

一、引言
为了应对图像翻译的挑战,已经提出了几种基于生成对抗网络(GAN)的方法。在这些技术中,生成模型通常直接对目标模态进行建模,从而确保翻译的真实性。然而,基于GAN的设计通常包含复杂的对抗结构,并要求为不同的翻译工作量身定制特定于模态的损失函数。虽然基于 GAN 的翻译可以在训练阶段在没有匹配数据集的情况下运行,但它们仍然取决于来自原始域的数据。这种依赖性可能会带来困难,特别是当源域数据稀缺时,使循环一致性训练的平衡复杂化。当目标模式的样本数量很少时,这个问题变得更加明显。
最近的研究揭示了基于分数的生成模型优于基于GAN的模型。Muzaffer等引入了SynDiff,这是一个具有循环一致性和双重扩散的框架,用于增强语义对齐。尽管如此,这种方法需要双倍的计算开销,需要预训练生成器来评估相关的源图像,并要求源域数据,这与零样本学习范式不同。同时,Meng等建议利用扩散模型(称为SDEdit)通过零样本学习实现图像翻译。与基于GAN的模型相比,SDEdit通过其简化的模型配置和更直接的损失函数表现出优势。然而,在跨模态翻译上下文中出现了 SDEdit 的局限性。它是在基于扰动的制导下预测的,该制导固有地假设原始模态和目标模态都可以均匀地受到噪声的影响。这种假设在跨模态图像翻译中通常被证明是无效的,例如,从 MRI PDw 过渡到 T1 成像。
为了解决零样本学习在跨模态翻译中带来的障碍,本文的方法利用统计特征的同质性来调节为零样本跨模态图像翻译量身定制的扩散模型。该策略利用了原点和目标模态之间的联系,利用它们的局部统计特征,通过扩散范式实现跨模态图像转换。图 1 说明了统计特征驱动扩散模型(LMI:Locale-based Mutual Information),该模型对跨模态图像分割执行零样本图像翻译。本文介绍的是一个无监督的零样本学习框架,能够在以前看不见的模式中导航翻译。

图1:原理图显示了用于零样本跨模态分割的 LMI 引导扩散。蓝色和橙色等值线是源分布和目标分布。橙色等值线中的蓝点表示源分布中源数据点的目标数据点(蓝色等值线中的橙色点)。LMIDiffusion 使用显式统计特征 (LMI) 来导航下一步(黄点),从头到尾提供连续指导(黄点)。最后,可以使用仅在目标模态上训练的任意分割方法对翻译后的图像进行分割。
二、方法
1.用于跨模态图像翻译的扩散模型
跨模态图像翻译可以通过分数匹配框架来解决,该框架用于生成基于源数据 \(\textcolor{blue}{G}\) 的目标数据(表示为 \(\textcolor{blue}{F}\))。然后使用扰动源域\(\textcolor{blue}{G}\)来调节逐步扩散过程。然而,当从图像翻译的零样本学习的角度来看时,在学习阶段仍然无法访问来自源域的数据。然而,据推测,源模式和目标模式之间的局部统计属性具有相似性。最大化互信息(MI)已被验证为一种有效的策略,可以使神经结构具有模拟非线性映射的能力。为了捕捉这些用于图像翻译的共享表示,作者建议使用互相信息作为指导对去噪过程中的局部统计特征进行建模。
2.局部引导互信息
为了从数据集中提取语义信息以进行调节,有必要将原始数据转换为MI封装的统计特征。给定图像 \(\textcolor{blue}{X}\),对于位置 \(\textcolor{blue}{i}\)处的点 \(\textcolor{blue}{x_i \in X}\),可以通过 \(\textcolor{blue}{x_i}\) 的邻域 \(\textcolor{blue}{\delta_{x_i}}\) 的概率密度函数 (PDF)\(\textcolor{blue}{p_{δ_{x_i}}(·)}\) 捕获 \(\textcolor{blue}{i}\) 处的局部统计信息。
关于位于 \(\textcolor{blue}{x_i}\) 的邻域 \(\textcolor{blue}{\delta_{x_i}}\) 内的其他数据点(表示为 \(\textcolor{blue}{x_j}\)),它的统计特征可以通过 PDF:\(\textcolor{blue}{p_{δ_{x_j}}(·)}\)确定,其中 \(\textcolor{blue}{j}\) 是 \(\textcolor{blue}{\delta_i}\) 的一个元素。在 点\(\textcolor{blue}{x_i}\) 处从图像 \(\textcolor{blue}{X}\) 到图像 \(\textcolor{blue}{Y}\) 的局部互信息(LMI) 通过以下方式定义:
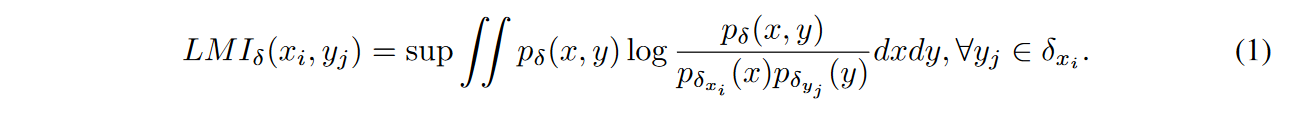
作者采用方程 1 作为指导,以调节扩散的每个训练步骤。这是通过在分数网络的整个训练步骤中评估 \(\textcolor{blue}{LMI(x_0,y_t)、t \in [0,T]}\)来实现的。
性质1: 在\(i\)处位置从\(\textcolor{blue}{X}\) 到 \(\textcolor{blue}{Y}\) 的LMI上界为:\(\textcolor{blue}{LMI_\delta(x_i,y_i) \leq LMI_\delta(x_i,x_i)}\),这是点\(\textcolor{blue}{x_i}\)处\(\textcolor{blue}{X}\) 和\(\textcolor{blue}{Y}\)之间的最佳信息匹配。
性质2:LMIDiffusion 生成的翻译误差为 \(\textcolor{blue}{\lim\limits_{∆LMI→0} ∆E\hat{F} = 0}\)。
在补充部分,作者证明了性质 1 和 2。性质 1 强调 LMI 在以下条件下达到统计全等:\(\textcolor{blue}{p_δ(X)=p_δ(Y ), ∀δ \in X}\)。因此,在整个训练迭代过程中,LMI 在训练步骤中始终在 \(\textcolor{blue}{X_0}\) 和 \(\textcolor{blue}{X_t}\) 之间的相同位置达到峰值。然而,当 \(\textcolor{blue}{p_δ(X) \neq p_δ(Y)}\)时,LMI 在 \(\textcolor{blue}{j}\) 处达到局部最大值,该 \(\textcolor{blue}{j}\) 位于 \(\textcolor{blue}{y_i}\) 的邻域 \(\textcolor{blue}{δ_{y_i}}\) 中。通过将迭代互信息计算转换为基于张量的运算,可以加快 MI 确定的过程。在GPU上执行时,这种张量操作可以通过内存复制和并行缩减等技术进一步受益于速度增强。
3.通过LMI调节扩散
在训练阶段,可以通过将数据点(表示为 \(\textcolor{blue}{F}\) )与其扰动对应物 \(\textcolor{blue}{F_t}\) 之间的 LMI 合并到分数网络(符号为 \(\textcolor{blue}{s_θ}\))中来指导噪声扰动过程。这是通过将分数匹配的训练目标调整为:
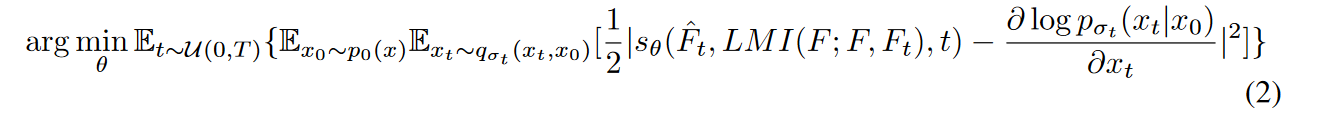
在采样阶段,我们可以将建议的条件算子集成到 SDE 中:
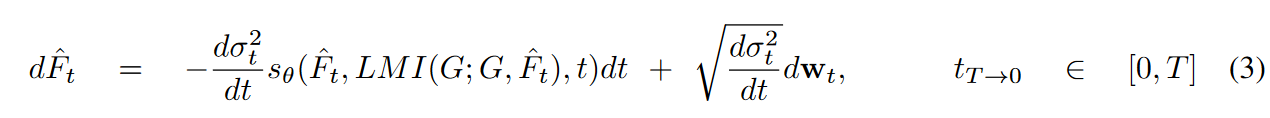
并使用朴素的 Euler-Maruyama 求解器来积分 SDE。采样图像可以通过专为目标域图像分割而设计的工具直接分割。
三、实验
数据集: 作者利用IXI dataset,该数据集包含来自健康受试者的 600 张预对齐多模态图像。并且承担PD和T1w模式之间的翻译任务。从IXI数据集的一个子集中,制定了一个由300个切片(从100个受试者中抽取)组成的训练集和一个由75个切片(从25名受试者中抽取)组成的测试集。
实验: 本文将 LMIDiffusion(无监督)与基于少样本学习的 CycleGAN(监督)翻译模型、基于 GAN 反转的方法(无监督)和基于扩散的方法 SDEdit (零样本监督学习与基于 SDE 的扰动引导)进行了比较。1️⃣本实验中的 CycleGAN(受监督)将被允许同时查看完整的目标域数据集和源域数据集的一小群(约占数据集 IXI 数据集的 11%)。2️⃣第二个基线是基于GAN反转的方法(无监督)。允许 StyleGAN2-ADA 查看目标域训练数据。在经过训练的StyleGAN2-ADA的潜在空间中,通过5000个反演优化步骤来执行域外引导生成。在生成步骤中引入了一个额外的网络进行反演。3️⃣SDEdit(无监督)使用分布扰动引导进行扩散。LMIDiffusion的分数网络结构与类似UNet的分数匹配网络相同,后者通过学习率为3e − 4的Adam优化器进行优化。该模型在具有四个 Tesla V100 GPU 的 NVIDIA DGX Station 上进行了训练,迭代次数超过 300K。对于分割后端,作者采用了 K-Means(5 个聚类)算法,该算法专门针对目标模态进行训练。随后对从上述各种方法获得的翻译结果进行了分割。
结果:图 2 显示了各种模型的翻译和分割结果。底部行提供了基于翻译图像的分割结果的清晰说明。值得注意的是,从 LMIDiffusion 转换派生的分割与分割基本事实密切相关。虽然使用在目标图像上训练的方法进行直接分割对于源域图像不可行,但在翻译后的图像上产生了值得称赞的分割结果。LMIDiffusion翻译的结果不仅提供了与翻译靶点 (PDw) 的最大相似性,而且还保留了原始模态 (T1w) 的优越解剖学特征。尽管 CycleGAN 使用监督(少镜头)数据进行训练,但它无法生成高质量的图像。这一缺点可归因于基于GAN的模型难以辨别源模态和目标模态之间的关系,因为来自两个领域的训练数据有限。另一方面虽然 SDEdit 确实在 PDw 域中生成图像,但它损害了原始域的解剖特征,使其在零镜头图像分割方面效果较差。
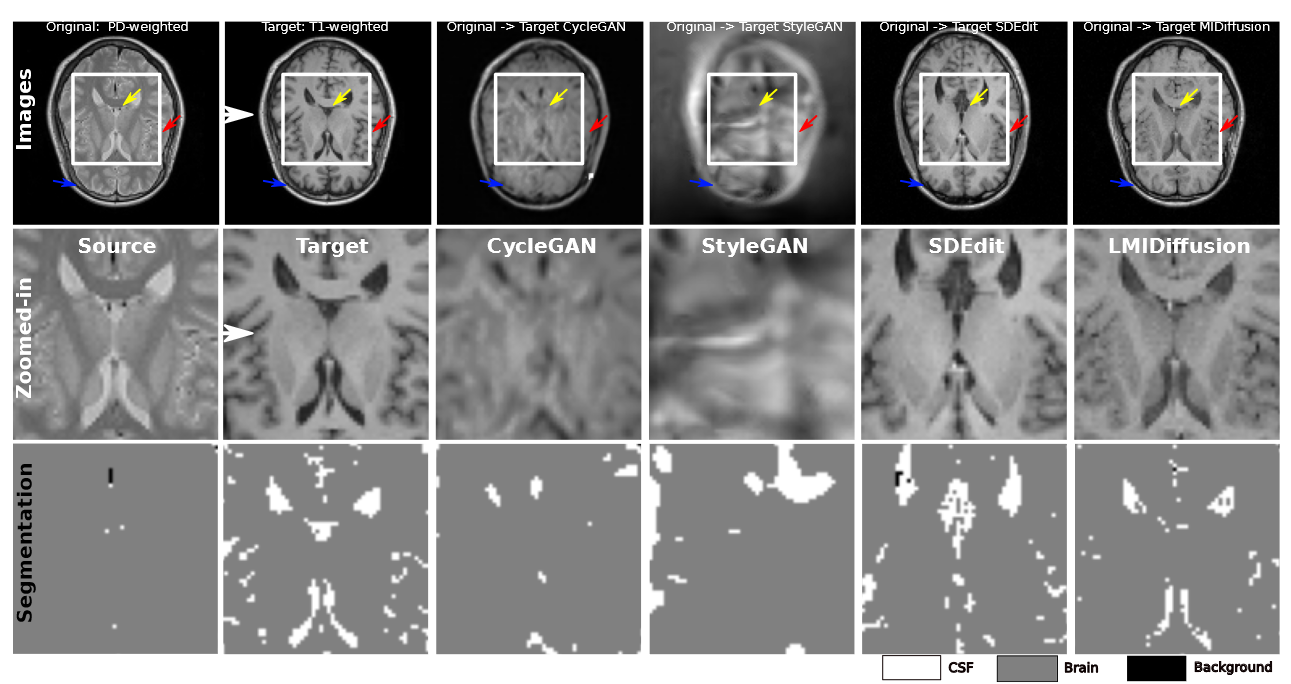
图2:对不同模型的翻译结果进行定性评估。前两行显示目标和原始模态图像,以及 ROI 的特写镜头,然后是 CycleGAN、StyleGAN、SDEdit 和 LMIDiffusion 的转换。随后的一行显示使用 3 个聚类 K-Means 方法进行分割的 ROI 中的二值化分割结果,该方法仅在目标模态上进行训练。
在表 1 中给出了基于不同模型计算的 Dice 分数、PSNR 和 SSIM 值。很明显,LMIDiffusion 的Dice 得分为 0.88 ± 0.05。紧随其后的是基于 CycleGAN 的方法,得分为 0.85 ± 0.07。SDEdit 技术表现出次优性能,Dice 得分为 0.82。相比之下,GAN反演方法(StyleGAN)的结果为0.66,强调了其在跨模态图像翻译方面的挑战。在翻译质量指标方面,LMIDiffusion 处于领先地位,PSNR 和 SSIM 值分别为 20.22 和 SSIM 为 0.69。CycleGAN 紧随其后,PSNR 为 18.88,SSIM 为 0.27,而 SDEdit 报告的 PSNR 为 15.96,SSIM 为 0.50。StyleGAN方法与其较低的Dice分数一致,PSNR最低,为10.15,SSIM为0.06,进一步证明了GAN反演方法在零样本图像转换任务中的局限性。

四、总结
本文提出了一种应用于跨模态图像分割的零样本跨模态图像平移新方法。对于零样本学习的挑战,本文的方法在翻译质量和零样本分割性能方面优于现有的基于 GAN 和基于扩散的方法。结果表明,所提出的LMI引导扩散是一种很有前途的基于零样本学习方式的跨模态图像平移分割方法。通过引入单样本或少样本学习来改进扩散引导的LMI计算,可以潜在地提高模型的性能。