

一、介绍
多模态成像是评估人体解剖信息的关键。通过各种方式捕获多模态的组织信息有助于提高下游成像任务的性能和诊断准确性。但实际场景中,多模态图像是容易造成缺失的,因此需要医学图像翻译任务来解决这一问题,旨在已知源模态的指导下合成缺失的目标模态。鉴于不同模态的组织信息存在非线性变化,这种恢复是一个条件不佳的问题。我们可以通过基于深度学习的方法结合非线性数据作为先验来改善问题条件,从而提供了性能的飞跃。
基于深度学习的方法需要涉及网络模型,这些模型经过训练以捕获给定源图像的目标条件分布的先验。生成对抗网络(GAN)模型在图像合成方面的特殊真实性而被广泛用于翻译任务。它拥有捕获目标分布信息的判别器,同时判别器还引导生成器实现从源模态到目标模态的单次映射。基于这种对抗机制,基于GAN的翻译任务在许多工作中报告了SOTA的结果,例如跨MR扫描仪的合成,多对比度MR合成和CT合成。
尽管GAN模型被证明很强大,但它通过生成器和判别器之间的相互作用间接捕获有关目标模态的分布信息。因此捕获到的是目标分布的隐式表征,这种隐式表征容易产生学习偏差,包括判别器的过早收敛和模式崩溃,导致合成图像的质量和多样性较差。最近的计算机视觉研究已将扩散过程作为GAN的有前途的替代方案,以提高生成建模任务中的样本多样性。然而,扩散方法在医学图像翻译中的潜力在很大程度上仍未得到探索,部分原因是常规扩散模型中图像采样的计算负担很大。
在这里,作者提出了一种用于医学图像合成的新型对抗扩散模型 SynDiff,以执行高效且高保真的模态转换(图1)。

图1:a) 规则扩散模型在实际图像样本(x0)和各向同性高斯噪声(xT)之间以数百个时间步长逐渐变换。每个正向步骤都会向当前图像样本添加噪声,而每个反向步骤都会对图像样本进行降噪。神经网络用于反向扩散步骤中的去噪。b)所提出的对抗扩散模型在几个步骤中执行快速转换。每个前向步进都会增加更大的噪声量,与较大的步长相对应。adversarial projector 用于提高反向扩散过程中的精度。扩散生成器合成去噪图像样本,而判别器区分去噪图像的实际样本和合成样本。
二、SynDiff
给定源图像,SynDiff利用快速扩散来生成目标图像。并且SynDiff采用 adversarial projector,可在大步长内进行精确的反向采样。引入了一种周期一致性架构,以便在源-目标图像的未配对数据集上进行训练(图2)。

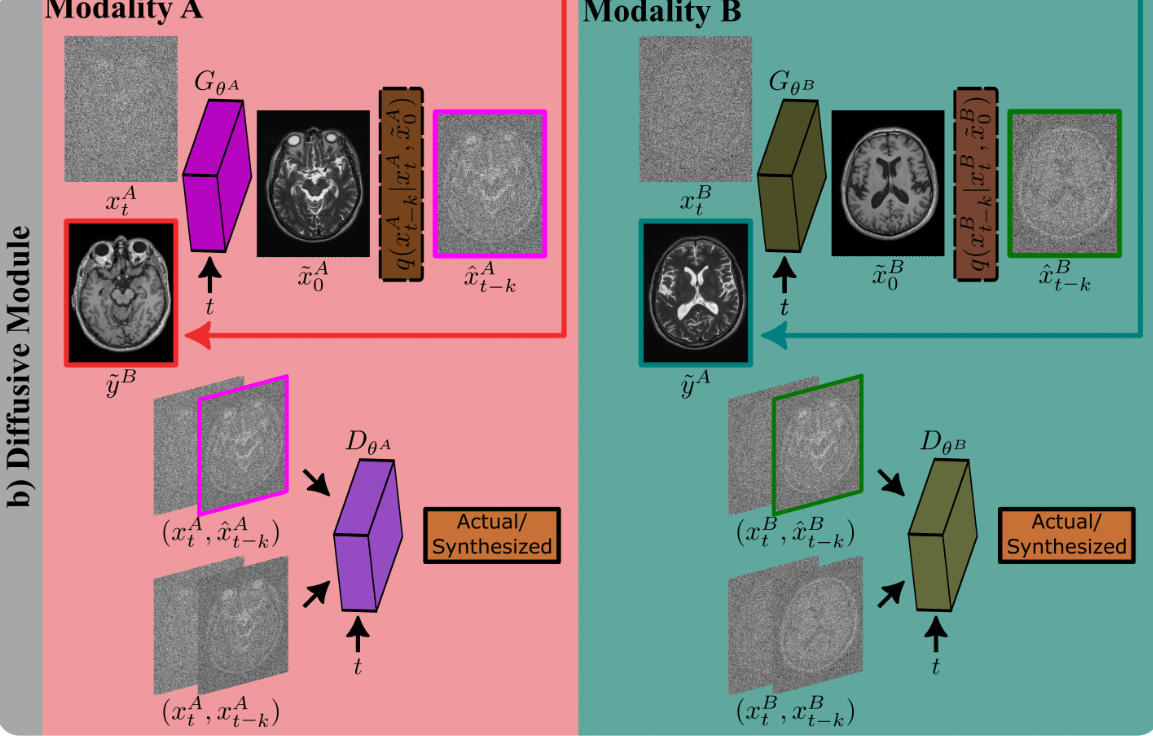
图2:对于无监督学习,SynDiff利用周期一致的架构,在两种模态(A, B)之间进行双边转换。为了合成模态A的目标图像\(\textcolor{blue}{x^A_0}\),图1中的扩散发生器需要来自模态B的源图像\(\textcolor{blue}{y^B}\)的解剖学指导,以实现相同的解剖结构,这在未配对训练集中不可用,因此,SynDiff使用非扩散生成器来估计配对的源图像\(\textcolor{blue}{\tilde{y}^B}\)以用于训练目的。a)非扩散模块(Non-Diffusive Module)由两个生成器-判别器对组成,用于生成\(\textcolor{blue}{x^A_0 \rightarrow \tilde{y}^B}\)(红色)和\(\textcolor{blue}{x^B_0 \rightarrow \tilde{y}^A}\)(蓝色)的初始平移估计值。b)然后将这些初始平移估计值\(\textcolor{blue}{\tilde{y}^{A,B}}\)用作扩散模块中的指导源对比度图像。为了实现周期一致性,扩散模块还包括两个生成器-判别器对,以生成\(\textcolor{blue}{(x^A_t, \tilde{y}^B, T) \rightarrow \hat{x}^A_{t-k}}\)(品红色)和\(\textcolor{blue}{(x^B_t, \tilde{y}^A, T) \rightarrow \hat{x}^B_{t-k}}\)(绿色)的去噪图像估计。
SynDiff的工作原理详述如下:
1)对抗扩散过程:扩散模型规定了相对较大的 T,使得步长足够小,可以满足方程(\(\textcolor{blue}{q(x_{t-1}|x_t):=\mathcal{N}(x_{t-1};\mu(x_t,t),\Sigma(x_t,t))}\))的正态性假设,但这限制了图像生成的效率。在这里,作者建议通过以下正向过程进行快速扩散:
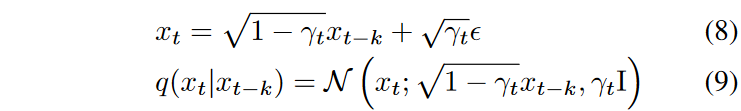
其中 \(\textcolor{blue}{k \gg 1}\) 是步长。噪声方差 \(\textcolor{blue}{γ_t}\) 设置为
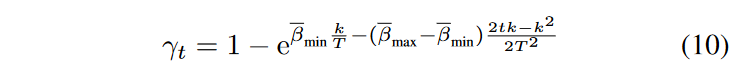
\(\textcolor{blue}{\bar{β}_{min}}\)和 \(\textcolor{blue}{\bar{β}_{max}}\) 表示指数 schedule中噪声方差的上限和下限。
在医学图像翻译过程中,源图像(y)的引导是可利用的,因此提出了一种有条件的逆向扩散过程。但需注意,对于\(\textcolor{blue}{k \gg 1}\), \(\textcolor{blue}{q(x_{t-k}|x_t,y)}\)没有闭式表达式,用于计算方程4的正态性假设失效:
在这里,作者介绍了一种新的对抗性投影仪,用于捕捉条件扩散模型中大k的复合转移概率\(\textcolor{blue}{q(x_{t-k}|x_t,y)}\)。在SynDiff中,条件生成器\(\textcolor{blue}{G_\theta(x_t,y,t)}\)在每个反向步骤中执行逐步去噪,以估计\(\textcolor{blue}{\hat{x}_{t-k} \sim p_\theta(x_{t-k}|x_t,y)}\)。判别器\(\textcolor{blue}{D_\theta(\{\hat{x}_{t-k}\quad or \quad x_{t-k}\},x_t,t)}\)区分从估计和真实去噪分布(\(\textcolor{blue}{p_\theta(x_{t-k}|x_t,y) \quad vs.\quad q(x_{t-k}|x_t,y)}\))。\(\textcolor{blue}{G_\theta}\) 是通过非饱和对抗性损失进行训练的:
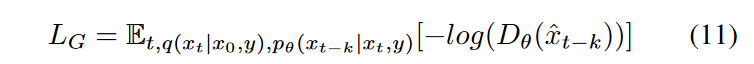
其中 \(\textcolor{blue}{t ∼ \mathcal{U}({0,k,...,T})}\),为简洁起见,判别器参数被缩写。\(\textcolor{blue}{D_\theta}\)也用梯度惩罚的非饱和对抗性损失进行训练:
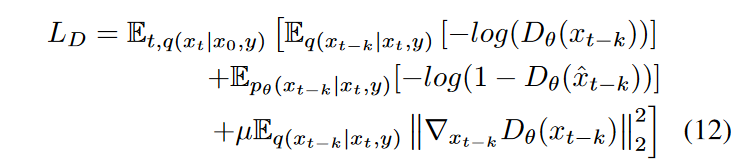
其中 \(\textcolor{blue}{μ}\) 是梯度惩罚的权重。
方程11-12 需要从未知分布\(\textcolor{blue}{q(x_{t-k}|x_t,y)}\)中采样。然而,贝叶斯规则可以用来用前向转换概率来表示它:
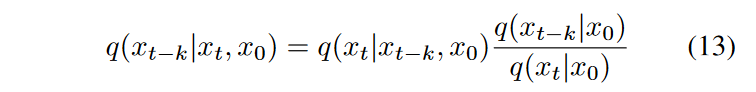
使用方程 8,可以证明 \(\textcolor{blue}{q(x_{t−k}|x_t,x_0) = N(x_{t−k}; \bar{μ}(x_t,x_0),\bar{γ}I)}\),参数如下:
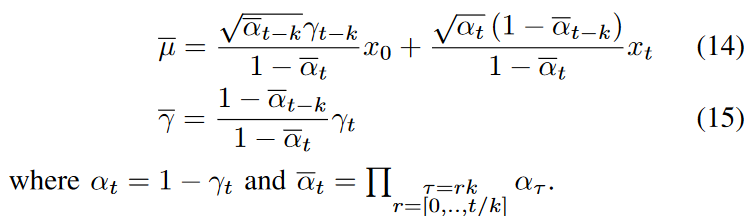
方程11-12 还需要从\(\textcolor{blue}{p_\theta(x_{t-k}|x_t,y)}\)中采样。确定性的样本是生成器输出,即 \(\textcolor{blue}{\hat{x}_{t−k} ∼ δ(x_{t−k} − G_θ(x_t,y,t))}\)。为了保持随机性,将生成器分布操作为:

其中 \(\textcolor{blue}{G^{[·]}_θ}\) 表示通过生成器的递归投影。方程13和16之间的主要区别是前者基于t = 0时的实际图像,而后者基于生成器输出的去噪图像。在多个反向扩散步骤的递归采样之后,最终的去噪图像将通过采样\(\textcolor{blue}{\hat{x}_0 ∼ p_θ(x_0|x_k,y) }\)获得。
2)循环一致架构:在源模态和目标模态的未配对数据集上进行训练的能力提高了学习综合模型的灵活性。但请注意,方程 16 中扩散发生器的实现需要同一主体内的成对源-目标图像。为了实现不配对训练,作者在 SynDiff 中引入了周期一致性,以在两种模式(A、B)之间进行双边转换。由于训练图像 \(\textcolor{blue}{x^{A,B}_0}\) 不匹配,于是首先使用两个参数为 \(\textcolor{blue}{\phi^{A,B}}\) 的非扩散生成器来获得初始平移估计值\(\textcolor{blue}{\tilde{y}^{A,B}}\) :

然后,这些初始估计值用于在 SynDiff 中使用参数 \(\textcolor{blue}{θ^{A,B}}\)调节两个扩散生成器:

其中\(\textcolor{blue}{\tilde{x}^{A,B} _0}\)是去噪图像的确定性估计值。对于每种模态,相应的\(\textcolor{blue}{\tilde{x}_0}\)可用于从\(\textcolor{blue}{p_\theta(x_{t-k}|x_t,y)}\)中采样,如方程 16 所述。为了表示循环一致性损失,可以从扩散发生器采样的\(\textcolor{blue}{\hat{x}_0}\) 与 \(\textcolor{blue}{x_0}\) 进行比较。同时,需要通过非扩散生成器进行双边预测:
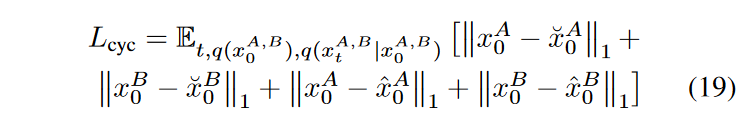
方程 19 中的前两项表示由非扩散发生器形成的循环;它们对于产生源图像的合理估计以调节扩散发生器至关重要,尤其是在训练的初始阶段。相反,最后两项表示由扩散生成器形成的循环;他们强制执行 SynDiff 以更好地保留源对比度中的解剖结构。
为了防止非扩散循环中的恒等映射,非扩散生成器也采用了类似于方程11的非饱和对抗损失,包括相应的判别器:\(\textcolor{blue}{D^A_\phi(.)}\),\(\textcolor{blue}{D^B_\phi(.)}\),其中\(\textcolor{blue}{D^A_\phi}\)接收 \(\textcolor{blue}{x_0^A}\) 或者 \(\textcolor{blue}{y^A}\)作为输入,\(\textcolor{blue}{D^B_\phi}\)接收 \(\textcolor{blue}{x_0^B}\) 或者 \(\textcolor{blue}{y^B}\)作为输入。然后,训练生成器的总损失如下:
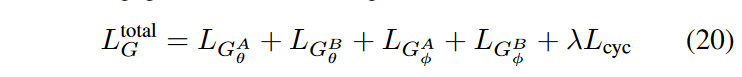
其中 \(\textcolor{blue}{λ}\) 是循环一致性损失的正则化权重。同时,非扩散判别器基于类似于方程 12 的非饱和损耗进行训练,尽管省略了梯度惩罚。然后,总体判别器损失为:

三、实验设置
数据集:SynDiff在多对比度脑部MRI数据(IXI)和多模态盆腔MRI-CT数据集上进行图像合成。每个分析的数据集都是三向拆分的,以创建没有主题重叠的训练、验证和测试集。
1)IXI Dataset: 40 名健康受试者的 T1 和 T2 加权图像,(训练、验证、测试)分为 (25、5、10) 名受试者。在每个受试者中,选择了 100 个带有脑组织的轴向横截面。对于 T1 加权扫描,TE = 4.603ms,TR = 9.813ms,空间分辨率 = 0.94×0.94×1.2\(mm^3\)。对于 T2 加权扫描,TE = 100ms,TR = 8178.34ms,空间分辨率 = 0.94×0.94×1.2\(mm^3\)。
2)MRI-CT Dataset:15 名受试者的 MR 和 CT 图像,(训练、验证、测试)分为 (9,2,4) 名受试者。在每个受试者中,选择了 90 个轴向横截面。对于 T2 加权 MR 扫描,TE = 97ms,TR = 6000-6600ms,空间分辨率 = 0.875×0.875×2.5\(mm^3\),或 TE = 91-102ms,TR = 12000-16000ms,空间分辨率 = 0.875-1.1×0.875-1.1×2.5\(mm^3\)。对于 CT 扫描,规定空间分辨率 = 0.1×0.1×3\(mm^3\),内核 = B30f,或空间分辨率 = 0.1×0.1×2\(mm^3\),内核 = FC17。
对比方法:针对几种最先进的扩散和 GAN 模型与Syndiff进行对比,所有这些都是为源模态和目标模态之间的不成对翻译而实现的。对于每个模型,执行超参数选择以最大限度地提高验证集的性能。选择的参数包括训练周期数、优化器的学习率、所有模型的损失项权重以及扩散模型中的时间步长数。
1)SynDiff:SynDiff 使用以下交叉验证的超参数实现:50 个 epoch,0.0001 学习率,\(λ=0.5\) 相对权重用于周期一致性损失,\(μ=0.5\) 相对权重用于梯度惩罚,T = 1000,步长为 k=250,总共 \(\frac{T}{k}=4\) 个扩散步骤。噪声方差表的下限和上限分别为\(β_{min}=0.1\),\(β_{max}=20\)。
2)DDPM:架构函数和损耗函数是从IDDPM中采用的。在源对比图像的指导下设计了条件扩散过程,并基于与 SynDiff 相同的策略实现了周期一致性变体。交叉验证的超参数为 50 个周期,学习率为 0.0001,周期一致性损失的相对权重 \(λ=1\),T =1000,步长为 k=1,总共有 1000 个扩散步骤。使用\(β_{min}=0.1\),\(β_{max}=20\)的噪声时间表。
3)cGAN:考虑了一种用于无监督医学图像平移的周期一致GAN模型。cGAN由两个具有ResNet主干的生成器和两个具有级联卷积块的鉴别器组成,然后进行实例归一化。交叉验证的超参数为 100 个周期,前 50 个周期的学习率常数为 0.0002,之后线性衰减为 0,周期一致性损失的 \(λ_{cycle}=100\) 相对权重。
4)UNIT:考虑了一种无监督GAN模型,用于从未配对的源-目标图像中学习。UNIT 由两个鉴别器和两个转换器组成,在循环设置中有一个 ResNet 主干。转换器包含具有共享潜在空间的并行连接域图像编码器和发生器。鉴别器包含一连串的下采样卷积块。交叉验证的超参数分别为 100 个周期、0.0001 个学习率、\(λ_r = 10\)、\(λ_{adv} = 1\)、\(λ_{cycle} = 10\) 个相对权重,用于重建、对抗性和周期一致性损失。
架构细节:对于周期一致的学习,SynDiff 使用扩散和非扩散模块。非扩散模块由两个生成器-鉴别器对组成,用于在未配对数据集上生成初始平移估计值。同时,扩散模块还包括两个发生器-鉴别器对,每个模态一个。在训练期间,同时使用所有四个生成器鉴别器对。在推理过程中,仅使用一个扩散发生器,负责所需的源到目标模态转换。下面提供了扩散和非扩散模块的架构细节:
1)非扩散模块:非扩散模块中的每个生成器都接收一个目标模态图像作为输入,并生成同一解剖结构的相应源模态图像的估计值(这在训练集中不可用)。这种对源模态的初步估计后来被用作扩散发生器的解剖学指导。采用具有三个编码块、六个残差块和三个解码块的ResNet骨干网。同时,非扩散模块中的判别器用于防止在生成器的周期一致性训练期间进行身份映射。每个鉴别器接收作为输入的实际和合成源模态图像,在受试者之间未配对。然后,它输出关于图像样本是实际的还是合成的决策日志。采用了具有六个下采样块的卷积主干。每个块包含两个卷积层,并将特征图分辨率减半。
2)扩散模块:扩散模块中的每个发生器接收时间t的噪声图像样本及其时间索引以及指导源模态图像作为输入,并在时间t − k输出目标模态的去噪图像样本。采用UNet骨干网,包括6个下采样和6个上采样块。每个下采样块使用两个残差子块,然后使用卷积层将特征图分辨率减半,而通道维数每隔一个块增加一倍。通过两层多层感知器(MLP)投射32维正弦位置编码,计算每个时间索引的时间嵌入。时态嵌入被添加到残差子块中的特征图中。每个上采样块使用两个残差子块,后跟一个卷积层,使特征图分辨率加倍,而通道维数每隔一个块减半。同时,每个判别器接收时间\(t−k\)处去噪图像的实际样本或合成样本、时间索引和时间t处的噪声图像样本作为输入;它输出关于图像样本是实际的还是合成的决策日志。采用了具有六个下采样块的卷积主干。每个块包含两个卷积层,并将特征图分辨率减半。采用了与扩散发生器相同的时间嵌入策略。
建模过程:所有模型都是使用 PyTorch 框架在 Python 中实现的。使用 \(β_1 = 0.5\)、\(β_2 = 0.9\) 的 Adam 优化器训练模型。模型在配备 Nvidia RTX 3090 GPU 的工作站上执行。在每个数据集中的测试集上评估模型性能。通过峰值信噪比 (PSNR)、结构相似性指数 (SSIM) 指标评估性能。在进行度量计算之前,所有图像都按其平均值进行归一化。通过非参数 Wilcoxon 符号秩检验评估竞争方法之间性能差异的显着性 (p<0.05)。
四、实验结果
1.多对比 MRI 翻译
这一节演示了 SynDiff 在单独的 MRI 造影剂之间进行无监督翻译。将 SynDiff 与最先进的扩散 (DDPM) 和 GAN 模型(cGAN、UNIT)进行了比较。在 IXI 数据集中对 T1 → T2 和 T2 → T1 合成任务的脑图像进行了实验。竞争方法的合成性能定量指标列于表I中。
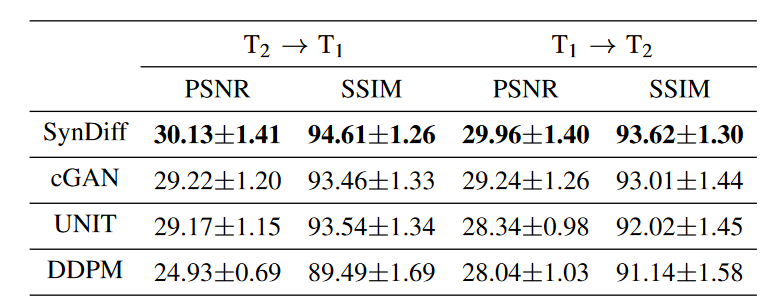
表 1:在 IXI 数据集中→ T1 和 T1 → T2 合成任务的性能。PSNR (dB) 和 SSIM (%) 在整个测试集中被列为均值±标准差。粗体标记每个任务中表现最好的模型。
SynDiff 在两项任务中都具有最高的性能 (p<0.05)。平均而言,SynDiff 的性能比 DDPM 高出 3.56dB PSNR 和 3.80% SSIM,GAN 型号的性能比 DDPM 高出 1.05dB PSNR 和 1.11% SSIM (p<0.05)。图 3 中显示了 T2 → T1 的代表性图像,图 4 中显示了 T1 → T2 的代表性图像。GAN模型显示残余噪声和伪影,以及组织边界附近的不准确描述。DDPM显示出一定程度的空间平滑和残余伪影。与基线相比,SynDiff合成的目标图像噪点和伪影明显降低,并且在组织描述方面实现了高度的解剖学准确性,特别是在CT图像中诊断相关区域附近。

图 3:SynDiff 在 IXI 数据集上进行了代表性的 T2 → T1 合成任务的演示。来自竞争方法的合成图像与源图像和真实目标图像(参考)一起显示。与扩散和GAN基线相比,SynDiff实现了更低的噪声和伪影水平,以及更准确地描述组织结构。

图 4:SynDiff 在 IXI 数据集上进行了具有代表性的 T1 → T2 合成任务的演示。来自竞争方法的合成图像与源图像和真实目标图像(参考)一起显示。与扩散和GAN基线相比,SynDiff实现了更低的噪声和伪影水平,以及更准确地描述组织结构。
2.跨模态合成
然后,这一部分演示了SynDiff在不同成像模式之间的无监督翻译。将 SynDiff 与扩散 (DDPM) 和 GAN 模型(cGAN、UNIT)进行比较。在骨盆数据集上进行 MRI → CT 合成任务的实验。竞争方法的合成性能定量指标列于表二。

表 2:多模态盆腔数据集中 T2 加权 MRI → CT 合成任务的性能。PSNR (dB) 和 SSIM (%) 在整个测试集中被列为均值±标准差。粗体标记性能最佳的模型。
总体而言,SynDiff 的性能最高,PSNR 比 DDPM 高 2.2dB,SSIM 高 4.7%,PSNR 比 GAN 型号高 1.28dB 和 SSIM 高 2.29%(p<0.05)。MRI → CT 的代表性图像如图 5 所示。与基线方法相比,SynDiff 合成的目标图像噪声和伪影更低,组织描述更准确。

图 5:在 MRI → CT 合成任务的多模态盆腔数据集上演示了 SynDiff。来自竞争方法的合成图像与源图像和真实目标图像(参考)一起显示。与扩散和GAN基线相比,SynDiff实现了更低的噪声和伪影水平,以及更准确地描述组织结构。
五、总结
SynDiff是第一个用于医学图像合成的对抗性扩散模型,也是第一个用于非配对医学图像翻译的周期一致性扩散模型。我们展示了 SynDiff 在多对比度 MRI 和 MRI-CT 任务中缺失模态合成。在定性和定量性能方面,SynDiff在无监督合成任务中优于最先进的GAN模型。
常规扩散模型将图像生成视为一个渐进的过程,从随机噪声开始,并在数千个时间步长内重复去噪,导致采样效率低下。在这项研究中,作者建议通过利用具有大步长的快速扩散过程来加速两个数量级的采样。连续样本之间的步长增加会导致复杂的反向跃迁概率,偏离扩散模型中通常使用的正态性假设。为了捕捉这种复杂的分布,并引入了一个对抗性投影仪来执行精确的反向扩散采样。
在这些情况下,SynDiff可以通过替换空间配准图像上的像素损失来代替周期一致性损失来执行配对训练。通过基于配对和未配对数据的组合,或收集欠采样的源和目标模态采集,扩大训练数据集的大小,性能改进也可能是可行的。本文主要演示了 SynDiff 用于两种模式之间的一对一翻译任务。单一源模式可能不包含足够的信息来可靠地恢复目标图像。当多模态协议可用时,可以进行多对一翻译以提高图像翻译的可靠性。为此,可以修改SynDiff,以包含多个源模态作为其生成器的调节输入。SynDiff 中执行反向扩散步骤以进行去噪的发生器基于卷积主干。最近的成像研究报告称,具有注意力机制的转换器架构在合成过程中及之后提高了对医学图像中远程环境的敏感性。情境表示对渐进式去噪的强度和重要性仍有待证明。尽管如此,注意机制可能有助于增强SynDiff对非典型解剖结构的泛化性能。