

一、引言
由于多种因素,例如最先进的计算硬件,更重要的是医学数据集(开放的和内部的)的可用性,医学领域的生成模型取得了标志性的进步。因此,过去几年人们提出了针对医学图像合成、恢复、加速和许多其他任务的有前途的解决方案。
目前的生成纵向医学图像主要是以下两个任务:1)生成纵向脑图像,它获取源脑图像并根据当前的实际年龄生成新的图像; 2)生成多帧心脏图像,通常采用心动周期的起始帧(即舒张末期或 ED 阶段)并生成周期的最终帧(即收缩末期)或 ES 阶段)。

图 1 显示了这些任务的示例。生成对抗网络 (GAN) 在过去几年中已成为这些任务的事实上的标准,但扩散模型的最新进展已经显示出有希望的结果。例如,潜在扩散模型利用图像的潜在嵌入作为扩散模型的输入来提高计算效率,已被用于合成高质量的3D脑部MRI。类似地,将扩散模型与变形图像配准模型相结合,即VoxelMorph,以合成心脏MRI的收缩末期帧。然而,这些工作大多数依赖于单个图像的输入来生成其纵向图像。即使纵向样本可用,这些方法也常常忽略医学领域的顺序依赖性。
序列感知(Sequence-Aware)深度生成模型被定义为是一类可以学习纵向输入数据的顺序或时间依赖性的生成模型。序列被定义为有序且带有时间戳的集合,序列感知生成模型从图像序列中获取输入并输出生成的图像。尽管已经研究了这种视频数据集的生成模型,通常将帧序列作为输入并学习它们的时间依赖性,但现有的解决方案对于纵向医学数据生成任务并不可行。因为视频数据集很少存在医学领域中非常常见的问题,例如 🔸纵向数据稀缺,🔸帧或数据丢失,🔸高维度,以及 🔸不同的序列长度。
为此,作者提出了一种用于纵向医学图像生成的新颖的生成模型,该模型可以学习给定医学图像序列的时间依赖性。作者提出的方法被称为序列感知扩散模型(SADM)。具体来说,在训练期间,即使数据丢失的情况下,SADM 也能够根据顺序输入学习估计给定标记纵向位置的注意力表示。在推理时,使用自回归采样方案来有效生成新图像。作者他们对纵向 3D 医学图像进行的广泛实验证明了 SADM 与基线和替代方法相比的有效性。
二、SADM:序列感知扩散模型
具体来说, SADM 使用基于Transformer的注意力模块来调节扩散模型。注意力模块是视频Vit Transformer(ViViT)的 4D 推广,专门用于生成扩散模型的条件信号。在本节中,将简要解释SADM的问题设置和细节。 SADM 的概述如图 2 所示。

假设一段时间长度为L的纵向3D图像序列为\(\textcolor{blue}{X \sim p(X) \in R^{L\times W\times H\times D}}\)。其中将\(\textcolor{blur}{X}\)划分为条件图像\(\textcolor{blue}{X^C \in R^{n_C\times W\times H\times D}}\)、缺失图像\(\textcolor{blue}{X^M \in R^{n_M\times W\times H\times D}}\)和未来图像\(\textcolor{blue}{X^F \in R^{n_F\times W\times H\times D}}\),其中\(\textcolor{blue}{C=\{c_1,...,c_{n_C}\}}\),\(\textcolor{blue}{\mathcal{M}=\{m_1,...,m_{n_\mathcal{M}}\}}\),\(\textcolor{blue}{\mathcal{F}=\{f_1,...,f_{n_\mathcal{F}}\}}\)是用于张量的标量索引序列,并且它们是有序、带时间戳且不相交的集合,则有\(\textcolor{blue}{C\cap\mathcal{M} =\mathcal{M}\cap\mathcal{F}=\mathcal{F}\cap C=\emptyset}\),\(\textcolor{blue}{C\cup\mathcal{M} =\mathcal{M}\cup\mathcal{F}=\mathcal{F}\cup C={1,...,L}}\),并且\(\textcolor{blue}{nC+n\mathcal{M}+n\mathcal{F}=L}\)。我们假设\(\textcolor{blue}{\mathcal{F}}\)的索引始终位于\(\textcolor{blue}{\mathcal{C}}\)和\(\textcolor{blue}{\mathcal{M}}\)的未来,即对于所有\(\textcolor{blue}{c\in C,m\in\mathcal{M},f\in\mathcal{F},c<f且m<f}\)。此外,我们假设序列的第一张图像已知,即\(\textcolor{blue}{c_1=1}\)。目标是最大化后验\(\textcolor{blue}{p(X^{\mathcal{M}}|X^{\mathcal{C}})}\)和\(\textcolor{blue}{p(X^{\mathcal{F}}|X^{\mathcal{C}})}\)。即在给定序列的情况下合成缺失图像和未来图像。
1.注意力模块\(\mathcal{A}_\theta\)
本文提出了一种基于 Transformer 的注意力模块,用于为扩散模型生成条件信号。该注意力模块将指导调节图像\(\textcolor{blue}{X^{\mathcal{C}}}\)的哪些帧将有利于生成未来或丢失的帧。我们的注意力模块的概述如图 3 所示。

1️⃣Token Embedding将图像或视频嵌入到token中的一种常见方法是以不重叠的步幅在输入上运行融合窗口。给定\(\textcolor{blue}{X \in R^{L\times W\times H\times D}}\),我们在图像上运行尺寸为\(\textcolor{blue}{R^{l×w×h×d×dim}}\)的非重叠线性投影窗口,即 4D 卷积。得到的未展平令牌\(\textcolor{blue}{h}\)的形状为\(\textcolor{blue}{R^{[\frac{L}{l}]×[\frac{W}{w}]×[\frac{H}{h}]×[\frac{D}{d}]×dim}}\)。然而,当我们处理可能包含丢失帧的纵向医学图像时,通过时间轴融合是不可行的。因此,我们在本文中进行的实验中设置\(\textcolor{blue}{l=1}\)。此外,纵向图像的时间分辨率与其空间分辨率相比通常非常低,因此设置\(\textcolor{blue}{l=1}\)只会轻微影响计算效率。
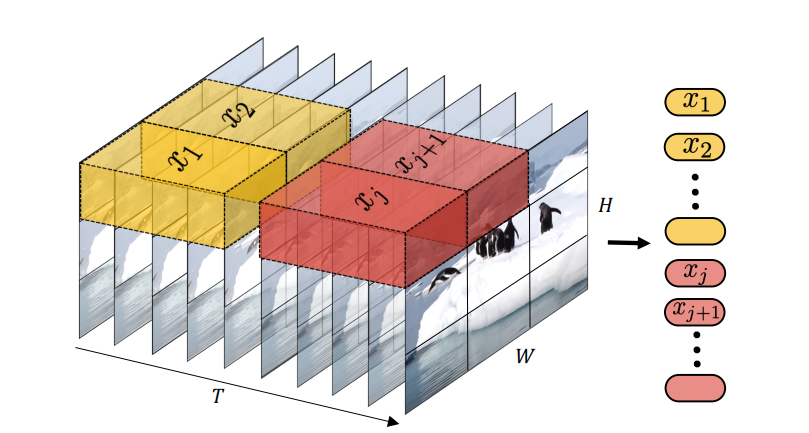
2️⃣Temproal Encoder受factorized transformers的启发,作者将注意力模块分解为时间编码器和空间解码器,它们可以受益于高计算效率的远程时空注意力。时间编码器计算同一空间索引中的所有token之间的时间维度的自注意力。具体来说,它采用未展平的token并将其重塑为\(\textcolor{blue}{h_{tmp} \in R^{[\frac{W}{w}]\cdot[\frac{H}{h}]\cdot[\frac{D}{d}]×L×dim}}\),其中主要维度是批量维度。然后,它沿时间维度计算自注意力,MLP 将 token 的维度减少 \(2^3\) 倍,并将其重塑为\(\textcolor{blue}{h_{tmp}^l \in R^{[\frac{W}{2^lw}]\cdot[\frac{H}{2^lh}]\cdot[\frac{D}{2^ld}]×L×dim}}\)对于每个temporal transformer block \(\textcolor{blue}{l}\)。
3️⃣Spatial Decoder将时间编码器的输出重塑为\(\textcolor{blue}{h_{spt}^l \in R^{[\frac{W}{2^lw}]\cdot[\frac{H}{2^lh}]\cdot[\frac{D}{2^ld}]×L×dim}}\),空间解码器计算同一时间索引中所有token之间的空间维度的自注意力。然后,对每个空间维度进行2倍上采样,得到\(\textcolor{blue}{h_{spt}^l \in R^{L×[\frac{W}{2^{N-l}w}]\cdot[\frac{H}{2^{N-l}h}]\cdot[\frac{D}{2^{N-l}d}]×dim}}\)。最后,我们将最后一块的输出展平并重塑为\(\textcolor{blue}{R^{[\frac{W}{w}]\cdot[\frac{H}{h}]\cdot[\frac{D}{d}]×L×dim}}\),并执行上采样和3D卷积运算以获得调节信号\(\textcolor{blue}{c \in R^{W\times H\times D}}\)。
由于 Transformer 可以mask token 的特定索引,因此即使纵向图像中存在丢失帧,我们也可以进行训练和推断。然而,我们发现使用零张量来处理具有非零位置编码的丢失帧比屏蔽丢失帧效果更好。
2.条件扩散模型
本文引入无分类器指导作为训练和推理所使用的条件扩散模型:
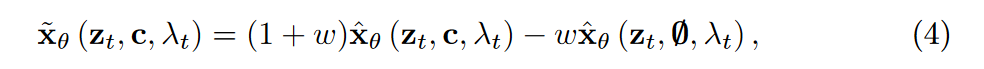
1️⃣训练SADM:扩散模型的输入是从未观察到的索引\(\textcolor{blue}{\mathcal{M}∪\mathcal{F}}\)中随机选择的目标图像以及来自先前索引的条件信号,即分别为\(\textcolor{blue}{x^i ∈ R^{W ×H×D}}\)和 \(\textcolor{blue}{c = \mathcal{A}({x^1, .. ., x^{i−1}})}\)。注意力模块和条件扩散模型可以单独预训练并一起微调,或者使用中扩散模型定义的损失项从头开始进行端到端训练。注意力模块可以通过最小化目标图像和调节信号c之间的\(l_2\)损失来预训练,扩散模型可以用零或随机值张量作为调节信号来预训练。然而,作者发现从头开始端到端的训练效果更好。SADM训练流程在算法 1 中定义。

2️⃣自回归采样:SADM 在给定先前图像的条件信号的情况下对下一帧图像 \(\textcolor{blue}{x^i}\)进行采样,即\(\textcolor{blue}{c^{i-1} = \mathcal{A}_\theta({x^1, .. ., x^{i−1}})}\)。然而,现实世界的数据通常缺少数据或每个受试者只有一张图像。因此,作者使用自回归采样方案,通过自回归合成图像来估算缺失图像。这种自回归采样方案已被证明可以提高扩散模型的生成性能。算法 2 显示了自回归采样方案的概述。

三、实验
作者在一个公共 3D 纵向心脏 MRI 数据集和一个模拟 3D 纵向脑 MRI 数据集上展示SADM 在医学图像生成中的有效性。我们将我们的工作与基于 GAN 的和基于扩散的基线进行定量和定性比较。最后,提出了对输入序列的各种设置的模型组件的消融研究。
1.数据集和实现
1️⃣心脏数据集(ACDC):心脏图像生成的常见任务是在给定周期的起始帧(即舒张末期或 ED)的情况下合成心动周期的最终帧(即收缩末期或 ES)。 ACDC 数据集由 100 名训练受试者和 50 名测试受试者的心脏 MRI 组成。我们采用从 ED 到 ES 的中间帧并将其大小调整为 \(\textcolor{blue}{X∈R^{12×128×128×32}}\),其中每个维度分别是帧的长度、宽度、高度和深度。对于训练,我们随机选择条件、缺失和未来指数。在推理过程中,作者尝试了三种设置:1)单图像,仅给出 ED 帧作为输入; 2)丢失数据,输入序列随机丢失帧; 3)完整序列,其中输入序列完全加载了调节图像。
2️⃣大脑数据集:模拟健康受试者的大脑随时间的变化对于了解人类衰老至关重要。纵向脑部 MRI 的内部合成分两个主要步骤进行,使用了 2,851 名年龄均匀分布的受试者扫描图像。我们首先将这些受试者扫描分为五个年龄组(18-30、31-45、46-60、61-74 和 75-97 岁),生成五个特定年龄的模板。然后我们使用基于 GAN 的配准模型将每个主题扫描分别配准到这五个模板,以模拟同一个人在不同年龄的纵向图像。模板和注册图像被分为十个交叉验证折叠。
2.与基线方法比较
选择两个最先进的基线模型进行比较:1)基于GAN的模型,它使用基于UNet的GAN模型在给定ED帧的情况下合成ES帧; 2)基于扩散的模型,它使用带有深度配准模型的扩散模型将ED帧配准到ES帧中。我们遵循相同的训练和推理流程来生成心脏和大脑图像,因此我们将仅解释心脏数据集的设置,如下所示。对于训练,SADM 使用 ED 和 ES 之间的中间帧,因此我们使用中间帧对及其 ES 帧来增强基线,以进行公平比较。由于这些模型只能执行单个图像合成(即 ED 到 ES 转换),因此我们仅使用 ED 帧作为输入来遵循它们的推理流程。
图 4 给出了定性比较,对于心脏图像生成,作者提出的 SADM 与基线方法相比显示了更好的血池(红框)描述。此外,血池周围的其他区域,例如心肌和心室,也以更高的保真度合成。对于大脑图像生成,SADM 合成的脑室区域(蓝框)比基线更清晰,并且皮质表面的合成更准确。

然后,通过计算目标与合成的ES帧之间的结构相似性指数(SSIM)、峰值信噪比(PSNR)和归一化均方根偏差(NRMSE)来进行定量比较。表 1 给出了定量比较结果。SADM模型在每个指标上都优于基于 GAN 的方法 3 ∼ 13%,同时略优于基于扩散的模型。值得注意的是,基于扩散的基线使用源图像和参考图像进行配准,而仅使用源图像作为输入。尽管SADM 能够处理单个图像,但它的设计目的是在处理一系列图像时表现更好,如下一节所示。

3.消融实验
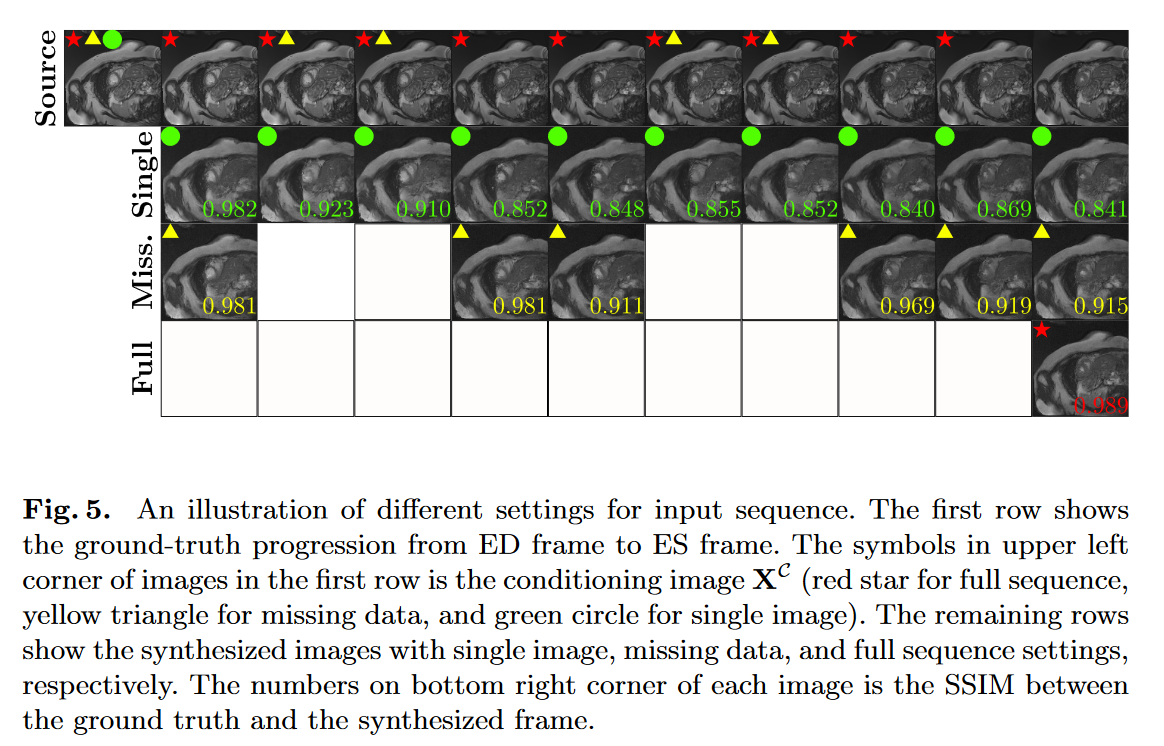
在本节中,设置不同输入序列,分别对模型的组件进行消融研究。输入序列不同的设置包括单图像、缺失数据和完整序列设置。如图 5 所示,与单个输入设置相比,使用完整序列和缺失数据设置的合成显示出更高的 SSIM。此外,正如通过调节帧附近帧的 SSIM 峰值所观察到的那样, SADM 正在学习输入序列中的哪些帧对于生成未来帧很重要,即顺序依赖性。
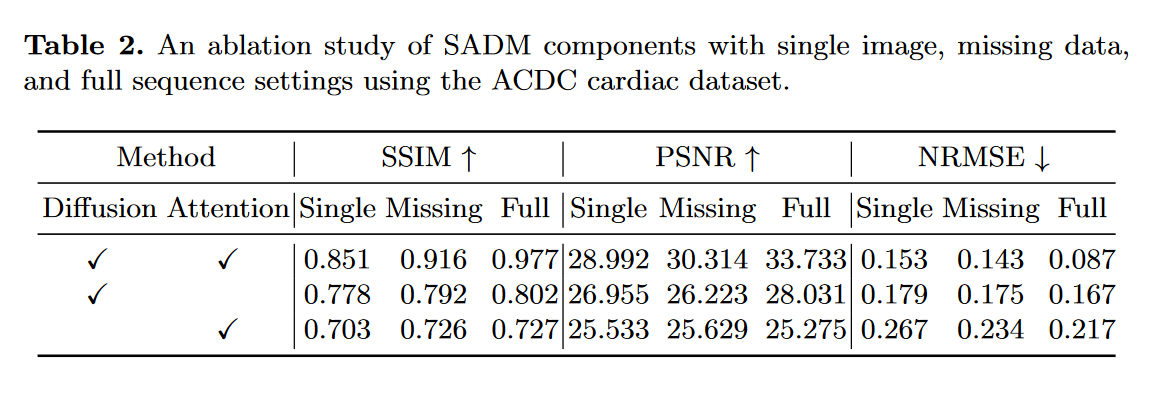
接下来,通过删除注意力模块或扩散模型来进行消融研究。仅扩散模型可以使用序列图像的原始像素值作为条件信号来训练,而仅注意模型可以通过最小化目标图像和变压器输出之间的\(l_2\)损失来训练。如表 2 所示,显然,仅有注意力模块的性能最差,因为transformers不是为图像生成而设计的(通常是由于展平操作 )。仅扩散模型的性能与基于 GAN 的基线相当,但它无法学习顺序依赖性,正如通过与单输入设置相比全序列设置中的最小性能提升所观察到的。
四、总结
作者提出了一种用于生成纵向医学图像的序列感知扩散模型。具体来说,我们的模型由一个基于变压器的注意力模块组成,该模块可以学习纵向数据输入的顺序或时间依赖性,并可以将其用在扩散模型当中,即可得到高保真医学图像的扩散模型。作者在纵向心脏和大脑 MRI 生成上测试了所提出的 SADM,并定量和定性地展示了最先进的性能。