
一、介绍
扩散模型在时间序列方向上的应用,主要包含时间序列预测、时间序列插补、时间序列生成。
1️⃣时间序列预测:给定观察到的历史时间序列,去预测未来的时间序列。
2️⃣时间序列插补:由于数据收集失败和人为错误等原因,观测到的时间序列有时不完整,因此采用时间序列插补来填补缺失值。
3️⃣时间序列生成:生成更多与观测周期具有相似特征的时间序列样本。
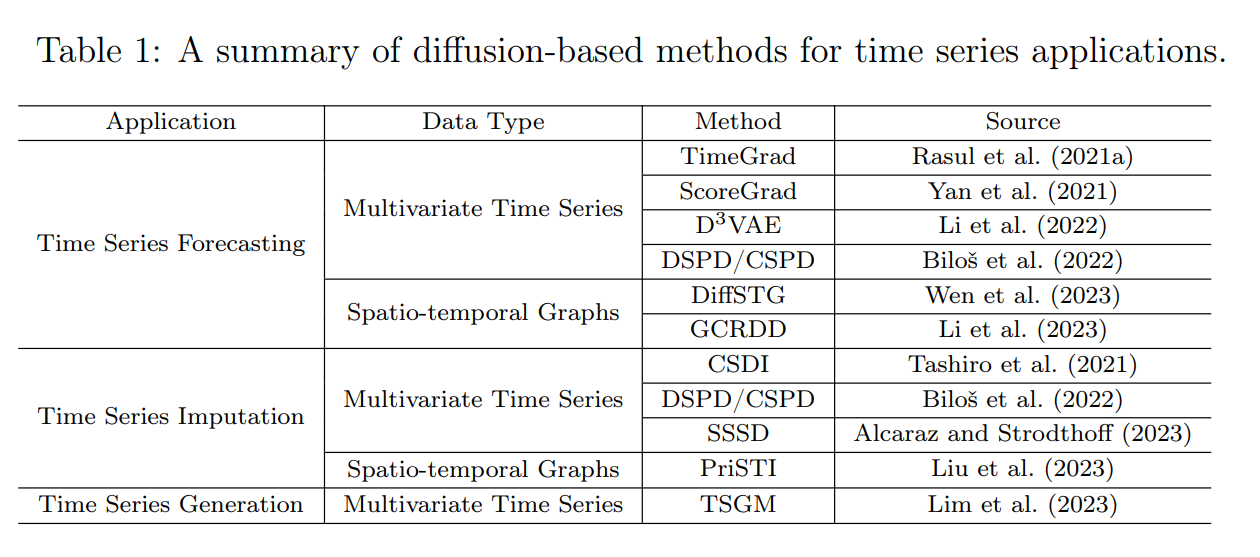
针对这三个方面,本文总结了目前几乎所有的基于扩散的时间序列应用模型,如下表所示:
基本上,用于时间序列应用的基于扩散的方法是从三个基本公式发展而来的,包括去噪扩散概率模型(DDPM)、基于分数的生成模型(SGM)和随机微分方程(SDE)。
1.DDPM
DDPM 通过两个马尔可夫链实现前向和后向过程。令原始观测数据为 \(\textcolor{DodgerBlue}{x^0}\),其中0表示数据未受到扩散过程中注入的噪声的影响。
前向马尔可夫链使用扩散转移核将 \(\textcolor{DodgerBlue}{x^0}\) 变换为扰动数据序列 \(\textcolor{DodgerBlue}{x^1, x^2, ..., x^K}\),扩散转移核为:

其中 \(\textcolor{DodgerBlue}{α_k ∈ (0, 1)}\) 是超参数,表示每一步噪声水平变化的方差,\(\textcolor{DodgerBlue}{\mathcal{N} (x; μ, Σ)}\) 是表示 \(\textcolor{DodgerBlue}{x}\) 的高斯分布,其分别具有平均值 \(\textcolor{DodgerBlue}{μ}\) 和协方差 \(\textcolor{DodgerBlue}{Σ}\)。之后,可以通过以下方式直接从 \(\textcolor{DodgerBlue}{x^0}\) 获得 \(\textcolor{DodgerBlue}{x^k}\):
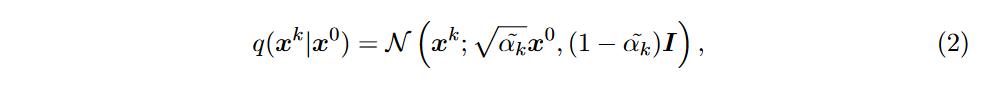
其中\(\textcolor{DodgerBlue}{\tilde{\alpha}_k := ∏^k_{i=1} α_i}\)。因此,\(\textcolor{DodgerBlue}{x^k =\sqrt{\tilde{\alpha}_k} x^0 + \sqrt{1-\tilde{\alpha}_k}\epsilon}\)且\(\textcolor{DodgerBlue}{\epsilon ∼ N (0, I)}\)。通常,我们设计\(\textcolor{DodgerBlue}{\tilde{\alpha}_K ≈ 0}\) 使得\(\textcolor{DodgerBlue}{q(x^K) := ∫ q(x^K|x^0)q(x^0)dx^0 ≈ N (x^K;0,I)}\),这意味着后向过程的起点可以是任意标准高斯噪声。
后向转移核由参数化神经网络建模:
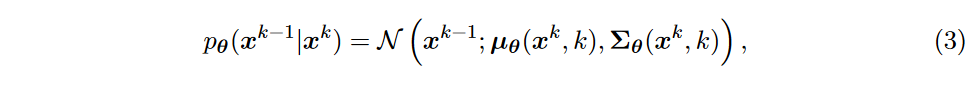
其中 \(\textcolor{DodgerBlue}{\theta}\) 表示可学习参数。现在,剩下的问题是如何估计\(\textcolor{DodgerBlue}{\theta}\)。基本上,目标是最大化似然目标函数,以便观察到由 \(\textcolor{DodgerBlue}{p_\theta(x^0)}\) 估计的训练样本 \(\textcolor{DodgerBlue}{x^0}\) 的概率最大化。此任务是通过最小化估计的负对数似然 \(\textcolor{DodgerBlue}{E[− \log p_θ(x^0)]}\) ,即

其中\(\textcolor{DodgerBlue}{x^{0:K}}\)表示序列 \(\textcolor{DodgerBlue}{x^0,...,x^K}\)。
在DDPM当中提出,可以将方程(3)中的协方差矩阵 \(\textcolor{DodgerBlue}{Σ_θ(x^k, k)}\) 简化为常数相关矩阵\(\textcolor{DodgerBlue}{σ^2_kI}\),其中\(\textcolor{DodgerBlue}{σ^2_ k}\) 控制噪声水平,并且可能在不同的扩散步骤中变化。此外,他们将均值重写为可学习噪声项的函数:
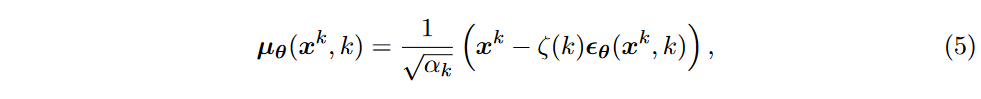
其中 \(\textcolor{DodgerBlue}{ζ(k) =\frac{1−α_k}{\sqrt{1-\tilde{\alpha}_k}}}\) ,\(\textcolor{DodgerBlue}{\theta}\)是一个噪声匹配网络,用于预测对应于输入 \(\textcolor{DodgerBlue}{x^k}\) 和 \(\textcolor{DodgerBlue}{k}\) 的数据。凭借方程(2)中的属性, 进一步简化目标函数为

其中 \(\textcolor{DodgerBlue}{δ(k) = \frac{(1−α_k)^2}{2σ^2_kα_k(1-\tilde{\alpha}_k)}}\) 是一个正值权重,可以将其丢弃以在实践中产生更好的性能。
最终,通过消除 \(\textcolor{DodgerBlue}{x^K∼N(x^K;0,I)}\) 中的噪声来生成样本。更具体地说,对于 \(\textcolor{DodgerBlue}{k=K−1,K−2,...,0,}\)
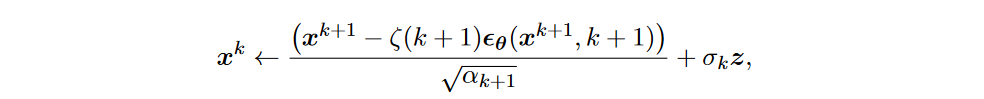
其中 \(\textcolor{DodgerBlue}{z∼N (0,I)}\)(对于 \(\textcolor{DodgerBlue}{k=K−1,...,1}\)),并且\(\textcolor{DodgerBlue}{z=0}\) (对于\(\textcolor{DodgerBlue}{k=0}\))。
二、时间序列预测
1.问题表述
考虑多元时间序列\(\textcolor{DodgerBlue}{X^0=\{x_1^0,x_2^0,...,x_T^0|x_i^0 \in R^D\}}\),其中0表示数据在扩散过程中不受扰动。预测任务是给定历史信息 \(\textcolor{DodgerBlue}{X_c^0=\{x_1^0,x_2^0,...,x^0_{t_0-1}\}}\) 的情况下去预测 \(\textcolor{DodgerBlue}{X_p^0=\{x^0_{t_0},x^0_{t_0+1},...,x^0_T\}}\)。因此 \(\textcolor{DodgerBlue}{X_c^0}\) 称为上下文窗口,而 \(\textcolor{DodgerBlue}{X_p^0}\) 称为预测区间。而在基于扩散模型中,问题被表述为学习预测区间内数据的联合概率分布:

一些文献还考虑了协变量在预测中的作用。协变量是可能随时间影响变量行为的附加信息,例如季节性波动和天气变化。在预测中纳入协变量通常有助于加强对驱动数据时间趋势和模式的因素的识别。协变量的预测问题表述为
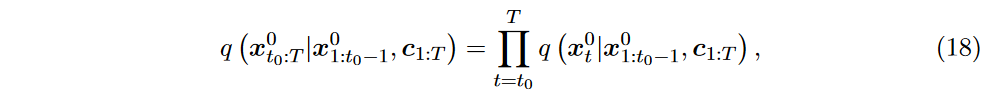
其中 \(\textcolor{DodgerBlue}{c_{1:T}}\) 表示所有时间点的协变量,并假设整个时期已知。
为了满足训练的目的,可以从完整的训练数据中随机采样上下文窗口,然后是预测窗口。这个过程可以看作是在整个时间线上应用一个大小为 \(\textcolor{DodgerBlue}{T}\) 的移动窗口。然后,可以利用样本进行目标函数的优化。预测未来时间序列通常是通过扩散模型对应的生成过程来实现的。
2.TimeGrad
基于扩散的预测第一个值得注意的工作是 Rasul 等人提出的 TimeGrad。 TimeGrad 由 DDPM 模型发展而来,首先在每个预测时间点向数据注入噪声,然后通过以历史时间序列为条件的后向转移核(类似式3)逐渐去噪。为了对历史信息进行编码,TimeGrad 近似式 (18) 中的条件分布:
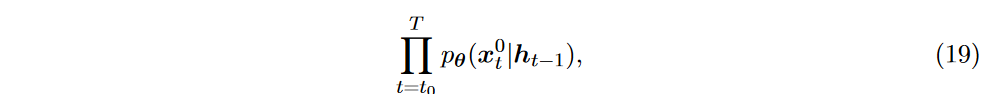
其中
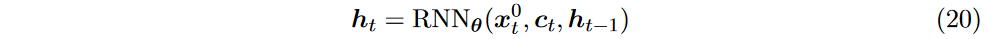
是使用可以保留历史时间信息的 LSTM(或 GRU等 RNN 模块计算的隐藏状态,\(\textcolor{DodgerBlue}{\theta}\) 包含整体条件分布及其 RNN 组件的可学习参数。
TimeGrad 的目标函数采用负对数似然的形式,如下所示
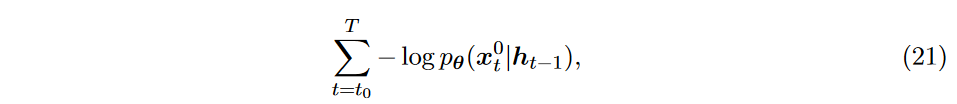
其中对于每个 \(\textcolor{DodgerBlue}{t \in [t_0,T], -\log p_\theta(x_t^0|h_{t-1})}\) 的目标函数为
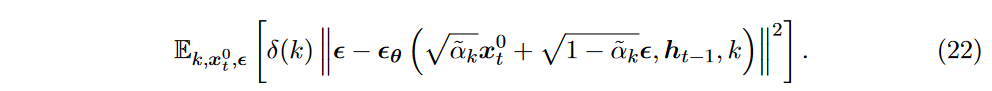
上下文窗口用于生成隐藏状态\(\textcolor{DodgerBlue}{h_{t_0−1}}\) 作为训练过程的起点。
在训练过程中,通过随机采样最小化负对数似然目标函数来估计参数\(\textcolor{DodgerBlue}{\theta}\)。然后,逐步生成未来的时间序列。假设完整时间序列的最后一个时间点是\(\textcolor{DodgerBlue}{\tilde{T}}\)。第一步是根据最后一个可用的上下文窗口导出隐藏状态\(\textcolor{DodgerBlue}{h_{\tilde{T}}}\) 。接下来,以与 DDPM 类似的方式预测下一个时间点\(\textcolor{DodgerBlue}{\tilde{T}+1}\) 的观测值:
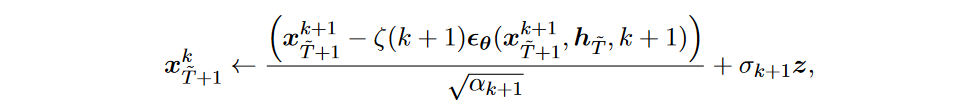
预测的 \(\textcolor{DodgerBlue}{x^k_{\tilde{T}+1}}\) 应反馈给 RNN 模块以获得 \(\textcolor{DodgerBlue}{h_{\tilde{T}+1}}\) ,然后再预测下一个时间点。将重复采样过程,直到达到未来时间序列的所需长度。
三、时间序列插补
在现实世界的问题设置中,通常会遇到缺失值的挑战。在采集时间序列数据时,采集条件可能会随着时间的推移而发生变化,这使得很难保证观测的完整性。此外,传感器故障、人为失误等事故也可能导致历史记录丢失。时间序列数据中的缺失值通常会对分析和预测的准确性产生负面影响,因为缺乏部分观察使得推论和结论在未来的概括中很脆弱。时间序列插补旨在填补不完整时间序列数据中的缺失值。
1.问题表述
给定多元时间序列\(\textcolor{DodgerBlue}{X^0=\{x_1^0,x_2^0,...,x_T^0|x_i^0 \in R^D\}}\),其中\(\textcolor{DodgerBlue}{X^0 \in R^{D \times T}}\),\(\textcolor{DodgerBlue}{D}\)是特征的数量,\(\textcolor{DodgerBlue}{T}\)是\(\textcolor{DodgerBlue}{[1,T]}\)期间的时间点的数量。在这里假设存在一个不完整的观测矩阵,需要通过探索一些观察数据中的信息来预测缺失数据的值。将观测的数据表示表示为\(\textcolor{DodgerBlue}{X^0_{ob}}\),将缺失数据表示为\(\textcolor{DodgerBlue}{X^0_{ms}}\)。然后,插补任务是找到条件概率分布\(\textcolor{DodgerBlue}{q(X^0_{ms}|X^0_{ob})}\)。
出于实际目的,对不完整矩阵 \(\textcolor{DodgerBlue}{X^0}\) 进行零填充,使得所有缺失项都被分配为 0。此外,构造一个零一矩阵\(\textcolor{DodgerBlue}{M \in R^{D \times T}}\) 作为掩码来表示缺失值的位置。更具体地,当\(\textcolor{DodgerBlue}{X^0}\)中的相应值缺失时,\(\textcolor{DodgerBlue}{M}\)中的元素为0,否则为1。
\(\textcolor{DodgerBlue}{X^0_{ob}}\) 和 \(\textcolor{DodgerBlue}{X^0_{ms}}\) 与 \(\textcolor{DodgerBlue}{X^0}\) 具有相同的尺寸。在训练过程中,随机选择 \(\textcolor{DodgerBlue}{X^0}\) 中实际观测数据的一小部分作为缺失数据的真实值,其余观测数据作为预测的条件。引入训练掩码\(\textcolor{DodgerBlue}{M^\prime \in R^{D \times T}}\) 以获得 \(\textcolor{DodgerBlue}{X^0_{ob}}\) 和 \(\textcolor{DodgerBlue}{X^0_{ms}}\)。它是通过将 1 分配给与 \(\textcolor{DodgerBlue}{X^0}\) 中剩余观察数据相对应的条目来构造的。然后,\(\textcolor{DodgerBlue}{X^0_{ob}}\)计算为 \(\textcolor{DodgerBlue}{X^0_{ob} = M^{\prime} \bigodot X_0}\),\(\textcolor{DodgerBlue}{X^0_{ms}}\) 计算为\(\textcolor{DodgerBlue}{X^0_{ms}=(M-M^\prime) \bigodot X_0}\),其中表示逐元素矩阵乘法。另一方面,在预测过程中,所有实际观测到的数据都被用作条件,即\(\textcolor{DodgerBlue}{X^0_{ob} = M \bigodot X_0}\)。
2.CSDI
基于条件分数的扩散模型插补(CSDI)是基于扩散的时间序列插补的开创性工作。
CSDI采用自监督的训练方式,手动mask掉一部分观测值然后补全这部分。如图所示:

在左边的绿白色矩形中,绿色为观测值,白色为缺失值。如果直接用绿色和白色来建模条件概率,显然是没法训练的,因为不知道白色部分的 Ground Truth。作者将观测值再mask掉一部分,如左下角蓝白红矩形所示。其中,红白条纹为mask的缺失值,蓝色为剩余的观测值,之后将缺失值进行加噪后送入到网络当中,再将观测值作为条件和时间步长一起送入。
CSDI将扩散和逆过程应用于缺失数据矩阵\(\textcolor{DodgerBlue}{X^0_{ms}}\),相应地,后向转移核被细化为以\(\textcolor{DodgerBlue}{X^0_{ob}}\)为条件的概率分布:

其中,

其中 \(\textcolor{DodgerBlue}{X^k_{ms} = \sqrt{\tilde{\alpha}_k}X^0_{ms}+ \sqrt{1-\tilde{\alpha}_k}}\) 。这里的方差项与 DDPM 中的版本不同。以前,方差项是用一些预先指定的常数 \(\textcolor{DodgerBlue}{σ_k}\) 定义的,其中 \(\textcolor{DodgerBlue}{k = 1, 2, ..., K}\),这意味着方差被视为超参数。然而,CSDI 定义了一个带有参数 \(\textcolor{DodgerBlue}{θ}\) 的可学习版本 \(\textcolor{DodgerBlue}{σ_θ}\)。CSDI 的目标函数由下式给出:
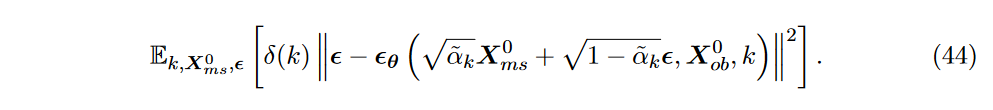
噪声匹配网络 \(\textcolor{DodgerBlue}{θ}\) 默认采用 DiffWave 架构。但把里面的卷积结构给替换成了捕获时空特征的Transformer结构(由多头注意力层、全连接层和层归一化组成)。如下图所示,其中包含Temporal Transformer Layer 和 Feature Transformer Layer 分别提取时空特征。
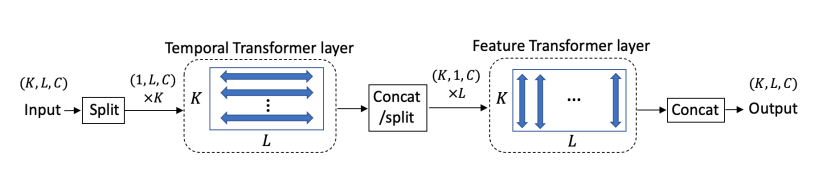

训练后,通过与 DDPM 相同的方式生成缺失值的目标矩阵来完成插补。采样过程中的\(\textcolor{DodgerBlue}{X^0_{ob}}\) 与原始时间序列矩阵 \(\textcolor{DodgerBlue}{X^0}\) 的零填充版本相同,其中所有缺失值都被分配为 0。采样过程的起点是随机高斯插补目标\(\textcolor{DodgerBlue}{X^K_{ms} ∼ N (0,I)}\)。然后,对于 \(\textcolor{DodgerBlue}{k = K − 1, ..., 1}\),算法计算:

其中 \(\textcolor{DodgerBlue}{Z ∼ N (0, I),k = K − 1, ..., 1}\),且 \(\textcolor{DodgerBlue}{Z = 0,k = 0}\)。
3.SSSD
结构化状态空间扩散(SSSD)结合条件扩散模型和状态空间模型,用于解决缺失值插补和长程依赖问题。
SSSD论文当中把插补场景按照随机缺失(RM)、随机块缺失(RMB)和完全随机缺失。随机缺失可能取决于观测到的特征,而随机块缺失还取决于要估算的特征的真实值。在完全随机缺失的情况下就不需要依赖特征值。
1️⃣RM:在整个输入样本的所有通道中,按照均匀分布随机采样作为输入掩码的零项。RM考虑的是单个时间步长而不是连续时间步长块。
2️⃣RMB:根据缺失比例将序列划分为连续时间步长的片段。之后在每个通道随机采样一个片段作为插补目标。
3️⃣BM:一大段连续的缺失。在所有通道上选取一个共同的片段作为插补目标;
4️⃣TF:可以视为BM的特殊情况,其中插补区域跨越\(\textcolor{DodgerBlue}{t}\)个时间步长的连续区域,其中\(\textcolor{DodgerBlue}{t}\)表示位于序列最末端的所有通道的预测范围。

🔵代表实际序列;⚪代表作为真实的条件;🔘代表特定通道当中需要插补的时间步长;🟢浅绿色和深绿色分别表示不同分位下的两种预测带。🟠预测带中随机采样的一个样本
SSSD的生成目标是整个时间序列矩阵\(\textcolor{DodgerBlue}{X^0 \in R^{D \times T}}\),而不是专门代表缺失值的矩阵。其中\(\textcolor{DodgerBlue}{D}\)表示特征或通道数,\(\textcolor{DodgerBlue}{T}\)表示时间步数。为了满足训练目的,\(\textcolor{DodgerBlue}{X^0}\)也进行了补零处理。在这种情况下,条件信息来自级联矩阵\(\textcolor{DodgerBlue}{X^0_c = Concat(X^0 \bigodot M_c,M_c)}\),其中\(\textcolor{DodgerBlue}{M_c \in \{0,1\}^{D \times T}}\)是指示作为条件的观测值的位置的零一矩阵。只有当\(\textcolor{DodgerBlue}{X^0}\)中对应的值已知时,\(\textcolor{DodgerBlue}{M_c}\)中的元素才能为1代表作为条件化的值,而0则是代表要估算的值。
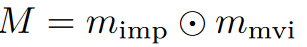
结构化状态空间模型(s4):
它可有效地捕获时间序列数据中的长期依赖性。从本质上讲,该形式利用了线性状态空间转移方程,通过 \(\textcolor{Crimson}{N}\) 维隐藏状态 \(\textcolor{Crimson}{x(t)}\) 将一维输入序列 \(\textcolor{Crimson}{u(t)}\)连接到一维输出序列\(\textcolor{Crimson}{y(t)}\)。明确地,该转移方程为
其中 \(\textcolor{Crimson}{A、B、C、D}\) 是转移矩阵。离散化后,输入和输出之间的关系可以写成卷积运算,可以在 GPU 上进行有效评估。
根据 HiPPO 理论,捕获长期依赖性的能力与 \(\textcolor{Crimson}{A ∈ R^{N×N}}\) 的特定初始化有关。HiPPO尝试将当前看到的所有输入信号压缩为系数向量,它使用矩阵\(\textcolor{Crimson}{A}\)构建一个"可以很好地捕获最近的token并衰减旧的token"状态表示。
而结构化状态空间序列模型(S4),通过将上述 SSM 块的多个copy与适当的归一化层、变压器风格的点式全连接层堆叠起来层,在各种序列分类任务上展示了出色的性能。
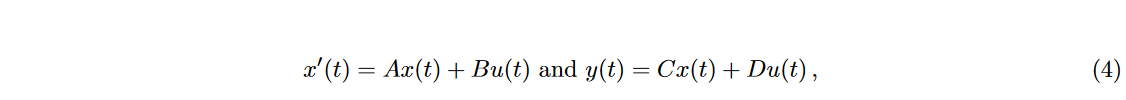
模型结构:将原始DiffWave中的双向空洞卷积层用S4层代替,即在加入扩散embedding后,在每个残差块中使用S4作为扩散层。同时,在与条件信息相加后引入第二个S4层。
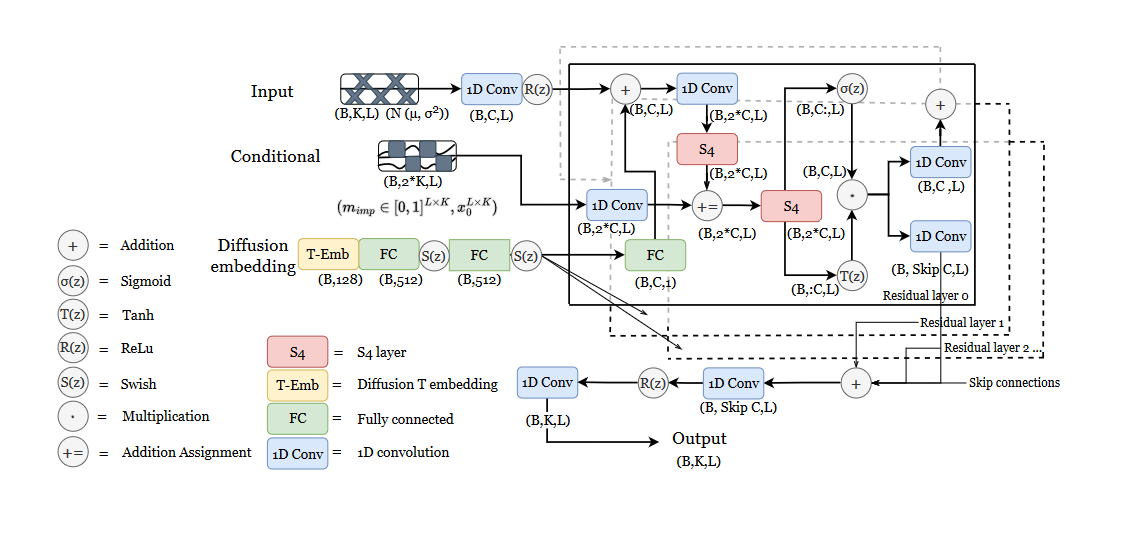
DiffWave的模型架构:
DiffWave模型包括堆叠的N个残差层,残差通道数为C ,这些残差层被分为m 个blocks,每个block包含\(n=\frac{N}{m}\) 层。每个残差层使用一个内核大小为3的双向空洞卷积,在每个block中的每一层上进行2倍膨胀,即\([ 1 , 2 , 4 , · · · , 2^{n-1}]\)。最后对所有残差层的输出进行跳跃连接。

训练过程:

训练过程中使用的目标函数有两种选择。与其他方法类似,目标函数可以是 DDPM 目标函数的简单条件变体:
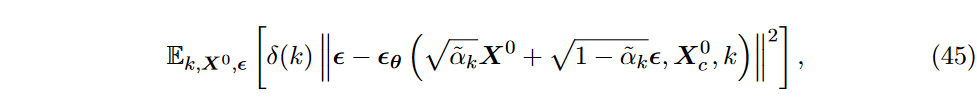
其中 \(\textcolor{DodgerBlue}{\theta}\) 默认构建在结构化状态空间模型上。目标函数的另一种选择仅使用已知数据进行计算,其数学表达式为
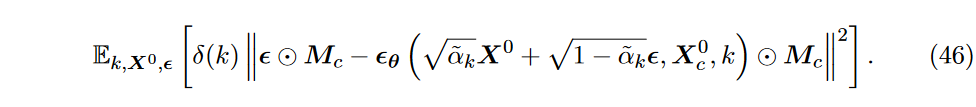
根据SSSD的说法,第二个目标函数在实践中通常是更好的选择。

推理过程:

为了进行预测,SSSD 采用通常的采样算法,并应用于 \(\textcolor{DodgerBlue}{X^0}\) 中的未知条目,即\(\textcolor{DodgerBlue}{(1-M_c) \bigodot X^0}\) 。
下图给出了PTB - XL填补任务中部分模型在BM情景下的填补结果。
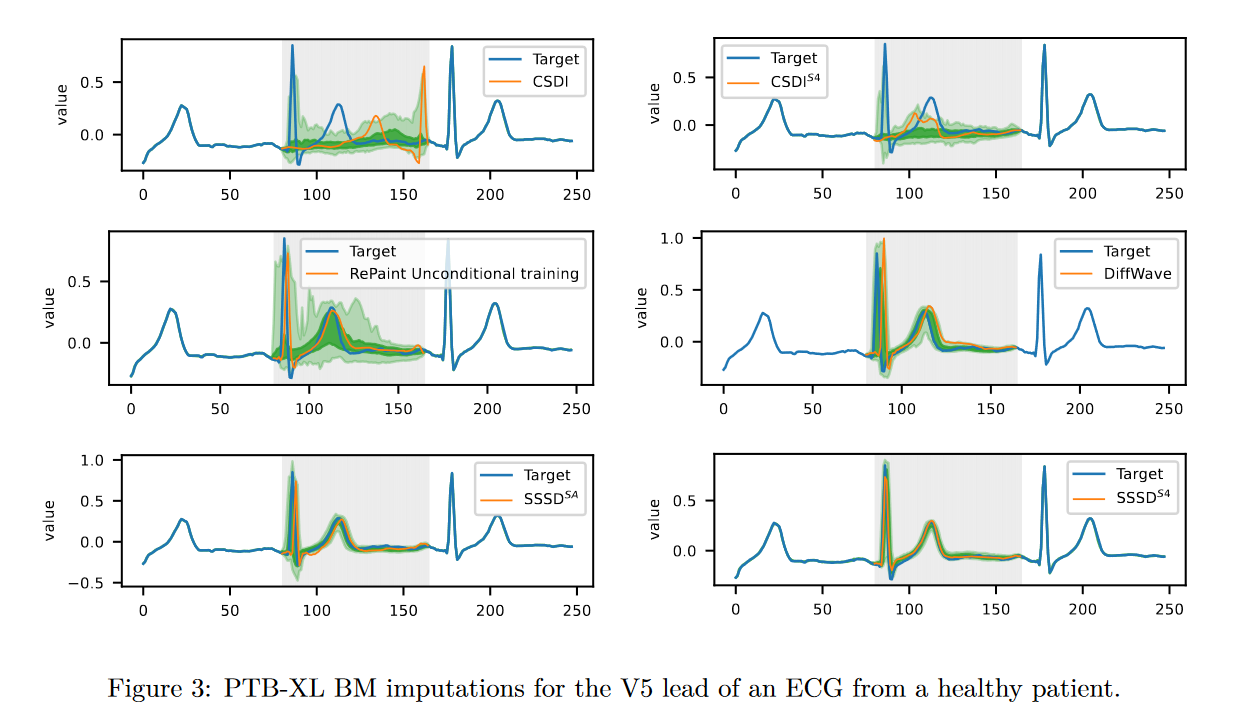
与 SSSD 一起提出的一个有趣的观点是插补模型也可以应用于预测任务。这是因为未来时间序列可以被视为 X0 右侧的一长串缺失值。

四、时间序列生成
时间序列生成是指创建类似于现实世界时间序列的合成数据的过程。由于时间序列数据的特征在于其时间依赖性,因此生成过程通常需要从过去的信息中学习潜在的模式和趋势。
1.问题表述
对于多元时间序列\(\textcolor{DodgerBlue}{X^0=\{x_1^0,x_2^0,...,x_T^0|x_i^0 \in R^D\}}\),时间序列生成问题旨在通过在时间点\(\textcolor{DodgerBlue}{t \in [2, T]}\)处生成的观测值\(\textcolor{DodgerBlue}{x^0_{t}}\),并考虑先前的历史数据\(\textcolor{DodgerBlue}{x^0_{1:t-1}}\)来合成时间序列\(\textcolor{DodgerBlue}{x^0_{1:T}}\)。相应地,目标分布为\(\textcolor{DodgerBlue}{t ∈ [2,T]}\)的条件密度\(\textcolor{DodgerBlue}{q(x_t^0 | x^0_{1:t-1})}\),相关的生成过程涉及对观测时段内所有时间点\(\textcolor{DodgerBlue}{x_t}\)的递归采样。