
一、介绍
现有的视频生成工作利用了不同类型的生成模型,包括 GAN、VAE、自回归模型和归一化流。特别是,GAN 在图像生成方面取得了巨大成功,因此将其扩展到具有专用时间设计的视频生成当中取得了出色的结果。然而,GAN 存在模式崩溃和训练不稳定问题,这使得基于 GAN 的方法难以扩展以处理复杂且多样化的视频分布。最近,TATS提出了一种自回归方法,利用 VQGAN 和 Transformer 来合成长视频。但生成保真度和分辨率(128×128)仍有很大提升空间。
为了克服这些限制,本文作者利用扩散模型(DM)。然而,直接将 DM 扩展到视频合成需要大量的计算资源。此外,大多数文本到视频生成模型尚未向公众开放,这阻碍了该领域的研究进展。为了解决这些问题,本文作者设计了 LVDM,这是一种在视频潜在空间中有效的视频扩散模型,并通过简单的基本 LVDM 模型实现了最先进的结果。此外,为了进一步生成长距离视频,作者引入了分层 LVDM 框架,可以将视频扩展到远远超出训练长度的范围。然而,生成长视频往往会遇到性能下降的问题。为了缓解这个问题,作者还提出了条件潜在扰动和无条件指导,这可以有效减缓性能随着时间的推移而下降。最终,该框架在短视频和长视频生成方面超越了许多以前的作品,并在三个数据集上建立了新的最先进的性能。作为扩展,我们还提供文本到视频生成的附加结果。


二、方法
首先通过Video autoencoder将视频样本压缩到低维潜在空间。作者设计了一种统一的视频扩散模型,它可以在一个网络的潜在空间中执行无条件生成和条件视频生成。这使得该模型能够将生成的视频自回归地自动扩展至任意长度。然而,自回归模型只会随着时间的推移而出现性能下降的问题。为了进一步提高生成的长视频的一致性并缓解质量下降问题,作者提出了分层潜在视频扩散模型,首先稀疏地生成视频专利,然后插入中间潜在视频。作者还提出了条件潜在扰动和无条件指导来解决长视频生成中的性能下降问题。
1. Video Autoencoder
该框架使用轻量级3D自动编码器来压缩视频,其中包括编码器\(\textcolor{blue}{\mathcal{E}}\)和解码器\(\textcolor{blue}{\mathcal{D}}\)。它们都使用了3D卷积层。给予一段视频\(\textcolor{blue}{x_0 \sim p_{data}(x_0)}\),其中\(\textcolor{blue}{x_0 \in R^{H \times W \times L \times 3}}\)。编码器\(\textcolor{blue}{\mathcal{E}}\)将其编码为潜在表示\(\textcolor{blue}{z_0 = \mathcal{E}(x_0)}\), 其中\(\textcolor{blue}{z_0 \in R^{h \times w \times l \times c}}\), \(\textcolor{blue}{h = H/f_s, w=W/f_s, l=L/f_t}\)。\(\textcolor{blue}{f_s}\)和\(\textcolor{blue}{f_t}\)是空间和时间下采样因子。解码器\(\textcolor{blue}{\mathcal{D}}\)将\(\textcolor{blue}{z_0}\)解码为重构样本\(\textcolor{blue}{x_0}\),即\(\textcolor{blue}{x_0 = \mathcal{D}(z_0)}\)。为了确保autoencoder在时间上平移等变,遵循TATS在所有三维卷积中使用重复填充(repeat padding)
训练目标包括重建损失\(\textcolor{blue}{\mathcal{L}_{rec}}\)和对抗损失\(\textcolor{blue}{\mathcal{L}_{adv}}\)。重建损失\(\textcolor{blue}{\mathcal{L}_{rec}}\)由像素级均方误差(MSE)损失和感知级 LPIPS损失组成。对抗性损失则用于消除通常由像素级重建损失引起的重建模糊,进一步提高重建的真实感。综上所述,\(\textcolor{blue}{\mathcal{E}}\)和\(\textcolor{blue}{\mathcal{D}}\)的总体训练目标是
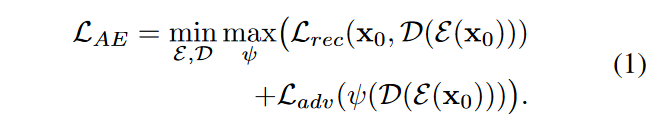
其中\(\textcolor{blue}{\mathcal{ψ}}\)是对抗训练中使用的判别器。
2. LVDM用于短视频生成
在得到一个预训练好的视频自动编码器以后,对视频潜在空间进行扩散和去噪。给定一个已经经过压缩的潜在编码\(\textcolor{blue}{z_0 \sim p_{data}(z_0)}\),扩散模型以在T个时间步中从纯高斯噪声\(\textcolor{blue}{z_T \sim \mathcal{N}(z_T;0,I)}\)开始生成潜在样本,产生一组噪声潜在变量,即\(\textcolor{blue}{z_1,...,z_T}\)。前向扩散过程根据预定义的variance schedule\(\textcolor{blue}{\beta_1,...,\beta_T}\)逐渐向\(\textcolor{blue}{z_0}\)添加噪声
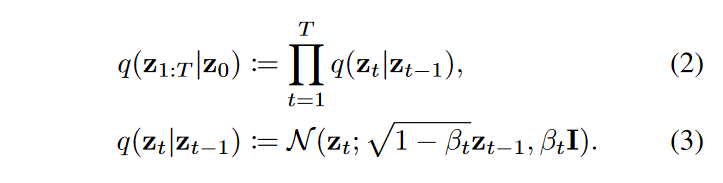
最终,数据点 \(\textcolor{blue}{z_T}\) 变得与纯高斯噪声无法区分。为了从 \(\textcolor{blue}{z_T}\) 恢复 \(\textcolor{blue}{z_0}\) ,扩散模型通过以下方式学习逆向过程:
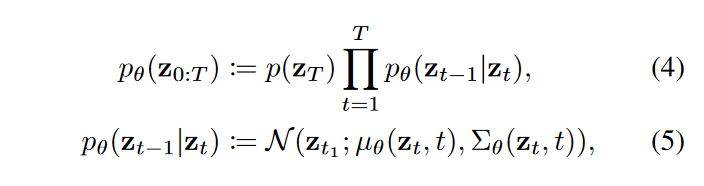
其中 \(\textcolor{blue}{θ}\) 是参数化神经网络,通常是图像合成中常用的 U-Net,用于预测 \(\textcolor{blue}{μ_θ(z_t, t)}\)和 \(\textcolor{blue}{Σ_θ(z_t, t)}\)。在实践中,我们通过以下方式参数化 \(\textcolor{blue}{μ_θ(z_t, t)}\)
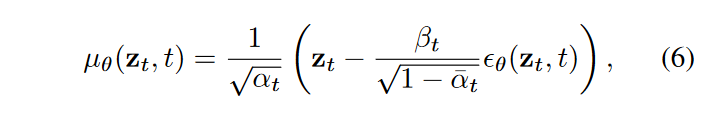
其中 \(\textcolor{blue}{\epsilon_θ(z_t, t)}\) 最终被会估计。我们简单地设置 \(\textcolor{blue}{Σ_θ(z_t,t)=β^2_tI}\)。训练目标是变分界限的简化版本:
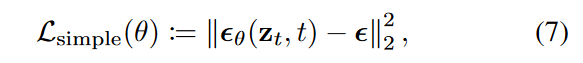
其中\(\textcolor{blue}{\epsilon}\)是从对角高斯分布得出的。
视频生成:为了在 3D 潜在空间中对视频样本进行建模,遵循VDM(视频扩散模型),利用时空分解的 3D U-Net 架构来估计 。具体来说,我们使用形状为 1 × 3 × 3 的纯空间 3D 卷积,并在部分层中添加时间注意力。我们研究两种注意力:联合时空自注意力(joint spatial-temporal self-attention)和分解时空自注意力(factorized spatial-temporal self-attention)。我们观察到,与分解的注意力相比,应用联合时空注意力并没有表现出显着的好处,同时增加了模型的复杂性并有时在随机位置引入点状伪影。因此,我们在实验中使用分解的时空注意力作为默认设置。我们使用自适应组归一化将时间步嵌入注入归一化模块中,以控制通道尺度和偏差参数,这也被证明有利于提高样本保真度。
3. 分层LVDM用于长视频生成
上述框架只能生成短视频,其长度由训练时输入的帧数决定。因此,作者提出了一种条件潜在扩散模型,它可以以自回归的方式产生以先前潜在代码为条件的未来潜在代码,以促进长视频的生成。我们进一步提出了几种减轻自回归生成中的误差累积问题的技术。
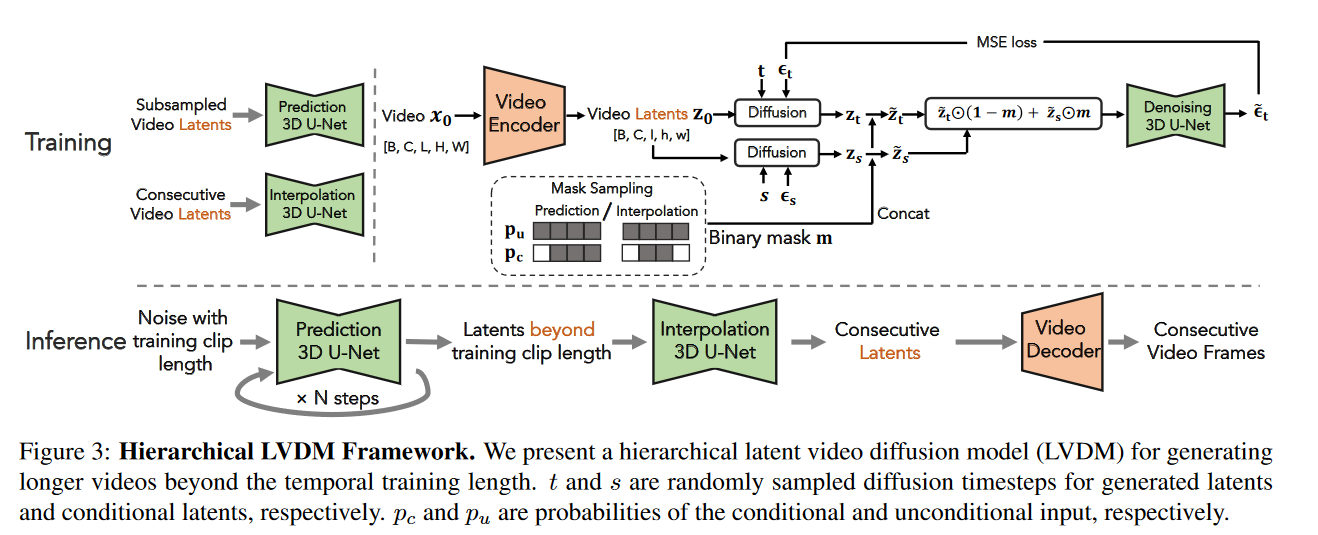
自回归潜在预测(Autoregressive Latent Prediction):考虑一段短裁剪潜在向量\(\textcolor{blue}{z_t=\{z^i_t\}^l_{i=i}}\)其中, \(\textcolor{blue}{z_t^i \in R^{h \times w \times c}}\)并且 \(\textcolor{blue}{l}\) 是裁剪潜在向量数。作者的想法是以前的潜在代码为条件来预测未来的潜在代码。对于裁剪潜在代码中的每个视频帧,我们沿着通道维度添加一个额外的二进制掩码来指示它是条件帧,还是要预测的帧,并根据掩码将\(\textcolor{blue}{z^i_t}\)替换为\(\textcolor{blue}{z^i_0}\),得到
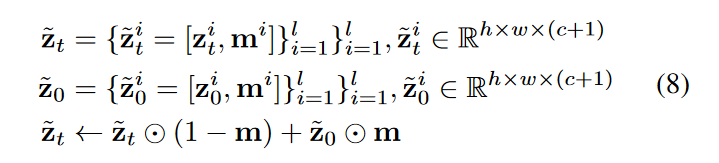
其中,\(\textcolor{blue}{m_t=\{m^i\}^l_{i=1}, m^i \in R^{h \times w \times 1} }\)是二元掩码。通过随机将不同的二进制掩码设置为1或0,可以训练扩散模型来联合执行无条件视频生成和条件视频预测。具体来说,当将二进制裁剪\(\textcolor{blue}{m}\)中的所有掩膜设置为0,以进行无条件扩散模型训练。在推理阶段,我们将前\(\textcolor{blue}{k}\)个二进制掩码\(\textcolor{blue}{\{m^i\}^l_{i=1}}\)设置为1,将剩余的\(\textcolor{blue}{\{m^i\}^l_{i=k+1}}\)设置为0。
分层潜在生成(Hierarchical Latent Generation):以自回归方式生成视频存在因时间累积误差而导致质量下降的风险。因此,作者利用一种通用策略,即分层生成来缓解这个问题。具体来说,首先在稀疏帧上训练自回归视频生成模型以形成视频的基本故事情节,然后训练另一个插值模型来填充丢失的帧。插值模型的训练与自回归模型类似,只是我们将每两个稀疏帧之间的中间帧的二进制掩码设置为零。
条件潜在扰动(Conditional Latent Perturbation)。虽然上述分层生成方式可以减少自回归步骤的数量来克服退化问题,但是为了产生足够长的视频样本,更多的预测步骤是必不可少的。因此,作者提出条件扰动来减轻前一代步骤引起的条件误差。具体来说,我们不是直接以\(\textcolor{blue}{z_0}\)为条件,而是使用任意时间\(\textcolor{blue}{s}\)处的噪声潜在代码 \(\textcolor{blue}{z_s}\)(可以通过(3)计算)作为训练期间的条件,即 \(\textcolor{blue}{\{z^i_t\}^k_{i=1}←\{z^i_s\}^k_{i=1}}\)。这意味着我们还在条件帧上执行扩散过程。为了保留条件信息,使用最大阈值\(\textcolor{blue}{s_{max}}\) 将时间步限制在较小的噪声水平。在采样过程中,固定噪声水平用于在自回归预测期间持续添加噪声。条件潜在扰动受到条件噪声增强的启发,条件噪声增强已在级联扩散模型中提出,以提高超分辨率扩散模型的性能。我们将其扩展到视频预测,并且我们是第一个证明其在生成长视频样本方面的有效性的人。
无条件指导:另一种缓解自回归视频生成质量下降的补充技术是利用无条件分数来指导条件生成过程。由于自回归生成过程中的累积误差不会影响无条件分数,因此将该分数引入长视频生成中可以提高采样视频的多样性和保真度。由于上述联合训练技术,我们可以使用一个网络来估计无条件分数\(\textcolor{blue}{u}\)和条件分数\(\textcolor{blue}{c}\)。通过将\(\textcolor{blue}{\tilde{z}}\)中的所有二进制映射\(\textcolor{blue}{\{m^i\}^l_{i=1}}\) 归零,我们得到\(\textcolor{blue}{u}\)。通过将\(\textcolor{blue}{\tilde{z}}\)中的前 \(\textcolor{blue}{k}\) 个二进制映射\(\textcolor{blue}{\{m^i\}^k_{i=1}}\)设置为 1,并将其余的 \(\textcolor{blue}{\{m^i\}^l_{i=k+1}}\)设置为零,我们得到\(\textcolor{blue}{c}\)。请注意,由于自回归预测时的误差累积,条件分数可能会超出模型学习的分布。因此,我们建议利用无条件分数来指导预测采样过程:
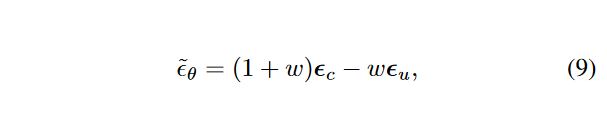
其中\(\textcolor{blue}{w}\)是引导强度。该公式被称为无分类器指导,以避免为类条件扩散模型训练单独的分类器。作者扩展了这个想法来指导帧条件扩散模型生成更长的视频。
三、实验
1. 实验设置
数据集:本文在 UCF-101、Sky Time-lapse 和 Taichi 上评估我们的方法。在这些数据集上以 \(256^2\) 分辨率训练所有模型,以实现无条件视频生成。用于训练的短视频是在一个视频的随机位置以帧步幅为 1 选择的。对于Taichi,选择帧步幅为 4 的剪辑(即选择一帧后跳过三帧),以使人体运动更加动态。由于UCF-101和Taichi中的视频数量有限,我们采用完整数据集进行训练。对于 Sky Time-lapse 数据集,我们仅在其训练分割上训练模型。所有模型都是在无条件设置下训练的,没有提供指导信息,例如类别标签。
评估指标:为了定量评估,使用短视频和长视频生成中常用的 FVD 和 KVD。具体来说,我们计算了2048个16帧的真假视频的FVD和KVD,我们将其称为\(FVD_{16}\)和\(KVD_{16}\),用于短视频评估。短视频生成的所有结果都是在十次运行中计算的,并报告其平均值和标准差。对于长视频评估,我们在每个非重叠 16 帧剪辑中的 512 个样本中估计 FVD 和 KVD,并报告 1 次运行中计算的 1024 帧的 FVD 曲线,称为 \(FVD_{1024}\)。
baseline:我们将我们的方法与七个竞争基线进行了比较,包括基于 GAN 的方法:TGANv2 、DiGAN 、MoCoGAN-HD 和长视频 GAN 、自回归模型 TATS 以及大多数最近基于扩散的模型,包括视频扩散模型(VDM)和MCVD。
实施细节:分别使用空间和时间下采样因子 8 和 4。首先训练一个 3D 自动编码器,然后固定其权重,然后开始在短视频剪辑上训练无条件 LVDM。之后,LVDM 预测和 LVDM 插值模型从无条件模型恢复。
2. 效率比较
为了证明该方法的训练和采样效率,作者将他们的方法与两个像素空间视频扩散模型进行比较,包括表 1 中的 VDM 和 MCVD在 UCF-101 数据集上。
我们使用基本的无条件视频扩散模型来实现 VDM,以合成低分辨率视频(16 帧,分辨率为 \(64^2\)),并使用视频超分辨率扩散模型来将空间分辨率提升到 \(256^2\)。我们按照其官方设置来训练 MCVD,除了我们将其缩放到分辨率 \(256^2\)。当使用相似的时间和模型参数数量进行训练时,我们的方法比它们实现了更好的 FVD。
3. 短视频生成
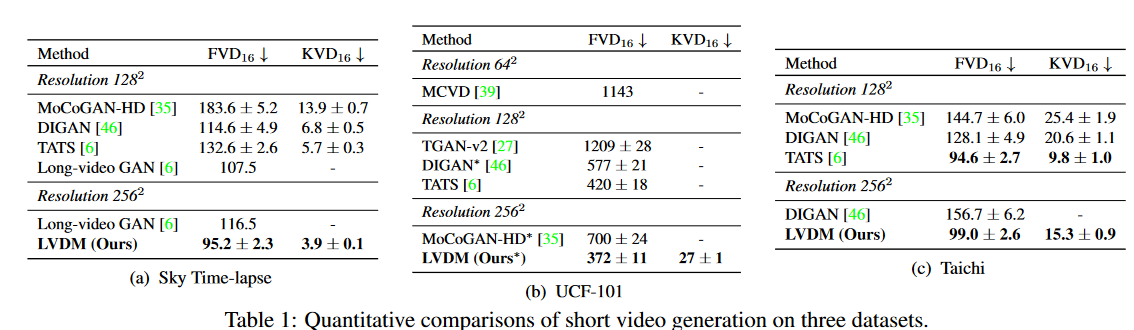
定量结果:在表1中,作者分别在 Sky-Timelapse、UCF-101 和 Taichi 上与之前的方法进行了定量比较。LVDM大大优于以前最先进的方法。具体来说,在Sky-Timelapse数据集上,作者在\(256^2\)分辨率下将FVD从116.5降低到95.18。此外,在高分辨率性能比较也超过了\(128^2\)分辨率下FVD中最先进的方法。在 UCF-101 和 taichi 数据集上,LVDM在 2562 分辨率下实现了新的最先进结果,而该FVD 与 \(128^2\) 分辨率下的最佳结果相当。LVDM 在 UCF 上优于基于扩散的方法 MCVD -101 关于 FVD 和分辨率。
定性结果:在图 4 中,展示了LVDM与 DIGAN和 TATS 的视觉比较。我们观察到,DIGAN 生成的样本在许多样本中表现出类似坐标的伪影,TATS 倾向于生成内容扁平且缺乏多样性的样本,而LVDM 可以合成具有高保真度和多样性的视频样本。

4. 长视频生成
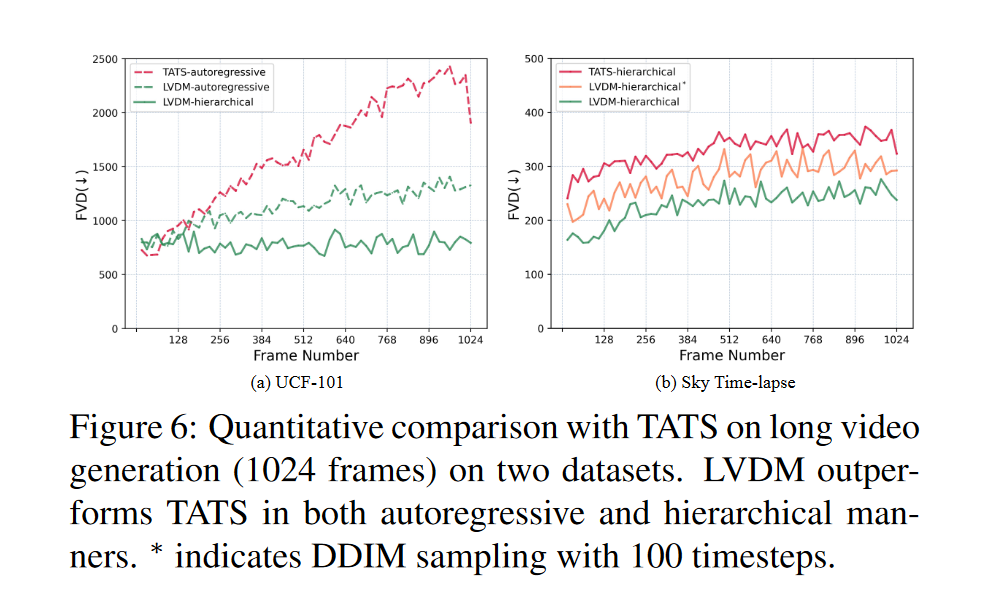
与最先进方法的比较:将 LVDM 与 TATS 进行比较,以在 UCF-101 和 Sky Timelapse 数据集上生成 1024 帧的长视频。 LVDM 和 TATS 都试验了纯自回归预测模型(自回归)以及预测模型与插值模型(分层)的组合。图5和图6分别给出了定性和定量比较结果。请注意,TATS 不提供 UCF-101 上的分层检查点。在天空延时摄影中,我们比较了分层设置下的两种方法。与 TATS 相比,我们的方法随着时间的推移实现了较低的 FVD 分数和较慢的质量退化。具体来说,在挑战 UCF-101 时,我们的 LVDM 自回归随着时间的推移质量下降速度比 TATS 自回归要慢得多。我们的 LVDM 分层结构进一步显着缓解了质量下降问题。在 Sky Timelapse 上,随着时间的推移,两种方法都会出现轻微的质量下降,而我们的方法具有更好的生成性能。

条件潜在扰动:图7(a)显示了条件潜在扰动的消融结果。我们可以观察到它可以减缓性能下降的趋势,特别是当帧数大于512时,证明了它在长视频生成上的有效性。
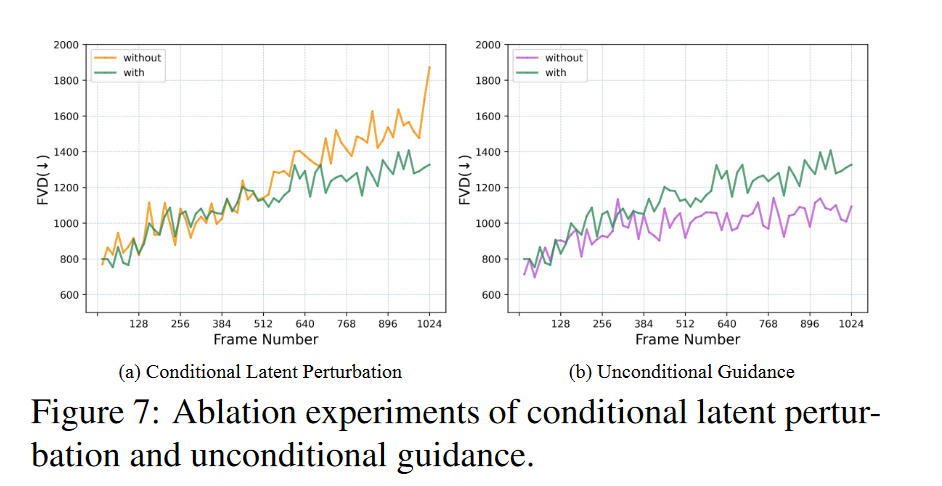
无条件指导:此外,还探索了无条件指导,试图通过利用无条件分数以指导强度指导自回归条件生成来减轻自回归生成的质量下降。图7(b)表明该技术有效地缓解了长视频生成的质量下降。
四、文本到图像生成的扩展
除了无条件视频生成之外,作者还将该方法扩展到更可控的文本到视频生成。并将模型扩展到十亿级参数,并在 WebVid 数据集的 200 万个子集上训练LVDM模型。为了有效地学习视频生成模型,一种自然的想法是利用预先训练的文本到图像模型来重用空间内容生成能力并继续学习视频数据集上的运动动力学。因此,我们使用预先训练的稳定扩散权重来初始化模型的空间参数,包括空间卷积和空间注意力。我们将时间模块(包括多层时间自注意力)初始化为恒等映射,以保持空间生成性能。文本到视频的结果如图 1 所示。
五、总结
在这项工作中,作者设计了一种高效的基于 DM 的视频生成框架,该框架显着降低了数据维度并加快了训练和采样速度。并且还设计了分层框架可以有效地生成超过一千帧的长视频。凭借其更好的建模能力,LVDM在短视频和长视频生成设置下的各种数据集上取得了最先进的结果。作者进一步证明了无条件引导和条件潜在扰动在减少自回归延长视频长度期间引起的累积误差方面的有效性。作者还提供了开放域文本到视频生成模型的扩展。