

一、介绍
多模态图像对于医学图像分析的综合评价至关重要。为了识别临床上重要的生物标志物,通常需要具有补充信息的多模态 3D 图像。多模态成像作为一种方法来补偿个体成像技术的局限性并实现精确检查。医学图像分析,尤其是脑肿瘤的诊断,通常使用磁共振成像 (MRI) 进行,并且使用各种 MRI 技术,例如 3D T1-weighted、T1 constrast-enhanced weighted、T2 weighted和 FLAIR,因为不同的模式(T1、FLAIR 等)是不同的成像序列,可提供不同的对比度并提供有关出现在需要 3D 方法的多个连续切片上的脑肿瘤的补充信息(例如,水肿、增强肿瘤和坏死/非增强肿瘤)。
T1对急性出血敏感,可清晰显示造影剂,有助于识别血管结构、肿瘤和炎症区域。T2 突出显示水肿或炎症等状况。FLAIR 抑制脑脊液信号,可用于检测多发性硬化症病变等病理状况。
然而,在临床环境中,由于扫描成本、有限的扫描时间和安全考虑等因素,获得多种模式可能具有挑战性。因此,某些模式可能会缺失。这种缺乏模式可能会对诊断和治疗的质量产生不利影响。此外,当关键模态无法用于训练时,依赖多模态数据的深度学习模型也会遭受性能下降的影响。因此从某一模态转换到另一模态,甚至是多个模态在该领域就显得非常重要。
现有方法通常从一个或多个源(即一对一或多对一)生成给定的目标模态。为了从单一源模态生成多个目标,这些方法需要为每个目标建立单独的模型,从而导致复杂性增加。因此,需要一种能够使用 3D 医学成像执行图像转换而无需进行补丁裁剪(patch cropping)并允许从单一源模态生成灵活目标的模型。
在这里作者是认为在训练阶段使用补丁来训练模型,并在推理阶段使用滑动窗口方法生成结果。然而,这些方法可能会导致全局信息的丢失以及图像翻译性能的潜在下降。
近年来,扩散模型(DM)已成为一种强大的生成模型,具有高质量的生成能力,将自己定位为 GAN 的潜在替代品。扩散模型利用交叉注意力和灵活的调节来生成所需的图像。此外,潜在扩散模型(LDM)在图像的压缩潜在空间中定义了去噪任务,显着降低了计算成本,同时证明了以较低成本生成高质量图像的能力。 LDM 证明了其对 3D 医学图像的适用性,无需进行补丁裁剪。这一进步使得 LDM 能够应用于医学图像,甚至是其原生 3D 形式。
在本文中,作者提出了一种模型,它利用 LDM 的调节机制在 3D 医学图像中执行图像到图像的转换,而无需进行补丁裁剪来保持原始大小。此外,作者还提出的多可切换块(multiple-switchable block),称为 MS-SPADE 块,来实现从单一源模态生成多个目标模态。它根据风格动态地将源潜在变量转换为类似目标的潜在变量。通过利用 LDM 中的调节,我们可以更切实地生成所需的目标模态。该模型的流程如图所示。

图 1:基于潜在扩散模型的图像到图像转换过程的概述。ALDM模型利用所提出的 MS-SPADE 将潜在表示转换为目标潜在,并通过调节以所需的目标模态实现图像合成。
本文的主要贡献总结如下:
1️⃣提出了一种基于 LDM 的模型,可将 3D 医学图像中的单一源模态转换为各种目标模态(一对多)。
2️⃣引入了一个可切换块,它使用样式迁移将源潜在模型转移到类似目标的潜在模型,以增强图像到图像转换的性能。
3️⃣在 BraTS2021 和 IXI 数据集上验证了该方法,尽管该模型能够生成多种模式,但它在两个数据集上都表现出了最高的图像翻译性能。
二、方法
模型是通过两个阶段的过程训练图像到图像的转换,如图所示。
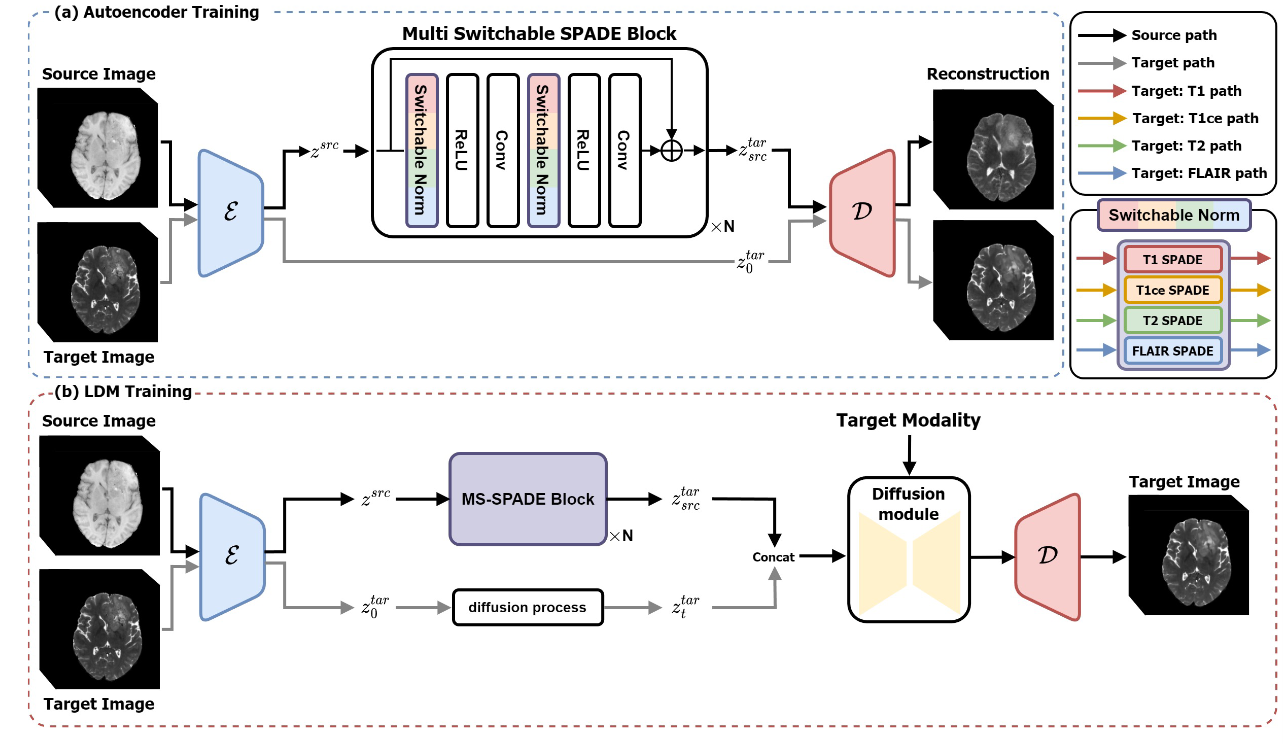
在第一阶段,训练一个自动编码器(VQVAE或者是VQGAN),将图像压缩为捕获其基本特征的潜在表示。潜在空间捕获原始图像的感知表示,通过矢量量化进行正则化,并允许通过条件归一化层进行风格转移。此外,还训练 SPADE 块将输入源图像潜在特征的风格转换为目标模态的风格。本文所提出的 MS-SPADE 块学习目标的风格参数并将该风格从源传输到目标。虽然仅使用 SPADE 模块就可以进行翻译,但真正的目标潜在变量与通过 SPADE 获得的潜在变量之间存在明显差异,因此我们将 SPADE 的输出记为类目标潜在变量(target-like latents)。
为了解决这种差异,作者利用 LDM 通过这两个潜在变量之间的去噪来减少差距,这是该论文模型中的关键思想。随后,我们结合target-like latents(来自 MS-SPADE)和噪声目标潜在变量(来自前向扩散),来训练 DM。该模型优先考虑通过首先调整其潜在风格,然后专注于生成特定于目标的潜在特征来最小化源图像的变化。
1.图像压缩
在这一部分除了使用自动编码器当作感知压缩模型,最值得关注的就是作者提出的MS-SPADE。潜在空间中的 MS-SPADE 块将source latents转换为target-like latents。可切换归一化如图 2 (a) 所示。我们的 SPADE 块在训练期间学习目标的平均值和标准差参数。因此,在推理过程中,它不需要目标作为输入,而是使用目标的样式参数进行规范化。
MS-SPADE 块根据目标模态执行不同的归一化,使变换后的潜在变量的变换遵循所需的分布。首先将\(\textcolor{blue}{h \in R^{N \times C \times H \times W \times D}}\)输入到 SPADE block当中。而SPADE 可以按如下方式应用:
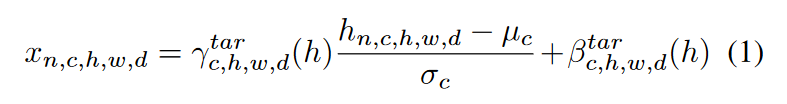
\(\textcolor{blue}{μ_c}\) 和 \(\textcolor{blue}{σ_c}\) 是通道 \(\textcolor{blue}{c}\) 中潜在特征的平均值和标准差,\(\textcolor{blue}{γ^{tar}_{c,h,w,d}}\)和\(\textcolor{blue}{β^{tar}_{c,h,w,d}}\)是在训练期间根据目标模态进行不同学习和应用的调制参数。
此外,压缩模型基于 VQGAN,并使用基于先前研究的重建损失、量化损失、感知损失和基于补丁的对抗目标进行训练。此外,作者还结合了循环一致性损失,以确保原始输入可以通过循环路径重建回原始图像。训练过程如图3(a)所示。

2.扩散模型
LDM 通过训练压缩潜在空间中的扩散过程来实现高分辨率图像合成,同时降低计算成本。受之前研究的启发,我们设计了一个LDM,除了噪声目标潜在变量(noisy target latents)之外,还采用target-like latents作为输入。该过程如图 2 (b) 所示。
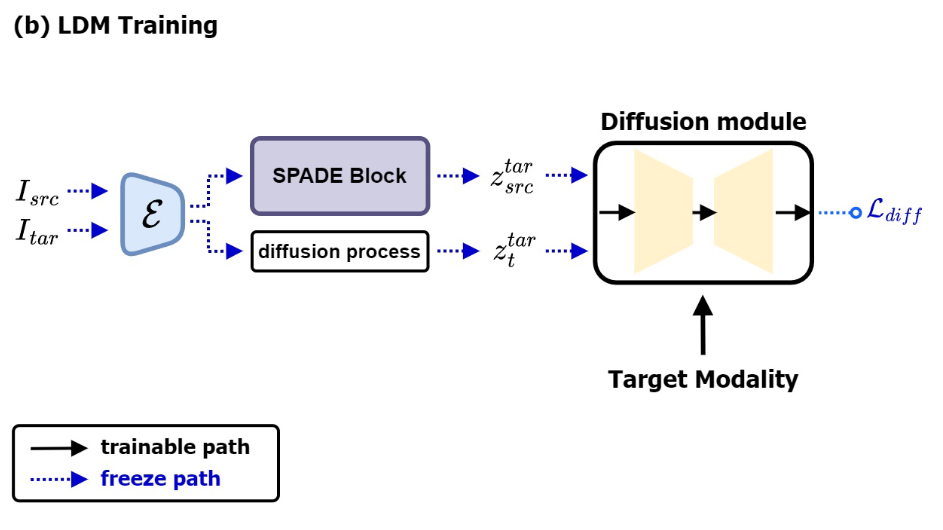
潜在 \(\textcolor{blue}{z^{tar}_{src}}\) 表示通过 SPADE 块将 source latents 转换为 target-like latents 。以强调 true target latents 和来自 SPADE 的 latents 之间的差距。 \(\textcolor{blue}{z^{tar}_{t}}\) 表示时间步 \(\textcolor{blue}{t}\) 处的 noisy input latents。扩散模型以 \(\textcolor{blue}{z^{tar}_{src}}\) 和 \(\textcolor{blue}{z^{tar}_{t}}\) 作为时间步 \(\textcolor{blue}{t}\) 的输入来执行预测该时间步的噪声 \(\textcolor{blue}{ε}\) 的任务。在训练扩散模型的过程中,用于图像压缩的自编码器被冻结,仅训练扩散模型(如图3(b)所示)。损失函数定义如下:

3.模态条件
受到先前研究中成功利用交叉注意力作为条件图像生成器的启发,作者将模态条件纳入到该模型中,以增强图像到目标模态的转换。该方法包括将给定的模态转换为 one-hot 向量 \(\textcolor{blue}{y}\) ,并将其用作训练期间交叉注意力的键和值分量的输入。UNet 中的交叉注意力操作如下:

这里, \(\textcolor{blue}{φ_i(z_t) \in R^{N×d_ε}}\) 表示UNet预测 \(\textcolor{blue}{ε_\theta}\) 的中间表示,\(\textcolor{blue}{W^{(i)}_Q \in R^{d×d_ε}}\) 、\(\textcolor{blue}{W^{(i)}_K \in R^{d×d_y}}\)和\(\textcolor{blue}{W^{(i)}_K \in R^{d×d_y}}\)分别为可学习的投影矩阵。使用模态条件重新定义损失函数,表示为 Ldiff,其中 y 表示给定模态类的独热向量。
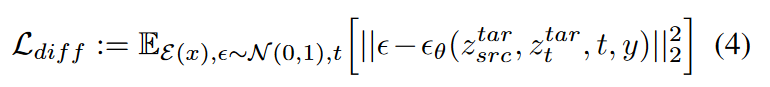
对于推理过程,我们利用从图像压缩阶段获得的编码器。我们通过将source image传递给编码器和 MS-SPADE 块来获得target-like latents。然后将该latents与随机噪声连接起来并用作扩散模型的条件,从而促进图像转换为目标模态。
三、实验
数据集:为了评估模型的有效性,利用了 2021 年多模式脑肿瘤分割挑战赛 (BraTS 2021) 数据集。我们使用 BraTS 2021 训练数据集训练我们的模型,该数据集由 1251 名受试者组成,包括四种 MRI 模式(T1、T1ce、T2、FLAIR)。为了评估我们模型的图像翻译能力,我们使用了 BraTS 2021 验证数据集,其中包含 219 个受试者。作者还在 IXI 数据集上验证了我们的模型,其中包括 T1、T2 和 PD 模式。在 574 名受试者中,459 名用于训练,115 名用于测试。
评估指标:使用峰值信噪比(PSNR)、归一化均方误差(NMSE)和结构相似性指数(SSIM)来评估合成质量。它们是根据真实图像和合成目标图像之间计算的。指标的平均值和标准差是在与训练验证集不重叠的独立测试集上报告的。所有测试均在 3D 上进行评估。对于 2D 方法,将合成的目标图像堆叠起来形成 3D 以进行比较。
1.对比实验
表 1 展示了每种方法在两个不同数据集上对三个任务的定量评估:T1 → T2、T2 → FLAIR 和 T1 → PD。
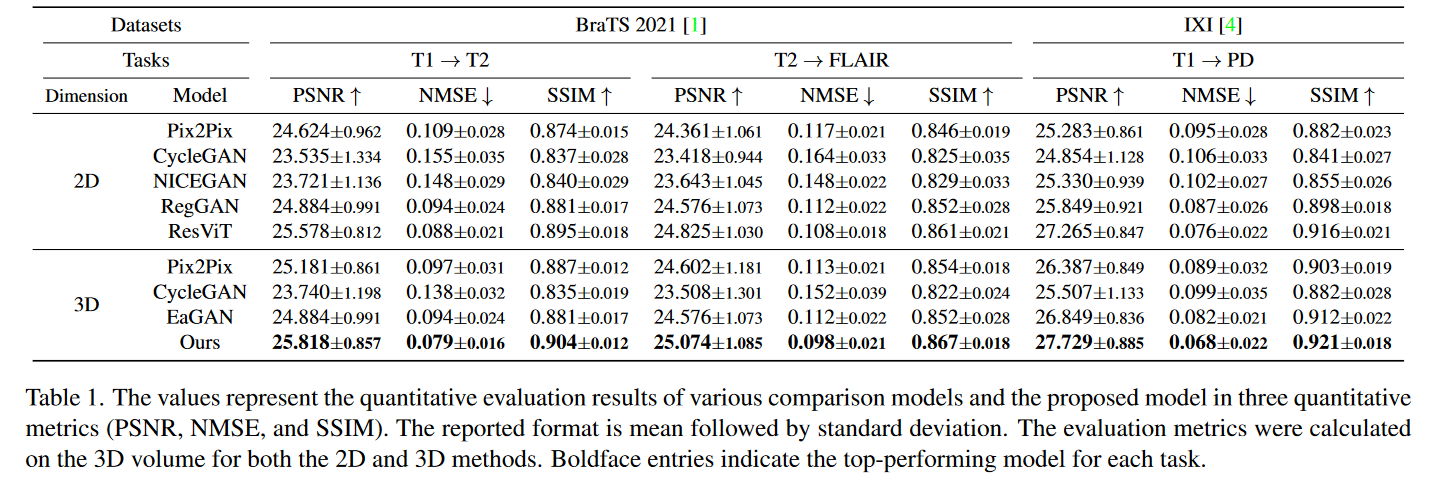
此外,在描述定性评估的图 4 中,该模型实现了与真实情况最接近的相似性,并且合成的图像与具有挑战性的肿瘤区域(绿色边界框)密切匹配。
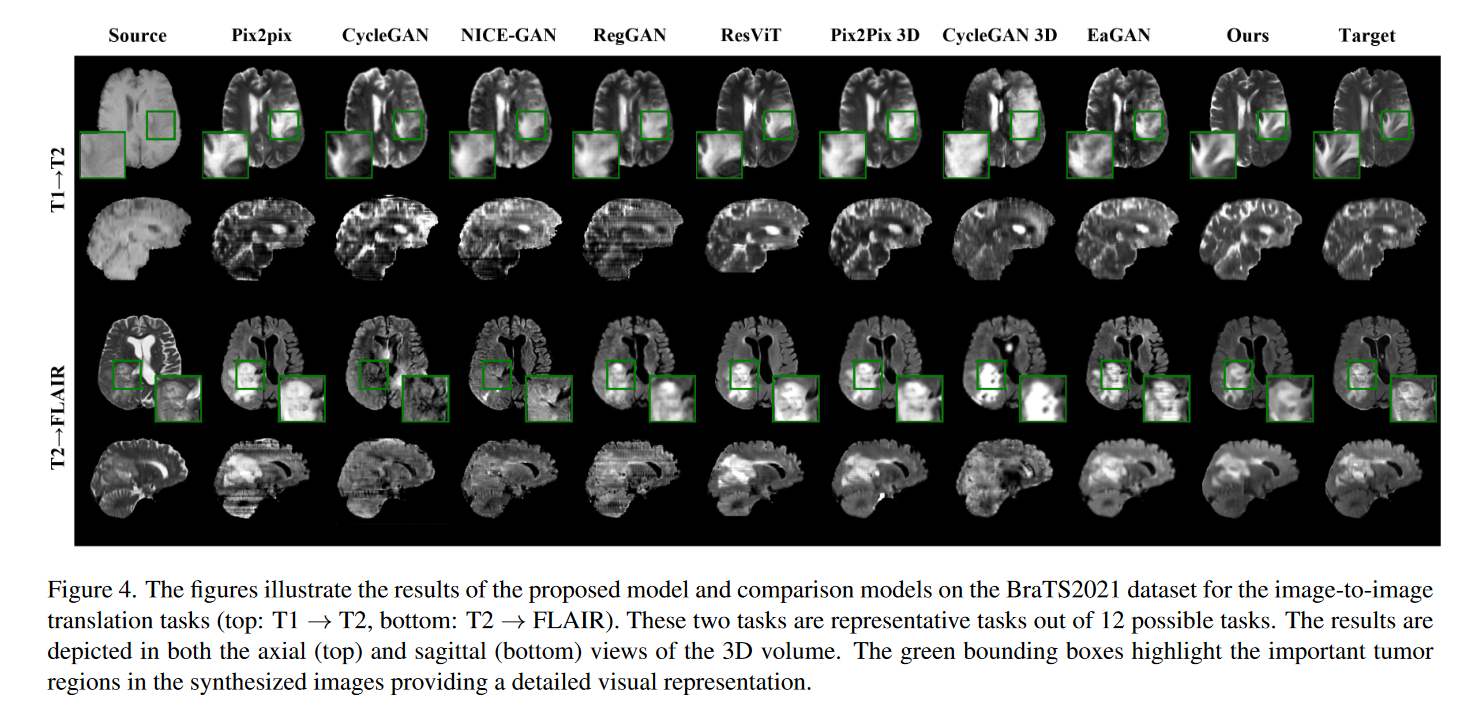
这些结果表明,我们提出的模型不仅允许从单一模态生成多种模态,而且优于为单一任务设计的网络。此外,它还展示了 3D 体积图像的成功合成,无需进行补丁裁剪等预处理步骤。
2.多模态图像翻译
作者使用他们提出的模型进行了图像翻译实验,在给定四种 MRI 模态的情况下,将一种源模态转换为另一种目标模态的不同场景。图 6 可视化了从每种源模态到目标模态的图像转换任务的结果,展示了 BraTs 数据集在所有情况下成功的图像合成。
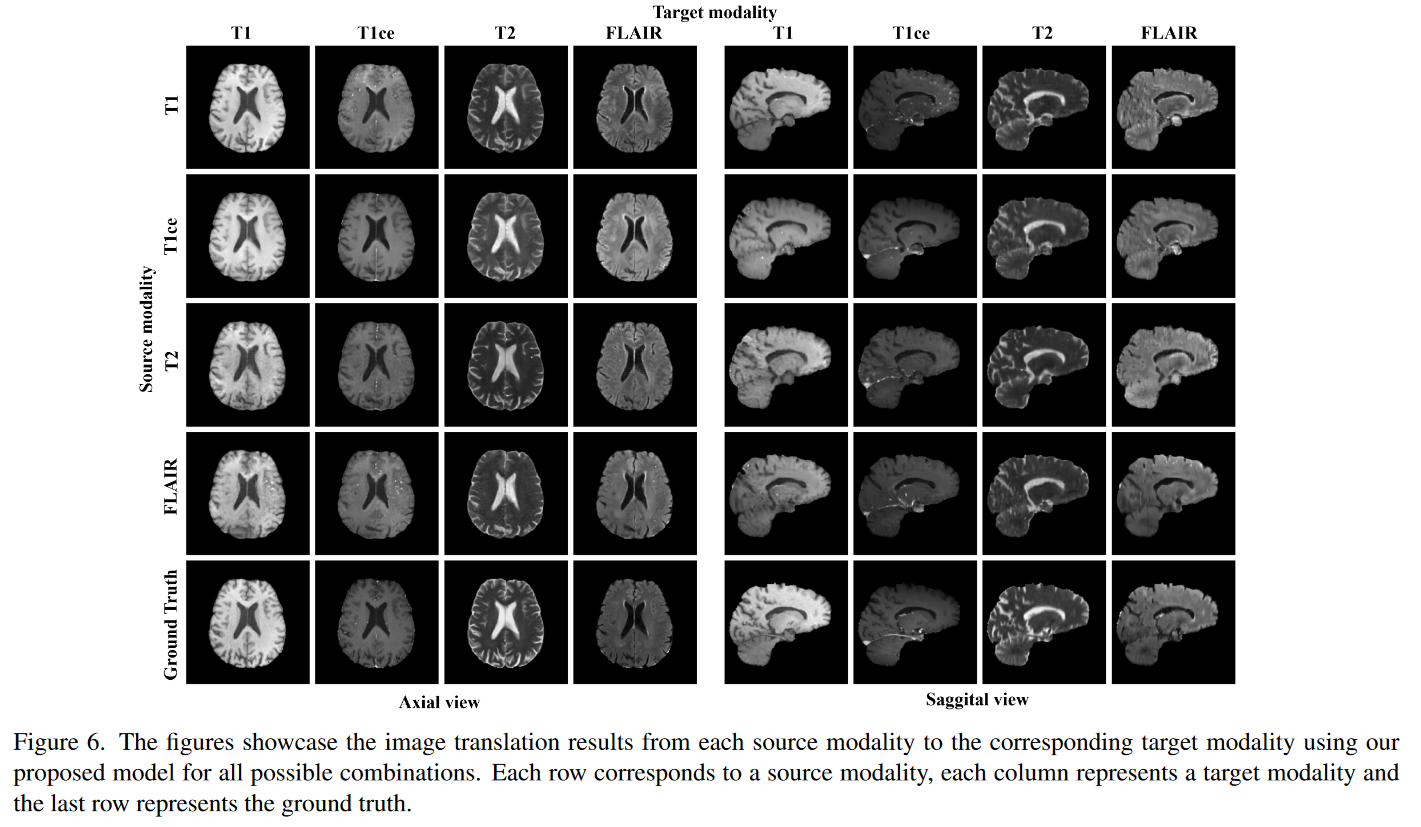
对角线条目表示源模态和目标模态相同的任务。表 2 中每个任务的定量评估揭示了我们提出的 BraTs 数据集模型的性能。

当源为 T1ce 时实现。同样,对于 T1ce 的目标,F1 的源产生最高的性能。当目标为 T2 时,使用 FLAIR 作为源会产生最佳结果。最后,当目标是 FLAIR 时,当源是 T1ce 时翻译性能最高。 T1ce 是一种使用造影剂的 MRI,与其他模式相比,包含有关解剖学和肿瘤的丰富信息,这解释了它作为图像翻译源模式的优越性能。然而,获得 T1ce(需要注射造影剂)在许多情况下可能具有挑战性。因此,我们的结果证明了在获得 T1ce 困难时利用替代模式进行图像翻译的可行性。
3.消融实验
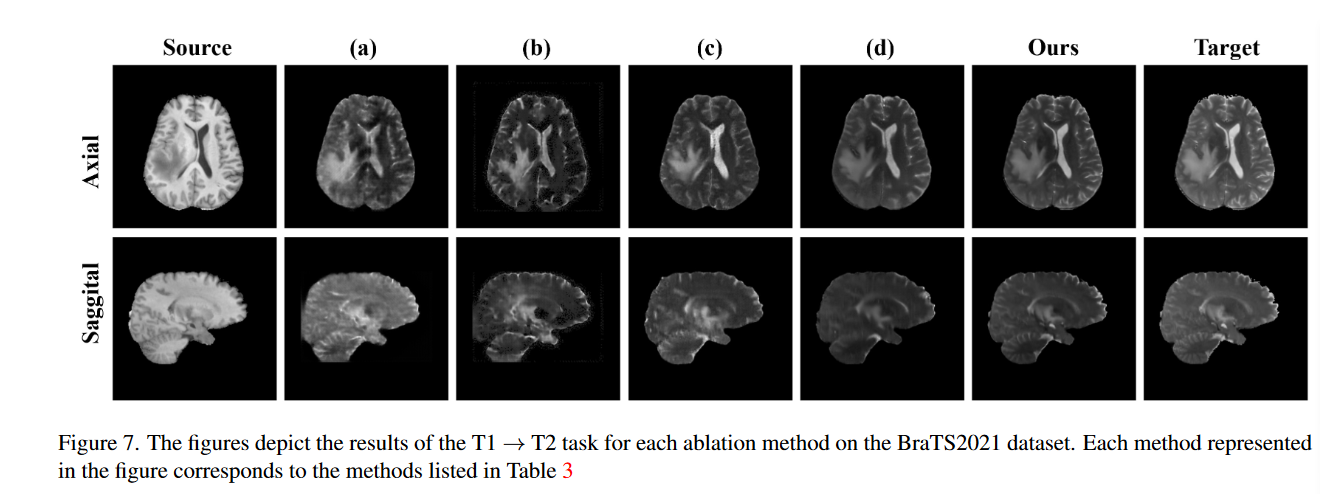
为了证明模型中设计组件的增量价值,作者进行了几行消融研究。具体来说,使用 BraTS 数据集评估了专注于 T1→T2 任务的扩散模型、Palette模块、MS-SPADE 块和图像压缩模型的性能贡献。表3给出了定量评估结果,图7展示了BraTs数据集消融研究中每种方法的图像合成结果。
在表 3 中,(a) 表示单独使用扩散模型时的翻译性能,表明图像翻译是可以实现的。然而,(b) 添加调色板后显示出优越的性能。此外,(c) 显示了仅使用 MS-SPADE 块而没有扩散模型进行风格迁移的结果,表明图像转换性能的局限性。 (d)和“ours”代表了先前研究中应用的图像压缩模型的不同正则化类型的结果。 KL-reg 虽然对于 3D 训练来说计算成本较高,但由于模型大小的调整而对性能产生了影响,导致压缩结果稍微模糊。据观察,当所有元素一起使用时,可以获得最佳翻译性能。

四、总结
本文介绍了一种多模态图像翻译模型,并进行了全面的实验来评估其性能。该模型展示了跨不同源和目标模式的成功图像合成,展示了其多功能性。通过将该方法与现有方法进行比较,本文的方法在定量和定性评估方面都优于它们。此外,本文的模型展示了执行一对多图像合成的能力,超越了其他模型执行的一对一任务的限制。我们还表明,即使没有补丁裁剪等预处理步骤,我们的模型也能实现出色的性能,并且可以成功地对 3D 医学图像进行图像合成。由于所提出方法的 3D 性质,我们的方法可能计算成本较高。未来的工作包括从两种以上的源模态转换为选定的目标模态,并在其他医学成像(例如计算机断层扫描)上进行验证。