

一、引言
计算机视觉中的许多问题旨在将图像从一个领域转换到另一个领域,包括超分辨率、着色、修复、属性迁移和风格迁移。因此,这种跨域图像到图像的翻译设置受到了极大的关注。当数据集包含配对示例时,可以通过条件生成模型或简单回归模型来解决这个问题。在这项工作中,关注的是当这种监督不可用时更具挑战性的环境。在许多场景中,感兴趣的跨域映射是多模式的。例如,由于天气、时间、照明等原因,冬季场景在夏季可能有多种可能的出现。不幸的是,现有技术通常假设确定性 或单峰映射。因此,他们无法捕获可能输出的完整分布。即使通过注入噪声使模型变得随机,网络通常也会学会忽略它。
在本文中,作者提出了多模式无监督图像到图像翻译(MUNIT)问题的原则框架。如图 1(a)所示,该框架做出了几个假设。首先假设图像的潜在空间可以分解为内容空间和风格空间。作者进一步假设不同领域中的图像共享共同的内容空间,但不共享风格空间。为了将图像转换到目标域,将其内容编码与目标风格空间中的随机风格编码重新组合(图 1 (b))。
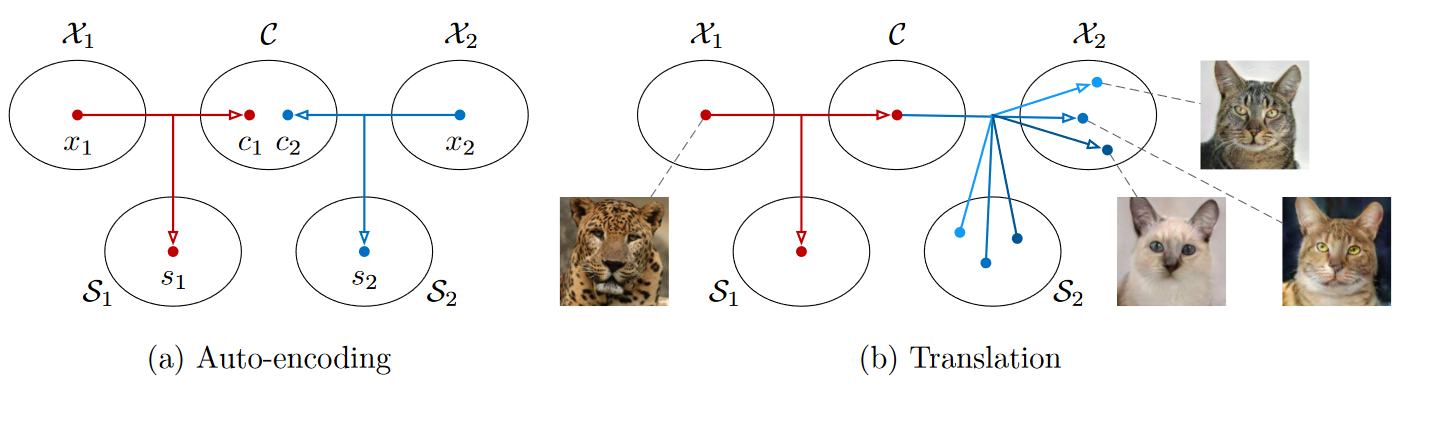
图 1:(a) 每个域中的图像\(\mathcal{X}_i\)被编码到共享内容空间 \(\mathcal{C}\) 和特定域样式空间 \(\mathcal{S}_i\)。每个编码器都有一个反向解码器,此图中省略了该解码器。(b) 为了将 \(\mathcal{X}_1\) 中的图像(例如,豹子)转换为 \(\mathcal{X}_2\)(例如,家猫),将输入的内容代码与目标样式空间中的随机样式编码重新组合。不同的样式编码导致不同的输出。
内容编码对翻译过程中应保留的信息进行编码,而风格编码表示输入图像中未包含的剩余变体。通过对不同风格的代码进行采样,MUNIT模型能够产生多样化和多模式的输出。大量的实验证明了该方法在多模态输出分布建模方面的有效性,以及与最先进的方法相比其卓越的图像质量。此外,内容和风格空间的分解允许我们的框架执行示例引导的图像翻译,其中翻译输出的风格由目标域中用户提供的示例图像控制。
二、MUNIT
1.假设
令\(\textcolor{blue}{x_1 \in \mathcal{X}_1}\)和\(\textcolor{blue}{x_2 \in \mathcal{X}_2}\)为来自两个不同图像域的图像。在无监督的图像到图像转换设置中,我们获得从两个边缘分布\(\textcolor{blue}{p(x_1)}\) 和\(\textcolor{blue}{p(x_2)}\)中抽取的样本,而无需访问联合分布\(\textcolor{blue}{p(x_1, x_2)}\)。我们的目标是使用学习的图像到图像转换模型\(\textcolor{blue}{p(x_{1→2}|x_1)}\) 和 \(\textcolor{blue}{p(x_{2→1}|x_2)}\)来估计两个条件 \(\textcolor{blue}{p(x_2|x_1)}\) 和 \(\textcolor{blue}{p(x_1|x_2)}\),其中 \(\textcolor{blue}{x_{1→2}}\) 是将\(\textcolor{blue}{x_1}\)转换为\(\textcolor{blue}{\mathcal{X}_2}\)生成的样本(与\(\textcolor{blue}{x_{2→1}}\)类似)。一般来说, \(\textcolor{blue}{p(x_2|x_1)}\) 和 \(\textcolor{blue}{p(x_1|x_2)}\)是复杂的多模态分布,在这种情况下,确定性翻译模型不能很好地工作。
为了解决这个问题,作者做出了部分共享的潜在空间假设。具体来说,假设每个图像 \(\textcolor{blue}{x_i \in \mathcal{X}_i}\) 是根据两个域共享的内容潜在编码 \(\textcolor{blue}{c\in \mathcal{C}}\) 和特定于各个域的风格潜在代码 \(\textcolor{blue}{s_i\in \mathcal{S}_i}\) 生成的。换句话说,联合分布中的一对对应图像 \(\textcolor{blue}{(x_1, x_2)}\) 由 \(\textcolor{blue}{x_1 = G_1^*(c, s_1)}\) 和 \(\textcolor{blue}{x_2 = G_2^*(c, s_2)}\) 生成,其中 \(\textcolor{blue}{c}\)、\(\textcolor{blue}{s_1}\)、\(\textcolor{blue}{s_2}\) 来自某些先验分布和 \(\textcolor{blue}{G_1^*}\)、\(\textcolor{blue}{G_2^*}\) 是底层生成器。进一步假设 \(\textcolor{blue}{G_1^*}\) 和 \(\textcolor{blue}{G_2^*}\) 是确定性函数,并且具有它们的逆编码器 \(\textcolor{blue}{E^*_1 = (G_1^*)^{−1}}\) 和 \(\textcolor{blue}{E^*_2= (G_2^*)^{−1}}\)。其目标是通过神经网络学习底层的生成器和编码器功能。请注意,尽管编码器和解码器是确定性的,但由于 \(\textcolor{blue}{s_2}\) 的依赖性,\(\textcolor{blue}{p(x_2|x_1)}\) 是连续分布。
MUNIT的假设与UNIT 中提出的共享潜在空间假设密切相关。虽然 UNIT 假设有一个完全共享的潜在空间,但MUNIT的假设只有一部分潜在空间(内容)可以在域之间共享,而另一部分(样式)是特定于域的,当跨域映射是多对多时,这是一个更合理的假设。
2.模型
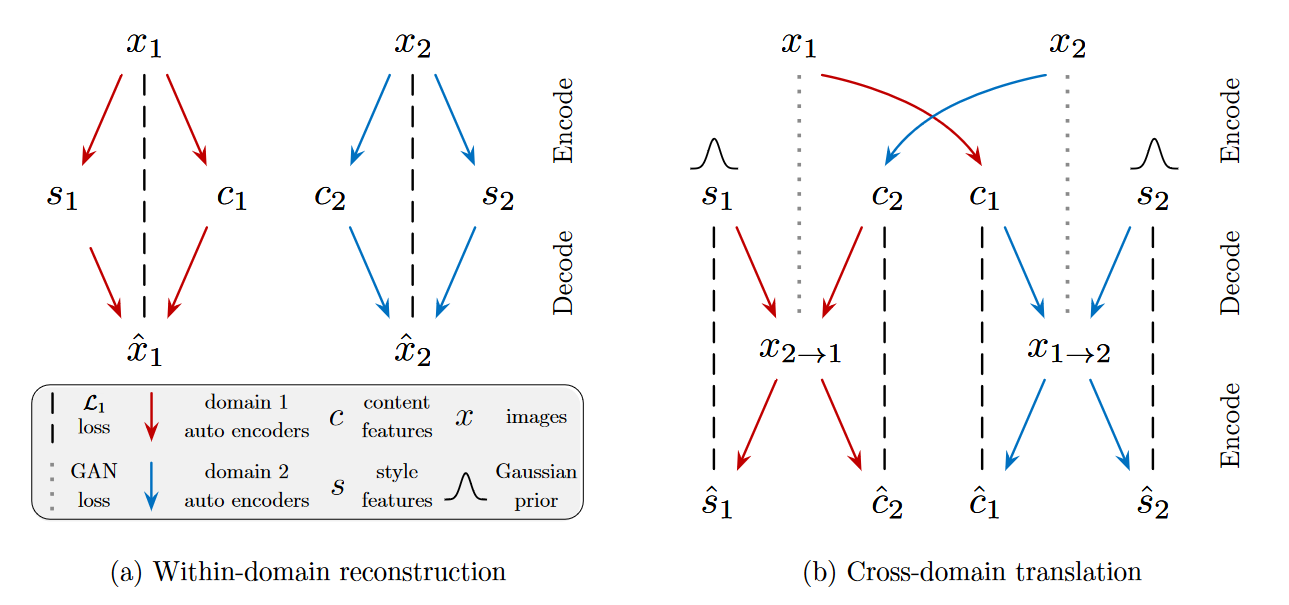
图 2:模型概述。MUNIT由两个自动编码器(分别用红色和蓝色箭头表示)组成,每个域一个。每个自动编码器的潜在编码由内容编码 \(c\) 和风格编码 \(s\) 组成。本文使用对抗性目标(虚线)训练模型,确保翻译后的图像与目标域中的真实图像无法区分,以及双向重建目标(虚线),用于重建图像和潜在代码。
图 2 显示了MUNIT模型及其学习过程的概述。其中翻译模型由每个域 \(\textcolor{blue}{\mathcal{X}_i}\) 的编码器\(\textcolor{blue}{E_i}\)和解码器\(\textcolor{blue}{G_i}\)组成\(\textcolor{blue}{(i = 1,2)}\)。如图 2 (a) 所示,每个自动编码器的潜在编码被分解为内容编码 \(\textcolor{blue}{c_i}\) 和风格编码\(\textcolor{blue}{s_i}\),其中 \(\textcolor{blue}{(c_i, s_i) = (E^c_i(x_i), E^s_i(x_i))= E_i(x_i)}\)。图像到图像的转换是通过交换编码器-解码器对来执行的,如图 2 (b) 所示。例如,为了将图像 \(\textcolor{blue}{x_1 \in X_1}\) 转换为 \(\textcolor{blue}{X_2}\),首先提取其内容潜在编码 \(\textcolor{blue}{c_1 = E^c_1(x_1)}\),并从先验分布 \(\textcolor{blue}{q(s_2) ∼ N(0,I)}\) 中随机抽取风格潜在编码 \(\textcolor{blue}{s_2}\)。然后,使用 \(\textcolor{blue}{G_2}\) 生成最终输出图像 \(\textcolor{blue}{x_{1→2} = G_2(c_1, s_2)}\)。我们注意到,尽管先验分布是单峰分布,但由于解码器的非线性,输出图像分布可以是多峰分布。
损失函数包括确保编码器和解码器相反的双向重建损失,以及将翻译图像的分布与目标域中的图像分布相匹配的对抗性损失。
双向重建损失:为了学习彼此相反的编码器和解码器对,使用在图像→潜在→图像和潜在→图像→潜在方向上进行重建的目标函数:
1️⃣图像重建:给定从数据分布中采样的图像,能够在编码和解码后重建它。
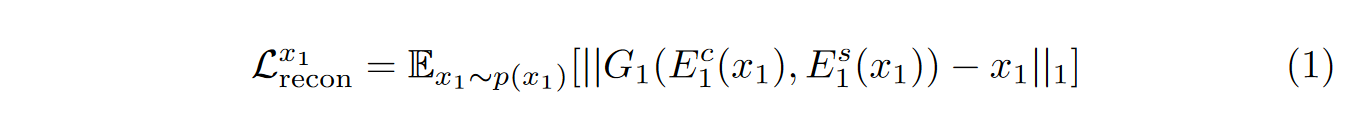
2️⃣潜在的重建:给定翻译时从潜在分布中采样的潜在代码(样式和内容),应该能够在解码和编码后重建它。
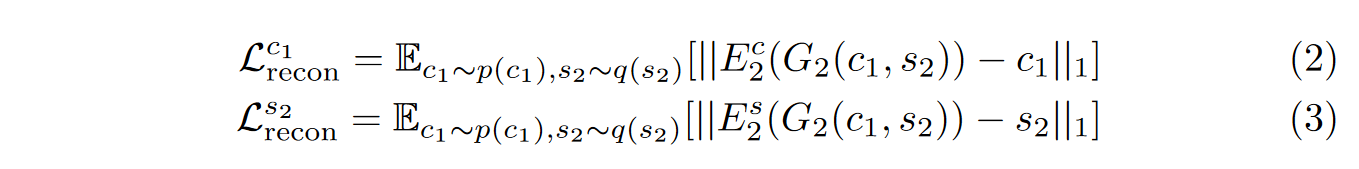
其中 \(\textcolor{blue}{q(s_2)}\) 是先验 \(\textcolor{blue}{N(0,I)}\),\(\textcolor{blue}{p(c_1)}\) 由 \(\textcolor{blue}{c_1 = E^c_1(x_1) }\)和 \(\textcolor{blue}{x_1 ∼ p(x_1)}\) 给出。
其他损失项 \(\textcolor{blue}{\mathcal{L}^{x_2}_{recon}}\)、\(\textcolor{blue}{\mathcal{L}^{c_2}_{recon}}\) 和 \(\textcolor{blue}{\mathcal{L}^{s_1}_{recon}}\) 的定义方式类似。作者使用 \(\textcolor{blue}{L_1}\) 重建损失,因为它鼓励清晰的输出图像。
风格重建损失 \(\textcolor{blue}{\mathcal{L}^{s_i}_{recon}}\) 它具有鼓励不同风格编码的多样化输出的效果。内容重建损失 \(\textcolor{blue}{\mathcal{L}^{c_i}_{recon}}\) 鼓励翻译图像保留输入图像的语义内容。
对抗性损失:使用 GAN 将翻译图像的分布与目标数据分布进行匹配。换句话说,模型生成的图像应该与目标域中的真实图像没有区别。
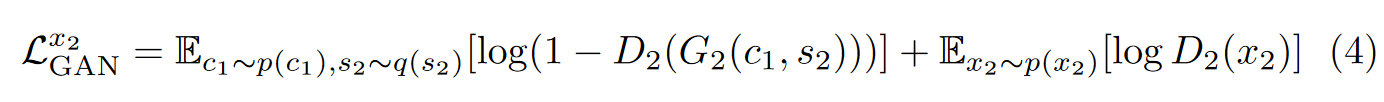
其中 \(\textcolor{blue}{D_2}\) 是一个鉴别器,试图区分 \(\textcolor{blue}{x_2}\) 中的翻译图像和真实图像。判别器 \(\textcolor{blue}{D_1}\) 和损失 \(\textcolor{blue}{L^{x_1}_{GAN}}\) 的定义类似。
总损失:联合训练编码器、解码器和鉴别器来优化最终目标,即对抗性损失和双向重建损失项的加权和。
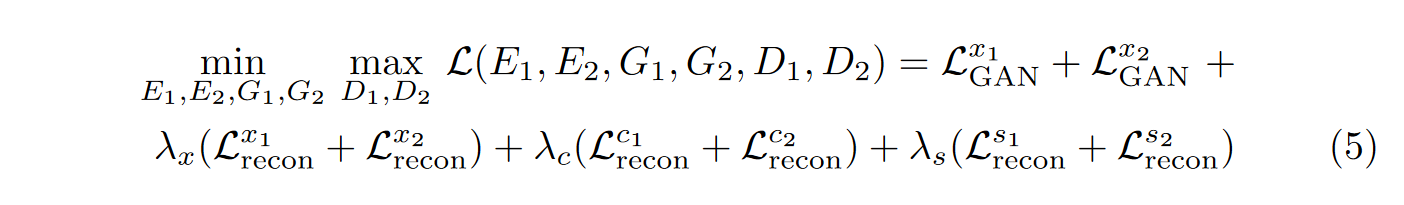
其中 \(\textcolor{blue}{λ_x}\)、\(\textcolor{blue}{λ_c}\)、\(\textcolor{blue}{λ_s}\) 是控制重建项重要性的权重。
三、理论分析
作者表明,所提出的最小化损失函数会导致:1)编码和生成期间潜在分布的匹配,2)由该框架引起的两个联合图像分布的匹配,以及3)强制执行弱形式的循环一致性约束。
首先,注意到方程中的总损失(式 5)是被最小化的。当转换后的分布与数据分布匹配并且编码器-解码器是逆向的。
命题1.假设存在E1,E2,G1,G2使得:1)E1=(G1)−1且E2=(G2)−1,且2)p (x1→2) = p(x2) 且 p(x2→1) = p(x1)。那么 E* 1, E* 2, G1, G2 最小化 L(E1, E2, G1, G2) = max D1 ,D2 L(E1, E2, G1, G2, D1, D2) (方程 (5) )。