。运动序列显示在左上角。使用高效的采样器,我们的 ControlVideo 可生成具有整体一致性的高质量长视频。在500%变焦下效果最佳。
四、总结
在本文中,我们提出了一个无需训练的框架,即ControlVideo,以实现一致且高效的可控文本到视频生成。特别是,ControlVideo 通过添加完全跨帧交互来从 ControlNet 中膨胀,以确保在不牺牲视频质量的情况下保持外观连贯性。此外,交错帧平滑器以顺序时间步长插值交替帧,以有效减少结构闪烁。通过进一步引入的分层采样器和内存效率高的设计,我们的 ControlVideo 可以使用商用 GPU 在几分钟内生成短视频和长视频。对大量运动提示对的定量和定性实验表明,ControlVideo 在视频质量和时间一致性方面比以前最先进的技术表现更好。