

一、引言
许多计算机视觉问题可以表现为图像到图像的转换问题,将一个域中的图像映射到另一个域中的相应图像。例如,超分辨率可以被认为是一个将低分辨率图像映射到对应的高分辨率图像的问题;彩色化可以被视为将灰度图像映射到相应的彩色图像的问题。该问题可以在监督和无监督学习环境中进行研究。在监督设置中,可以使用不同域中的成对对应图像。在无监督设置中,我们只有两组独立的图像,其中一组由一个域中的图像组成,另一组由另一个域中的图像组成 - 不存在配对示例来显示如何将图像转换为另一个域中的相应图像。由于缺乏相应的图像,无监督图像到图像翻译(UNIT)问题被认为更困难,但它更适用,因为训练数据收集更容易。
从概率建模的角度分析图像翻译问题时,关键的挑战是学习不同领域图像的联合分布。在无监督设置中,这两个集合由来自两个不同域中的两个边缘分布的图像组成,任务是使用这些图像推断联合分布。耦合理论指出,存在无限组联合分布,通常可以达到给定的边际分布。因此,从边际分布推断联合分布是一个非常不适定的问题。为了解决不适定问题,我们需要对联合分布的结构进行额外的假设。
为此,作者提出共享潜在空间假设,假设不同域中的一对对应图像可以映射到共享潜在空间中的相同潜在表示。基于这个假设,作者提出了一个基于生成对抗网络(GAN)和变分自动编码器(VAE)的 UNIT 框架。我们使用 VAE-GAN 对每个图像域进行建模。对抗训练目标与权重共享约束相互作用,权重共享约束强制共享潜在空间,以生成两个域中的相应图像,而变分自动编码器将翻译后的图像与各自域中的输入图像相关联。我们将所提出的框架应用于各种无监督图像到图像翻译问题,并取得了高质量的图像翻译结果。我们还将其应用于领域适应问题,并在基准数据集上实现了最先进的精度。共享潜在空间假设在耦合 GAN 中用于联合分布学习。在这里,我们扩展了针对 UNIT 问题的 Coupled GAN 工作。我们还注意到,一些当代作品提出了循环一致性约束假设,它假设存在循环一致性映射,以便源域中的图像可以映射到目标域中的图像,并且这目标域中的翻译图像可以映射回源域中的原始图像。在本文中,我们表明共享潜在空间约束意味着循环一致性约束。
二、假设
设\(\textcolor{blue}{\mathcal{X}_1}\)和\(\textcolor{blue}{\mathcal{X}_2}\)为两个图像域。在有监督的图像到图像转换中,我们得到从联合分布\(\textcolor{blue}{P_{\mathcal{X}_1,\mathcal{X}_2} (x_1, x_2)}\) 中抽取的样本 \(\textcolor{blue}{(x_1, x_2)}\)。在无监督图像到图像的转换中,我们获得从边缘分布\(\textcolor{blue}{P_{\mathcal{X}_1} (x_1)}\) 和\(\textcolor{blue}{P_{\mathcal{X}_2} (x_2)}\) 中抽取的样本。由于无限组可能的联合分布可以产生给定的边际分布,因此在没有额外假设的情况下,我们无法从边际样本中推断出任何有关联合分布的信息。
作者提出共享潜在空间假设,如图 1 所示。
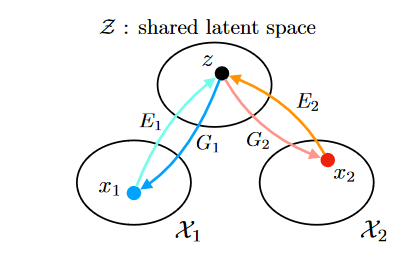
我们假设对于任何给定的图像对\(\textcolor{blue}{x_1}\)和\(\textcolor{blue}{x_2}\),在共享潜在空间中存在一个共享潜在表示\(\textcolor{blue}{z}\) ,并假设存在函数 \(\textcolor{blue}{E^*_1}\)、\(\textcolor{blue}{E^*_2}\)、\(\textcolor{blue}{G^*_1}\)和\(\textcolor{blue}{G^*_2}\) ,这样,给定联合分布中的一对对应图像\(\textcolor{blue}{(x_1,X_2)}\),我们有\(\textcolor{blue}{z=E^*_1(x_1)=E^*_2(x_2)}\) ,相反\(\textcolor{blue}{x_1 = G^*_1(z)}\) 和\(\textcolor{blue}{x_2 = G^*_2(z)}\) 。
在该模型中,从\(\textcolor{blue}{\mathcal{X}_1}\) 映射到\(\textcolor{blue}{\mathcal{X}_2}\)的函数 \(\textcolor{blue}{x_2 = F^*_{1→2}(x_1)}\) 可以由组合\(\textcolor{blue}{F^*_{1→2}(x_1) = G_2^*(E^*_1(x_1))}\) 表示。类似地,\(\textcolor{blue}{x_1 = F^*_{2→1}(x_2)=G_1^*(E^*_2(x_2))}\)。那么UNIT问题就变成了学习\(\textcolor{blue}{F^*_{1→2}}\)和\(\textcolor{blue}{F^*_{2→1}}\)的问题。我们注意到,\(\textcolor{blue}{F^*_{1→2}}\)和\(\textcolor{blue}{F^*_{2→1}}\)存在的必要条件是循环一致性约束:\(\textcolor{blue}{x_1 = F^*_{2→1}(F^*_{1→2}(x_1))}\)和\(\textcolor{blue}{x_2 = F^*_{1→2}(F^*_{2→1}(x_2))}\)。我们可以通过翻译回翻译后的输入图像来重建输入图像。换句话说,所提出的共享潜在空间假设意味着循环一致性假设(但反之则不然)。
为了实现共享潜在空间假设,进一步假设一个共享的中间表示 \(\textcolor{blue}{h}\),使得生成一对对应图像的过程承认以下形式:
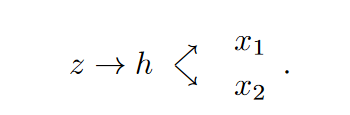
因此,我们有 \(\textcolor{blue}{G_1^* ≡ G^*_{L,1} ◦ G^*_H}\) 和\(\textcolor{blue}{G_2^* ≡ G^*_{L,2} ◦ G^*_H}\),其中 \(\textcolor{blue}{G^*_H}\) 是将\(\textcolor{blue}{z}\)映射到 \(\textcolor{blue}{h}\)的常见高级生成函数,\(\textcolor{blue}{G^*_{L,1}}\) 和 \(\textcolor{blue}{G^*_{L,2}}\) 是将\(\textcolor{blue}{h}\)映射到的低级生成函数分别为\(\textcolor{blue}{x_1}\)和 \(\textcolor{blue}{x_2}\)。
在多域图像翻译的情况下(例如,晴天和雨天图像翻译),\(\textcolor{blue}{z}\)可以被视为场景的紧凑的高级表示(“前面有车,后面有树”),\(\textcolor{blue}{h}\)可以是通过\(\textcolor{blue}{G^*_H}\)考虑\(\textcolor{blue}{z}\)的特定实现(“汽车/树占据以下像素”),并且\(\textcolor{blue}{G^*_{L,1}}\) 和 \(\textcolor{blue}{G^*_{L,2}}\)将是每种模态中的实际的图像形成函数(“树是郁郁葱葱的绿色”)在晴天区域,但在雨天区域为深绿色”)。假设\(\textcolor{blue}{h}\)还允许我们用\(\textcolor{blue}{E_1^* ≡ E^*_{L,1} ◦ E^*_H}\) 和 \(\textcolor{blue}{E_2^* ≡ E^*_{L,2} ◦ E^*_H}\) 表示\(\textcolor{blue}{E^*_1}\)和\(\textcolor{blue}{E^*_2}\)。在下一节中,我们将讨论如何在提议的 UNIT 框架中实现上述想法。
三、框架
本文提出的模型框架如图 1 所示,基于变分自动编码器 (VAE) 和生成对抗网络 (GAN) 。它由6个子网络组成:包括两个域图像编码器\(\textcolor{blue}{E_1}\)和\(\textcolor{blue}{E_2}\),两个域图像生成器\(\textcolor{blue}{G_1}\)和\(\textcolor{blue}{G_2}\),以及两个域对抗鉴别器\(\textcolor{blue}{D_1}\)和\(\textcolor{blue}{D_2}\)。使用 CNN 表示\(\textcolor{blue}{E_1}\),\(\textcolor{blue}{E_2}\),\(\textcolor{blue}{G_1}\)和\(\textcolor{blue}{G_2}\),并使用权重共享约束实现共享潜在空间假设,其中\(\textcolor{blue}{E_1}\)和\(\textcolor{blue}{E_2}\)中最后几层(高层层)的连接权重是相连的(用虚线表示)并且\(\textcolor{blue}{G_1}\)和\(\textcolor{blue}{G_2}\)中前几层(高层)的连接权重是相连的。这里, \(\textcolor{blue}{\tilde{x}^{1→1}_1}\) 和\(\textcolor{blue}{\tilde{x}^{2→2}_2}\) 是自重建图像,\(\textcolor{blue}{\tilde{x}^{1→2}_1}\) 和\(\textcolor{blue}{\tilde{x}^{2→1}_2}\)是域翻译图像。 \(\textcolor{blue}{D_1}\)和\(\textcolor{blue}{D_2}\)是各自领域的对抗性判别器,负责评估翻译后的图像是否真实。

有多种方法可以解释子网络的角色,我们在表 1 中进行了总结。我们的框架一次性学习两个方向的翻译。

VAE:编码器-生成器对\(\textcolor{blue}{\{E_1,G_1\}}\)构成\(\textcolor{blue}{\mathcal{X}_1}\)域的 VAE,称为 VAE1。对于输入图像\(\textcolor{blue}{x_1 \in \mathcal{X}_1}\),VAE1 首先通过编码器\(\textcolor{blue}{E_1}\)将\(\textcolor{blue}{x_1}\)映射到潜在空间 \(\textcolor{blue}{Z}\) 中的编码,然后通过生成器 \(\textcolor{blue}{G_1}\)解码该编码的随机扰动版本以重建输入图像。我们假设潜在空间 \(\textcolor{blue}{Z}\) 中的分量是条件独立的并且具有单位方差的高斯分布。在我单位矩阵。重建图像为\(\textcolor{blue}{\tilde{x}^{1→1}_1 = G_1(z_1 ∼ q_1(z_1|x_1))}\)。请注意,这里滥用了该符号,因为我们将\(\textcolor{blue}{q_1(z_1|x_1)}\)的分布视为 \(\textcolor{blue}{N(E_{μ,1}(x_1), I)}\) 的随机向量并从中采样。类似地,\(\textcolor{blue}{\{E_2,G_2\}}\)构成\(\textcolor{blue}{\mathcal{X}_2}\)的 VAE2,其中编码器\(\textcolor{blue}{E_2}\)输出平均向量 \(\textcolor{blue}{E_{μ,2}(x2)}\) 且潜在编码\(\textcolor{blue}{E_2}\)的分布由\(\textcolor{blue}{q_2(z_2|x_2)≡ N (z_2| E_{μ,2}(x_2),I)}\)。重建图像为\(\textcolor{blue}{\tilde{x}^{2→2}_2 = G_2(z_2 ∼ q_2(z_2|x_2))}\)。
利用重新参数化技巧,不可微采样操作可以使用辅助随机变量重新参数化为可微操作。这种重新参数化技巧允许我们使用反向传播来训练 VAE。令\(\textcolor{blue}{η}\)为具有多元高斯分布的随机向量: \(\textcolor{blue}{η ∼ N (η|0, I)}\)。 \(\textcolor{blue}{z_1 ∼ q_1(z_1|x_1)}\) 和\(\textcolor{blue}{z_2 ∼ q_2(z_2|x_2)}\) 的采样操作可以分别通过 \(\textcolor{blue}{z_1 = E_{μ,1}(x_1) + η}\)和 \(\textcolor{blue}{z_2 = E_{μ,2}(x_2) + η }\)来实现。
共享权重:基于第 2 节中讨论的共享潜在空间假设,我们强制执行权重共享约束来关联两个 VAE。具体来说,共享 \(\textcolor{PaleVioletRed}{E_1}\) 和 \(\textcolor{PaleVioletRed}{E_2}\) 的最后几层的权重,这些权重负责提取两个域中输入图像的高级表示。类似地,共享 \(\textcolor{PaleVioletRed}{E_2}\) 和 \(\textcolor{PaleVioletRed}{G_2}\) 的前几层的权重,这些层负责解码用于重建输入图像的高级表示。
请注意,仅权重共享约束并不能保证两个域中的相应图像具有相同的潜在代码。在无监督设置中,两个域中不存在一对相应的图像来训练网络输出相同的潜在代码。一对相应图像的提取潜在代码通常不同。即使它们是相同的,相同的潜在成分在不同的领域也可能具有不同的语义含义。因此,仍然可以解码相同的潜在代码以输出两个不相关的图像。然而,我们可以通过对抗训练,两个域中的一对对应图像可以分别通过 \(\textcolor{PaleVioletRed}{E_1}\) 和 \(\textcolor{PaleVioletRed}{E_2}\) 映射到一个公共的潜在代码,并且一个潜在代码将分别映射到 \(\textcolor{PaleVioletRed}{G_1}\) 和 \(\textcolor{PaleVioletRed}{G_2}\) 两个域中的一对对应图像。
共享潜在空间假设允许我们执行图像到图像的转换。我们可以通过应用 \(\textcolor{PaleVioletRed}{G_2(z_1 ∼ q_1(z_1|x_1))}\) 将 \(\textcolor{PaleVioletRed}{X_1}\) 中的图像 \(\textcolor{PaleVioletRed}{x_1}\) 转换为 \(\textcolor{PaleVioletRed}{X_2}\) 中的图像。作者将这种信息处理流称为图像翻译流。建议的框架中存在两个图像转换流:\(\textcolor{PaleVioletRed}{X_1 → X_2}\) 和 \(\textcolor{PaleVioletRed}{X_2 → X_1}\)。这两个流与来自VAE的两个图像重建流联合训练。一旦我们可以确保一对相应的图像映射到相同的潜在代码,并且将相同的潜在代码解码为一对相应的图像,\(\textcolor{PaleVioletRed}{(x_1, G_2(z_1 ∼ q_1(z_1|x_1)))}\)将形成一对相应的图像。换言之,对于第 2 节中讨论的无监督图像到图像转换,\(\textcolor{PaleVioletRed}{E_1}\) 和 \(\textcolor{PaleVioletRed}{G_2}\) 函数的组成近似于 \(\textcolor{PaleVioletRed}{F^*_{1→2}}\),而 \(\textcolor{PaleVioletRed}{E_2}\) 和 \(\textcolor{PaleVioletRed}{G_1}\) 函数的组成近似于 \(\textcolor{PaleVioletRed}{F^*_{2→1}}\)
GAN:该框架当中包含两个生成对抗网络:\(\textcolor{Darkorange}{GAN_1 = \{D_1, G_1\}}\) 和 \(\textcolor{Darkorange}{GAN_2 = \{D_2, G_2\}}\)。在 GAN1 中,对于从第一个域采样的真实图像,\(\textcolor{Darkorange}{D_1}\) 应输出 true,而对于 \(\textcolor{Darkorange}{G_1}\) 生成的图像,应输出 false。\(\textcolor{Darkorange}{G_1}\) 可以生成两种类型的图像:1️⃣来自重建流的图像 \(\textcolor{Darkorange}{\tilde{x}^{1→1}_1 = G_1(z_1 ∼ q_1(z_1|x_1))}\) 和 2️⃣来自翻译流的图像 \(\textcolor{Darkorange}{\tilde{x}^{2→1}_2 = G_1(z_2 ∼ q_2(z_2|x_2))}\)。由于重建流可以进行监督训练,因此只需对来自翻译流的图像应用对抗性训练就足够了。对 GAN2 应用了类似的处理,其中 \(\textcolor{Darkorange}{D_2}\) 被训练为从第二个域数据集采样的真实图像输出 true,而从 \(\textcolor{Darkorange}{G_2}\) 生成的图像输出 false
Cycle-consistency (CC):由于共享潜在空间假设隐含了循环一致性约束(见第 2 节),我们还可以在所提出的框架中强制执行循环一致性约束,以进一步规范病态的无监督图像到图像转换问题。由此产生的信息处理流称为循环重构流
Learning:本文共同解决了\(\textcolor{Purple}{VAE_1、VAE_2、GAN_1}\)和\(\textcolor{Purple}{GAN_2}\)在图像重建流、图像翻译流和循环重建流中的学习问题:
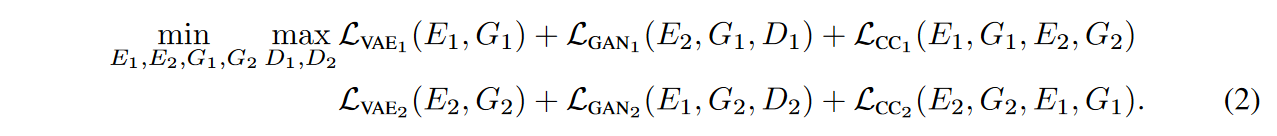
VAE训练旨在最小化变分上限 在(2)中,VAE对象是
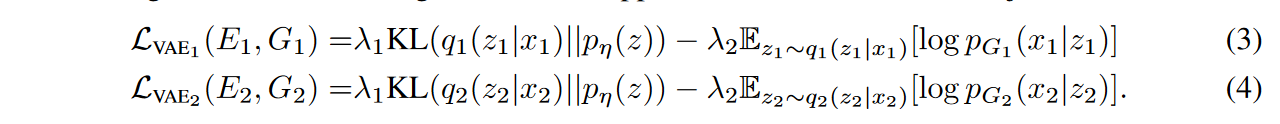
其中,超参数 \(\textcolor{Purple}{λ_1}\) 和 \(\textcolor{Purple}{λ_2}\) 控制目标项的权重,而 KL 散度项则惩罚潜在代码分布与先前分布的偏差。正则化提供了一种从潜在空间进行采样的简单方法。我们分别使用拉普拉斯分布对 \(\textcolor{Purple}{p_{G_1}}\) 和 \(\textcolor{Purple}{p_{G_2}}\) 进行建模。因此,最小化负对数似然项等同于最小化图像与重建图像之间的绝对距离。先验分布为零均值高斯 \(\textcolor{Purple}{p_η(z) = N (z|0,I)}\)。
在(2)中,GAN目标函数由下式给出
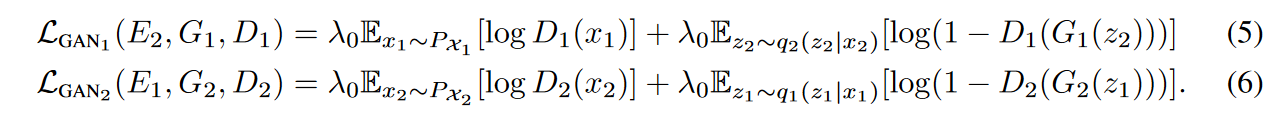
公式(5)和(6)中的目标函数是条件GAN目标函数。它们分别用于确保翻译的图像与目标域中的图像相似。超参数 \(λ_0\) 控制 GAN 目标函数的影响。
作者使用类似 VAE 的目标函数来对周期一致性约束进行建模,其公式为:
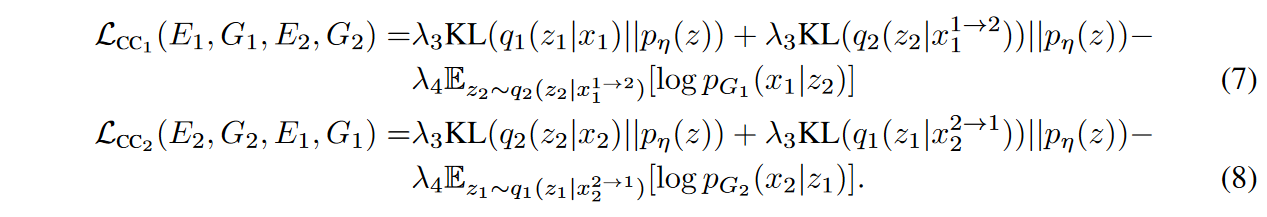
其中,负对数似然目标项确保两次翻译的图像与输入图像相似,而KL项惩罚了在循环重建流中偏离先前分布的潜在代码(因此,有两个KL项)。超参数 \(\textcolor{Purple}{λ_3}\) 和 \(\textcolor{Purple}{λ_4}\) 控制两个不同目标项的权重。
继承了GAN,对所提出的框架的训练导致了求解最小最大化问题,其中优化旨在找到一个鞍点。具体来说,首先应用梯度上升步骤来更新 \(\textcolor{Purple}{D_1}\) 和 \(\textcolor{Purple}{D_2}\),而\(\textcolor{Purple}{E_1}\)、\(\textcolor{Purple}{E_2}\)、\(\textcolor{Purple}{G_1}\) 和 \(\textcolor{Purple}{G_2}\) 保持不变。然后,我们应用梯度下降步骤来更新 \(\textcolor{Purple}{E_1}\)、\(\textcolor{Purple}{E_2}\)、\(\textcolor{Purple}{G_1}\) 和 \(\textcolor{Purple}{G_2}\),\(\textcolor{Purple}{D_1}\) 和 \(\textcolor{Purple}{D_2}\) 固定不变。
Translation:经过学习,通过组装子网络的一个子集来获得两个图像翻译函数。即 \(\textcolor{Crimson}{F_{1→2}(x_1) = G_2(z_1 ∼ q_1(z_1|x_1))}\) 用于将图像从 \(\textcolor{Crimson}{X_1}\) 转换为 \(\textcolor{Crimson}{X_2}\),\(\textcolor{Crimson}{F_{2→1}(x_2) = G_1(z_2 ∼ q_2(z_2|x_2))}\)用于将图像从 \(\textcolor{Crimson}{X_2}\) 转换为 \(\textcolor{Crimson}{X_1}\)。
四、实验
首先分析了所提出的框架的各个组成部分。然后,作者在具有挑战性的翻译任务中展示视觉结果。最后,作者将他们的框架应用于领域适配任务。
性能分析:本文使用 ADAM 进行训练,其中学习率设置为 0.0001,动量设置为 0.5 和 0.999。每个小批量由来自第一个域的一张图像和来自第二个域的一张图像组成。我们的框架有几个超参数。默认值为 \(\textcolor{blue}{λ_0 = 10}\)、\(\textcolor{blue}{λ_3 = λ_1 = 0.1}\) 和 \(\textcolor{blue}{λ_4 = λ_2 = 100}\)。对于网络架构,编码器由 3 个卷积层作为前端和 4 个基本残差块 作为后端组成。生成器由 4 个基本残差块作为前端和 3 个转置卷积层作为后端组成。鉴别器由卷积层堆栈组成。使用 LeakyReLU 来表示非线性。
我们使用了地图数据集 [8](如图 2 所示),该数据集在两个域(卫星图像和地图)中包含相应的图像对,可用于定量评估。在这里,目标是学习在卫星图像和地图之间进行转换。我们在无监督环境中进行操作,其中我们使用来自训练集的 1096 张卫星图像作为第一个域,使用来自验证集的 1098 张地图作为第二个域。我们进行了 100K 次迭代训练,并使用最终模型在测试集中翻译了 1098 张卫星图像。然后,我们比较了翻译的卫星图像(应该是地图)和相应的地面实况地图之间的差异。如果色差在真值的 16 以内,则计算为像素转换正确。我们使用测试集中图像的平均像素准确度作为性能指标。我们可以使用色差来测量翻译精度,因为目标翻译函数是单峰的。我们没有评估从地图到图像的翻译,因为翻译是多模态的,这很难构建一个合适的评估指标。