
一、前言
至今目前,nlp,cv和其他几个领域的神经架构很大程度已经被Transformer所涵盖。然而,许多类别的图像级生成模型仍然抵制这一趋势,例如在DiT出现之前,扩散模型仍然都在采用卷积U-Net架构作为骨干网络。UNet可以实现输出和输入一样维度,所以天然适合扩散模型。扩散模型使用的UNet除了包含基于残差的卷积模块,同时也往往采用self-attention。
在这项工作中,作者证明U-Net的归纳偏置对扩散模型的性能并不重要,并且可以用Transformers模型去替代。因此这是一类基于Transformers的扩散模型,称之为Diffusion Transformers,简称DiTs。
作者表明,通过在潜在扩散模型(LDM)框架下构建 DiT (其中扩散模型在 VAE 的潜在空间中进行训练),可以成功地用Transformers替换 U-Net 主干。并进一步证明 DiT 是扩散模型的可扩展架构:网络复杂性(以 Gflops 衡量)与样本质量(以 FID 衡量)之间存在很强的相关性。通过简单地扩展 DiT 并训练具有高容量主干(118.6 Gflops)的 LDM,其中最大的模型DiT-XL/2在ImageNet 256x256的类别条件生成上达到了SOTA(FID为2.27)。

二、Diffusion Transformers
1.预备知识
Improved DDPM:和SD不同,DiT所使用的扩散模型沿用了OpenAI的Improved DDPM,即不再采用固定的方差,而是采用网络来预测方差。其生成过程的分布采用一个参数化的高斯分布来建模:
\[\huge p_\theta(x_{t-1}|x_t) = \mathcal{N}(x_{t-1};\mu_\theta(x_t,t),\Sigma_\theta(x_t,t))\]
而在DDPM所采用的是固定方差,在生成过程中将\(\textcolor{blue}{\Sigma_\theta(x_t,t)}\)设置为\(\textcolor{blue}{\beta_t}\)或者\(\textcolor{blue}{\tilde{\beta}_t}\),而\(\textcolor{blue}{\beta_t}\)和\(\textcolor{blue}{\tilde{\beta}_t}\)其实是一个上下限。但\(\textcolor{blue}{\Sigma_θ(x_t, t)}\)的合理范围非常小,因此神经网络很难直接预测\(\textcolor{blue}{\Sigma_θ(x_t, t)}\),作者采用了将方差参数化为对数域中\(\textcolor{blue}{\beta_t}\)和\(\textcolor{blue}{\tilde{\beta}_t}\)之间的插值。就是让模型预测出一个向量\(\textcolor{blue}{v}\),每个维度包含一个分量,我们将此输出转换为方差,如下所示
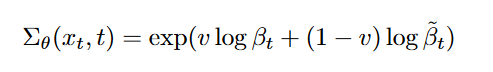
DDPM的\(\textcolor{blue}{\mu_θ(x_t, t)}\)通过\(\textcolor{blue}{L_{simple}}\)来进行优化,但是这个损失函数并不依赖\(\textcolor{blue}{\Sigma_θ(x_t, t)}\),为了优化\(\textcolor{blue}{\Sigma_θ(x_t, t)}\),Improved DDPM采用了一个组合损失函数:
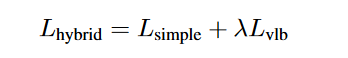
这里的\(\textcolor{blue}{L_{vlb}}\)是扩散模型原始的VLB损失,注意这里在计算VLB时,要截断\(\textcolor{blue}{\mu_θ(x_t, t)}\)的梯度,即\(\textcolor{blue}{L_{vlb}}\)只负责优化\(\textcolor{blue}{\Sigma_θ(x_t, t)}\),而不会影响\(\textcolor{blue}{\mu_θ(x_t, t)}\),这里的系数\(\textcolor{blue}{\lambda}\)默认取0.001。关于VLB的计算,可以参考OpenAI开源的原始代码。 要注意的一点是,预测方差不需要再训练一个网络,而是直接在原来的网络上增加一倍的输出即可,比如对于32x32x4的latent,让网络输出32x32x8就可以了,其中一半用来预测噪音,一半用来预测方差系数\(\textcolor{blue}{v}\)。
Latent diffusion model:直接在高分辨率像素空间中训练扩散模型在计算上可能会令人望而却步。潜在扩散模型(LDM)通过两阶段方法解决这个问题:(1)学习自动编码器,使用学习的编码器 E 将图像压缩为更小的空间表示; (2) 训练表示 \(\textcolor{blue}{z = E(x)}\) 的扩散模型,而不是图像 \(\textcolor{blue}{x}\) 的扩散模型(E 被冻结)。然后可以通过从扩散模型中采样表示 \(\textcolor{blue}{z}\) 并随后使用学习的解码器 \(\textcolor{blue}{x = D(z)}\) 将其解码为图像来生成新图像。如图 2 所示,LDM 在使用 ADM 等像素空间扩散模型 Gflop 的一小部分的情况下实现了良好的性能。在本文中,作者将 DiT 应用于潜在空间,使用现成的卷积 VAE 和基于 Transformer 的 DDPM。

2.Diffusion Transformer的设计方案
引入扩散变压器(DiTs),这是一种扩散模型的新架构。并且尽可能忠实于标准的Transformer架构,以保留其缩放特性。由于本文的重点是训练图像的 DDPM(特别是图像的空间表示),因此 DiT 基于Vision Transformer (ViT) 架构,该架构对patches序列进行操作。 DiT 保留了 ViT 的许多最佳实践。图 3 显示了完整 DiT 架构的概述。

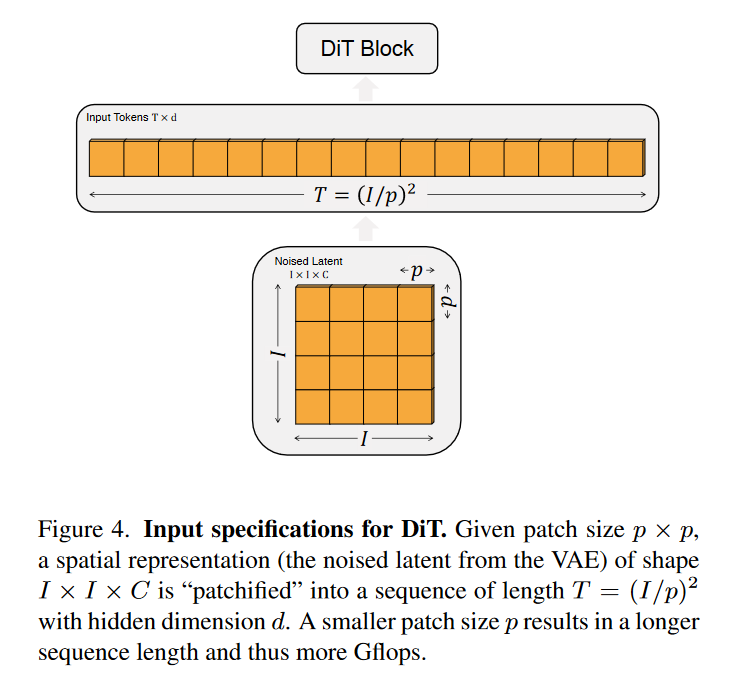
Patchify:DiT 的输入是空间表示 \(\textcolor{blue}{z}\)(对于 256 × 256 × 3 图像,\(\textcolor{blue}{z}\)的形状为 32 × 32 × 4)。 DiT 的第一层是patchify,首先采用一个patch embedding来将输入进行embed化,将空间输入转换为一系列 Tokens,每个标记的维度为 d。 patchify 之后,还需要加上positional embeddings(sin-cosine)应用于所有输入标记。 patchify 创建的token的数量由patch大小超参数 \(\textcolor{blue}{p}\) 决定。如图 4 所示,将 \(\textcolor{blue}{p}\) 减半将使 T 增加四倍,从而使变压器总 Gflop 至少增加四倍,这会影响模型的计算量。DiT的patch大小共选择了三种设置:p = 2, 4, 8 。
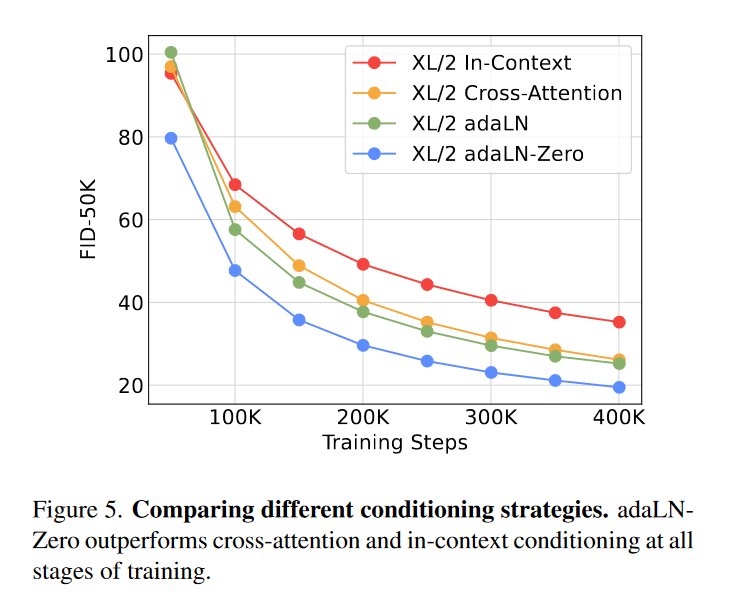
DiT 块:patchify 之后,输入token由一系列transformer blcoks处理。对于扩散模型而言,除了噪声图像输入之外,往往还需要在网络中嵌入额外的条件信息,例如噪声时间步 \(\textcolor{blue}{t}\)、类标签 \(\textcolor{blue}{c}\)、自然语言等。DiT共设计了四种方案来实现条件的嵌入,如图3所示。
1️⃣In-context conditioning:将 \(\textcolor{blue}{t}\) 和 \(\textcolor{blue}{c}\) 的向量嵌入看成两个tokens合并在输入的tokens当中。这类似于 ViT 中的 cls token,它允许我们无需修改即可使用标准 ViT 块。在最后一个块之后,从序列中删除条件token。这种方法向模型引入的新 Gflop 可以忽略不计。
2️⃣Cross-attention block:将 \(\textcolor{blue}{t}\) 和 \(\textcolor{blue}{c}\) 的embeddings拼接成一个长度为 2 的序列,与图像token序列分开。然后在transformer block中插入一个cross attention,条件embeddings作为cross attention的key和value,也类似于 LDM 用于条件类标签的方法。交叉注意力为模型增加了 15% 的Gflops。
3️⃣Adaptive layer norm (adaLN) block:用自适应层范数 (adaLN) 替换Transformer blocks中的layer norm。这里是将\(\textcolor{blue}{t}\)的embedding和\(\textcolor{blue}{c}\)的embedding相加。然后来回归scale和shift两个参数 \(\textcolor{blue}{γ}\) 和 \(\textcolor{blue}{β}\)。在我们探索的三种模块设计中,adaLN 添加的 Gflops 最少,因此计算效率最高。
4️⃣adaLN-Zero block:采用zero初始化adaLN。这里是将adaLN的linear层参数初始化为zero。这样网络初始化时transformer block的残差模块就是一个identity函数。除了回归 \(\textcolor{blue}{γ}\) 和 \(\textcolor{blue}{β}\) 之外,还在每个残差模块结束之前回归一个维度缩放参数 \(\textcolor{blue}{\alpha}\)。与普通 adaLN 模块一样,adaLN-Zero 向模型添加了可忽略不计的 Gflops。
论文对四种方案进行了对比实验,发现采用adaLN-Zero效果是最好的,所以DiT默认都采用这种方式来嵌入条件embeddings。
虽然DiT发现adaLN-Zero效果是最好的,但是这种方式只适合这种只有类别信息的简单条件嵌入,因为只需要引入一个class embedding;但是对于文生图来说,其条件往往是序列的text embeddings,采用cross-attention方案可能是更合适的。
Model size:作者应用一系列 N x DiT 块,每个块都以隐藏维度大小 d 进行操作。遵循 ViT,我们使用标准Transformer配置来联合缩放 N 、 d 和注意力头 。具体来说,本文使用四种配置:DiT-S、DiT-B、DiT-L 和 DiT-XL。其中最大的模型DiT-XL参数量为675M,计算量Gflops为29.1。表 1 给出了配置的详细信息:

Transformer decoder:在最终的 DiT 块之后,我们需要将图像token序列解码为噪声预测和对角协方差预测\(\textcolor{blue}{\Sigma}\)。这两个输出的形状都等于原始空间输入。DiT采用一个简单的linear层来实现,并应用最终层norm(如果使用 adaLN 则为自适应)并将每个token线性解码为 \(\textcolor{blue}{p×p×2C}\) 张量,其中 \(\textcolor{blue}{C}\) 是 DiT 空间输入中的通道数。最后,我们将解码后的token进行reshape为其原始输入空间维度,以获得预测的噪声和协方差。
三、实验
1.实验设置
Training:DiT在 ImageNet 数据集 上以 256 × 256 和 512 × 512 图像分辨率训练类条件潜在 DiT 模型。使用零初始化最终的线性层,否则使用 ViT 的标准权重初始化技术。用 AdamW 训练所有模型。我们使用 1 × 10−4 的恒定学习率,无权重衰减,批量大小为 256。DiT使用的唯一数据增强是水平翻转。在训练过程中保持 DiT 权重的指数移动平均值 (EMA),衰减为 0.9999。报告的所有结果均使用 EMA 模型。
Diffusion:DiT使用来自Stable diffusion的现成预训练变分自动编码器(VAE)模型。 VAE 编码器的下采样因子为 8——给定 RGB 图像 \(\textcolor{blue}{x}\) 的形状为 256 × 256 × 3,\(\textcolor{blue}{z = E(x)}\)的形状为 32 × 32 × 4。在本节的所有实验中,扩散模型在潜在空间中运行。从扩散模型中采样新的潜在变量后,使用 VAE 解码器 \(\textcolor{blue}{x = D(z)}\) 将其解码为像素。使用来自 ADM 的扩散超参数;具体来说,使用范围从 1×10−4 到 2 × 10−2 的 \(\textcolor{blue}{t_{max} = 1000}\) 线性方差表、ADM 的协方差 \(\textcolor{blue}{\Sigma_\theta}\) 参数化及其嵌入输入时间步长和标签的方法。
Evaluation metrics:本文使用FID来衡量缩放性能,这是评估图像生成模型的标准指标。在与之前的作品进行比较时,遵循惯例,并使用 250 个 DDPM 采样步骤报告 FID-50K。众所周知,FID 对小的实施细节很敏感 ;为了确保准确的比较,本文报告的所有值都是通过导出样本并使用 ADM 的 TensorFlow 评估套件获得的。除非另有说明,本节中报告的 FID-numbers不使用无分类器指导。我们还报告了 Inception Score 、sFID和 Precision/Recall 作为次要指标。
Compute:在 JAX中实现所有模型,并使用 TPU-v3 pod 训练它们。 DiT-XL/2 是计算最密集的模型,在 TPU v3-256 pod 上以大约 5.7 次迭代/秒的速度进行训练,全局批量大小为 256。
注:本文模型根据其配置和潜在patch大小 p 命名;例如,DiT-XL/2 指的是 XLarge 配置且 p = 2。
2.Scaling model size and patch size
本文训练了 12 个 DiT 模型,涵盖模型配置(S、B、L、XL)和patch大小(8、4、2)。请注意,与其他配置相比,DiT-L 和 DiT-XL 在相对 Gflop 方面明显更接近。图 2(左)概述了每个模型的 Gflops 及其在 400K 训练迭代时的 FID。该图表明:在所有情况下,增加模型大小和减小patch 大小可以显着改进扩散模型。
图 6(上)展示了 FID 如何随着模型尺寸的增加而变化并且patch 大小保持不变。在所有四种配置中,通过使Transformer更深更宽,FID 在训练的所有阶段都获得了显着改进。同样,图 6(底部)显示了随着patch 大小减小而模型尺寸保持不变的 FID。我们再次观察到,通过简单地扩展 DiT 处理的token数量并保持参数大致固定,整个训练过程中 FID 有了相当大的改进。

3.DiT Gflops 对于提高性能至关重要
图 6 的结果表明参数量并不能唯一地确定 DiT 模型的质量。当模型大小保持不变并且patche大小减小时,Transformer的总参数实际上没有改变(实际上,总参数略有减少),并且仅 Gflops 增加。这些结果表明,缩放模型 Gflops 实际上是提高性能的关键。为了进一步研究这一点,在图 8 中针对模型 Gflops 绘制了 400K 训练步骤下的 FID-50K。结果表明,当总 Gflops 相似时,不同的 DiT 配置会获得相似的 FID 值(例如,DiT-S/2 和 DiT- B/4)。作者发现模型 Gflops 和 FID-50K 之间存在很强的负相关性,这表明额外的模型计算量是改进 DiT 模型的关键因素。

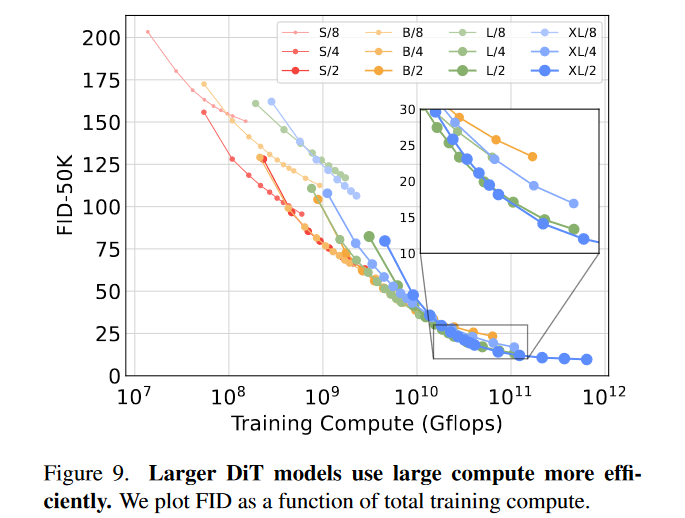
4.较大的 DiT 模型的计算效率更高
在图 9 中,将以FID性能绘制为所有 DiT 模型的总训练计算的函数。横坐标的训练计算估计为模型 Gflops · 批量大小 · 训练步骤 · 3,其中因子 3 大致近似为后向传递的计算量是前向传递的两倍。我们发现,相对于训练步骤较少的大型 DiT 模型而言,小型 DiT 模型即使训练时间较长,最终也会变得计算效率低下。同样,我们发现除了Patch大小之外相同的模型即使在控制训练 Gflop 时也具有不同的性能配置文件。例如,在大约 1010 Gflops 后,XL/4 的性能优于 XL/2。
5.可视化缩放
在图 7 中可视化缩放(这个缩放指的增加Transformer深度/宽度或增加输入token的数量)对样本质量的影响。在 400K 训练步骤中,使用相同的起始噪声 \(\textcolor{blue}{x_{t_{max}}}\) 、采样噪声和类标签从 12 个 DiT 模型中的每一个中采样图像。这让我们可以直观地解释缩放如何影响 DiT 样本质量。事实上,缩放模型大小和标记数量可以显着提高视觉质量。

6.最先进的扩散模型
256×256 ImageNet:本次实验训练了最高 Gflop 模型 DiT-XL/2,执行 700 万步。使用该模型所生成的样本如图1所展示,并与最先进的类条件生成模型进行了比较。在表 2 中报告了结果。当使用无分类器引导时,DiT-XL/2 优于所有先前的扩散模型,将 LDM 实现的先前最佳 FID-50K 3.60 降低到 2.27。图 2(右)显示 DiT-XL/2 (118.6 Gflops) 相对于 LDM-4 (103.6 Gflops) 等潜在空间 U-Net 模型具有计算效率,并且比 ADM 等像素空间 U-Net 模型更高效(1120 Gflops) 或 ADM-U (742 Gflops)。
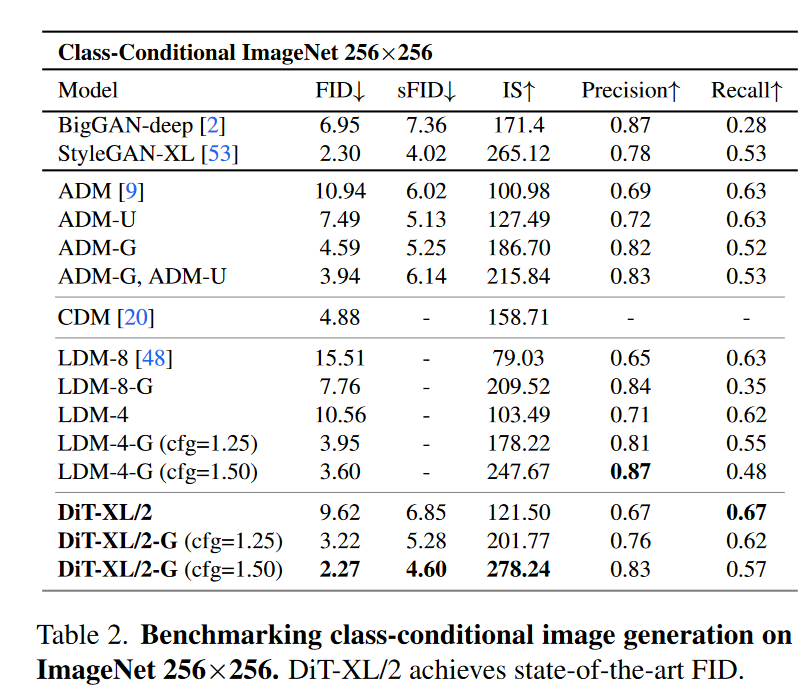
DiT实现了所有现有生成模型中最低的 FID,包括之前最先进的 StyleGAN-XL 。最后,我们还观察到,与 LDM-4 和 LDM-8 相比,DiT-XL/2 在所有测试的无分类器指导量表中实现了更高的召回值。当仅训练 2.35M 步骤时(类似于 ADM),XL/2 仍然优于所有先前的扩散模型,FID 为 2.55
512×512 ImageNet:在 ImageNet 上以 512 × 512 分辨率训练新的 DiT-XL/2 模型,进行 3M 次迭代,其超参数与 256 × 256 模型相同。patch大小为 2 时,该 XL/2 模型在patch 64 × 64 × 4 输入潜在变量 (524.6 Gflops) 后总共处理 1024 个token。表 3 显示了与最先进方法的比较。在此分辨率下,XL/2 再次优于所有先前的扩散模型,将 ADM 实现的先前最佳 FID 3.85 提高到 3.04。即使token数量增加,XL/2 仍然保持计算效率。例如,ADM使用1983 Gflops,ADM-U使用2813 Gflops; XL/2 使用 524.6 Gflops。

7.Scaling Model vs. Sampling Compute
扩散模型的独特之处在于,它们可以通过在生成图像时增加采样步骤数来在训练后使用额外的计算。考虑到模型 Gflops 对样本质量的影响,在本节中,目的是研究较小模型计算 DiT 是否可以通过使用更多采样计算来优于较大模型。在 400K 训练步骤后计算所有 12 个 DiT 模型的 FID,每个图像使用 [16, 32, 64, 128, 256, 1000] 个采样步骤。主要结果如图 10 所示。考虑使用 1000 个采样步骤的 DiT-L/2 与使用 128 个采样步骤的 DiT-XL/2。在这种情况下,L/2 使用 80.7 Tflops 来采样每个图像; XL/2 使用减少 5 倍的计算量(15.2 Tflops)来对每个图像进行采样。尽管如此,XL/2 的 FID-10K 更好(23.7 vs 25.9)。一般来说,扩大采样计算不能弥补模型计算的不足。

四、总结
本文引入了 Diffusion Transformers (DiTs),这是一种基于 Transformer 的简单扩散模型主干,其性能优于之前的 U-Net 模型,并继承了 Transformer 模型类出色的缩放特性。鉴于本文中令人鼓舞的扩展结果,未来的工作应该继续将 DiT 扩展到更大的模型和token数量。 DiT 还可以作为 DALL·E 2 和稳定扩散等文本到图像模型的直接骨干进行探索。