
一、前言
Consistency Models(CM)采用一致性映射将 ODE 轨迹中的任意点直接映射到其原点,从而实现快速一步生成。 CM可以通过蒸馏预训练的扩散模型或作为独立的生成模型来进行训练。 然而,CM仅限于像素空间图像生成任务,使其不适合合成高分辨率图像。此外,尚未探索条件扩散模型的应用和无分类器指导的结合,使得它们的方法不适合文本到图像的生成合成。
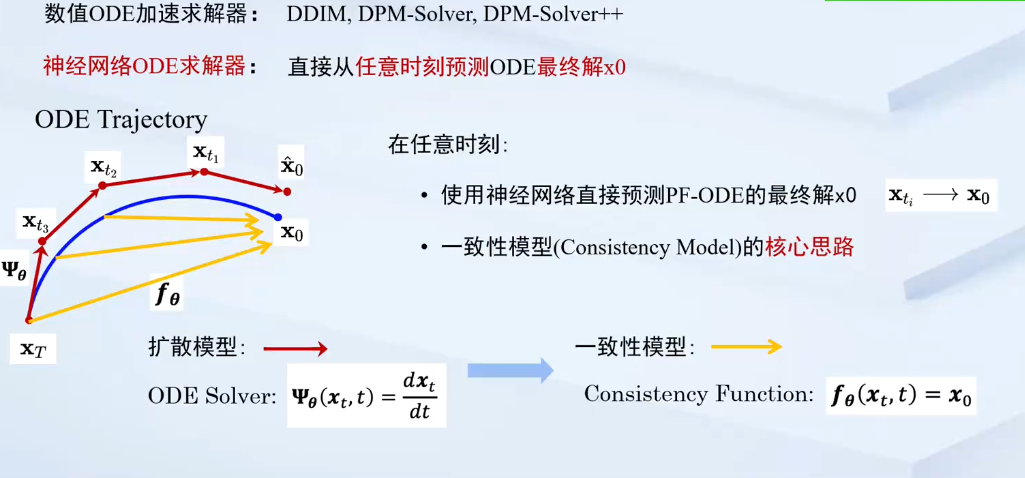
本文提出了Latent Consistency Models (LCMs),LCM 在图像潜在空间中采用一致性模型,可在预训练的潜在扩散模型上实现快速的几步甚至一步高保真采样。 LCM 可以从任何预训练的稳定扩散 (SD) 中提取,只需 4,000 个训练步骤(32 A100 GPU 小时),即可在 2∼4 个步骤甚至一步内生成高质量的 768×768 分辨率图像。


二、潜在一致性模型
1. 潜在空间中的一致性蒸馏(LCD)
在SD中,首先训练自动编码器 \(\textcolor{blue}{(\mathcal{E}, \mathcal{D})}\)将高维图像数据压缩为低维潜在向量\(\textcolor{blue}{z = \mathcal{E}(x)}\),然后将其解码重建为图像\(\textcolor{blue}{\hat{x} = \mathcal{D}(z)}\)。在潜在空间中训练扩散模型大大降低了计算成本,并加快了推理过程; 因此,我们可以利用潜在空间的优势进行一致性蒸馏。作者将这个方法称为潜在一致性蒸馏 (LCD) ,下面就将介绍这个方法的是如何实现的,首先回顾一下逆向扩散过程的PF ODE形式:

其中,\(\textcolor{blue}{z_t}\)是潜在向量,\(\textcolor{blue}{\epsilon_\theta(z_t,c,t)}\)是由神经网络预测出的噪声。\(\textcolor{blue}{c}\)是输入的条件。我们可以通过一系列的求解器去求解该ODE得到一条\(\textcolor{blue}{T}\)到\(\textcolor{blue}{0}\)的轨迹,可以沿着这个轨迹一步步去噪,即可得到我们最终的样本。
当我们引入一致性蒸馏时,可以通过一致性函数\(\textcolor{blue}{f_\theta(z_t,c,t)→ z_0}\)来直接预测 \(\textcolor{blue}{t=0}\) 时 PF-ODE的解。而,一致性函数有两个比较关键的性质:
1️⃣\(\textcolor{blue}{f_\theta(z_t,c,t) = z_0}\)
2️⃣任意\(\textcolor{blue}{t_1,t_2\in [0,T]}\)满足\(\textcolor{blue}{f(x_{t_1},t_1)=f(x_{t_2},t_2)}\)
为了满足当 \(\textcolor{blue}{t=0}\) 时,\(\textcolor{blue}{f_\theta(z_t,c,t) = z_0}\)该性质成立,我们需要将\(\textcolor{blue}{f_\theta}\)参数化为如下的形式:

当设置\(\textcolor{blue}{c_{skip}(0)=1,c_{out}(0)=0}\)就能满足\(\textcolor{blue}{f_\theta(z_t,c,t) = z_0}\)。
之后,可以通过最小化下面这个损失来去拟合第二个性质,LCM 旨在通过最小化一致性蒸馏损失来预测 PF-ODE 的解:
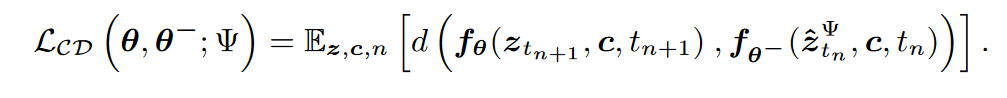
其中,\(\textcolor{blue}{z^Ψ_{t_n}}\) 是使用 ODE 求解器 \(\textcolor{blue}{Ψ}\)对 PF-ODE 从 \(\textcolor{blue}{t_{n+1} → t_n}\) 演化的估计,该估计可由下式所得到。在实践中,我们可以使用 DDIM、DPM-Solver或 DPM-Solver++ 作为 \(\textcolor{blue}{Ψ(·,·,·,·)}\) 。请注意,仅在训练/蒸馏中使用这些求解器,而不是在推理中。
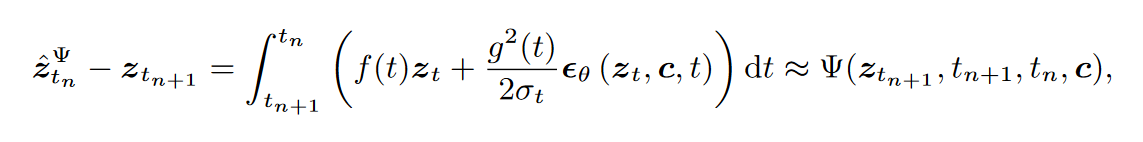
至此,潜在空间的一致性蒸馏训练过程可总结为:🔸从样本集中采样一个样本,使用预训练好的自动编码器使其压缩为潜在变量;🔸将潜在变量加噪变为\(\textcolor{blue}{z_{t_{n+1}}}\),然后利用预训练的 Diffusion 模型去一次噪,并使用上式估计另外一个点\(\textcolor{blue}{z^Ψ_{t_n}}\)。🔸然后计算这两个点送入\(\textcolor{blue}{f_\theta}\)后的结果,用特定损失函数约束其一致。
2. 求解增广PF-ODE的单阶段引导蒸馏
作者想要让LCM能够进行以文本为条件做生成,引入了Classifier-Free Gudiance(CFG)。回顾在逆扩散过程中使用的CFG:

在引导反向过程中,原始噪声预测被条件和无条件噪声的线性组合所取代,其中\(\textcolor{blue}{ω}\)被称为引导尺度。为了从引导反向过程中进行采样,需要解决以下增强的PF-ODE问题(即与\(\textcolor{blue}{ω}\)相关的项)。

同样的,我们可以引入增强的一致性函数\(\textcolor{blue}{f_\theta(z_t,w,c,t)→ z_0}\)直接预测增强的PF-ODE在\(\textcolor{blue}{t=0}\) 时的解。用于满足该函数两个性质的\(\textcolor{blue}{f_\theta}\)参数化方式和损失函数都与上一节的形式相同,只不过是将\(\textcolor{blue}{\tilde{\epsilon}_\theta(z,c,t)}\)替换为\(\textcolor{blue}{\tilde{\epsilon}_\theta(z,w,c,t)}\),另外还包含用于对\(\textcolor{blue}{w}\)进行条件化的额外可训练参数。

其中,\(\textcolor{blue}{w}\)和\(\textcolor{blue}{n}\)分别从区间\(\textcolor{blue}{[w_{min},w_{max}]}\)以及\(\textcolor{blue}{[1,...,N-1]}\)均匀采样得到。\(\textcolor{blue}{z^{Ψ,w}_{t_n}}\)使用新的噪声模型进行估计:

3. 跳跃式时间步加速蒸馏
在上面的介绍当中,我们知道一致性损失尝试将 LCM 模型\(\textcolor{blue}{f_\theta(z_{t_{n+1}},c,t_{n+1})}\) 的预测与后续步骤中的预测\(\textcolor{blue}{f_\theta(z_{t_{n}},c,t_{n})}\) 沿着相同的轨迹对齐。由于\(\textcolor{blue}{t_{n+1},t_n}\)这两步非常接近,因此 \(\textcolor{blue}{z_{t_{n}}}\)和\(\textcolor{blue}{z_{t_{n+1}}}\)。因此 \(\textcolor{blue}{f_\theta(z_{t_{n+1}},c,t_{n+1})}\) 和\(\textcolor{blue}{f_\theta(z_{t_{n}},c,t_{n})}\)也彼此接近,从而产生小的一致性损失从而导致收敛缓慢。为了解决这个问题,作者引入了SKIPPING-STEP方法可以极大的增加收敛速度,同时几乎不影响指标。
与传统的一致性模型(确保相邻时间步\(\textcolor{blue}{t_{n+1}}\)和\(\textcolor{blue}{t_{n}}\)之间的一致性)不同,LCM旨在确保当前时间步\(\textcolor{blue}{t_{n}}\)和k步\(\textcolor{blue}{t_{n+k}}\)之间的一致性。
注意:设置 k=1 会减少到原始调度,导致收敛缓慢,并且非常大的 k 可能会导致 ODE 求解器出现较大的近似误差。在作者后续的主要实验中,设置k=20
由此,一致性蒸馏损失就可以修改成:

其中,\(\textcolor{blue}{z^{Ψ,w}_{t_n}}\)是使用数值增强 PF-ODE 求解器\(\textcolor{blue}{Ψ}\)对\(\textcolor{blue}{z_{t_{n}}}\)的估计:

在算法 1 中提出了采用 CFG 和 SKIPPING-STEP 技术的 LCD 伪代码。对原始一致性蒸馏 (CD) 算法的修改以蓝色突出显示。

1️⃣采样当前一次训练所需要的数据: 从数据集中采样的样本变为了\(\textcolor{blue}{(z,c)}\),即图片 latent 与图片 caption。SD 加噪过程共有\(\textcolor{blue}{(N=1000)}\)步,从\(\textcolor{blue}{[1,N−k]}\)这区间中采样当前训练所针对的 timestep \(\textcolor{blue}{n}\)。最后从\(\textcolor{blue}{[w_{min},w_{max}]}\)中选择一个\(\textcolor{blue}{w}\)作为后续预测\(\textcolor{blue}{z^{Ψ,w}_{t_n}}\)时使用的 Guidance Scale;
2️⃣加噪: 用标准的 Diffusion 加噪算法计算\(\textcolor{blue}{z_{t_{n+k}}}\);
3️⃣执行一次Diffusion 去噪过程: 利用\(\textcolor{blue}{z_{t_{n+k}}}\)以及PF-ODE 求解器\(\textcolor{blue}{Ψ}\)可以根据公式17,对\(\textcolor{blue}{z^{Ψ,w}_{t_n}}\)进行估计。可以用 DDIM、DPM Sovler++之类熟悉的 Diffusion Scheduler 完成这一步。在这一步的预测中,融合了 CFG 的 Guidance Scale;
4️⃣计算一致性蒸馏损失:上一步得到了一个加噪轨迹上的点,以及其用 Diffusion 去噪算法预测得到的另外一个点。这一步就是分别用当前网络权重以及网络权重的 EMA 计算两个点对应的一致性函数输出,然后用一个损失函数约束输出一致;
5️⃣更新网络权重;
6️⃣计算网络 EMA。
下面展示的是潜在一致性模型的多步采样算法。 LCM 的采样算法与一致性模型中的采样算法非常相似,除了 LCM 中结合了无分类器指导之外。与扩散模型中的多步采样(其中我们从\(\textcolor{blue}{z_{t}}\)预测\(\textcolor{blue}{z_{t+1}}\))不同,潜在一致性模型直接预测增强型 PF-ODE 轨迹的原点\(\textcolor{blue}{z_{0}}\)(增强型 PF-ODE 的解),这一步即可生成样本。

还可以通过交替去噪和噪声注入步骤提高样本质量。特别是,在第\(\textcolor{blue}{n}\)次迭代中,我们首先对先前预测的样本\(\textcolor{blue}{z}\)执行噪声注入前向过程,如\(\textcolor{blue}{\hat{z}_{τ_n}∼N(α(τ_n)z; σ^2(τ_n)I)}\),其中 \(\textcolor{blue}{τ_n}\)是时间步长的递减序列。这相当于从\(\textcolor{blue}{z}\)返回到 PF ODE 轨迹上的点\(\textcolor{blue}{\hat{z}_{τ_n}}\)。然后,我们使用训练后的潜在一致性函数再次执行下一个\(\textcolor{blue}{z_{0}}\)预测。
三、实验
1. 文本到图像生成
💾数据集:实验使用 LAION-5B的两个子集:LAION-Aesthetics-6+ (12M) 和 LAION-Aesthetics-6.5+ (650K) 进行文本到图像生成。在实验当中分别考虑了512×512 和 768×768 的分辨率。对于 512 分辨率,我们使用 LAION-Aesthetics-6+,其中包含 12M 文本-图像对。对于 768 分辨率,我们使用 LAION-Aesthetics-6.5+,其中包含 650K 文本-图像对。
💻模型配置:本文介绍了在512分辨率和768分辨率下使用的模型配置。对于512分辨率,使用了预训练的Stable Diffusion-V2.1-Base模型作为教师模型,该模型最初是在512×512分辨率下使用ϵ-Prediction进行训练的。对于768分辨率,使用了广泛使用的预训练的Stable DiffusionV2.1模型,该模型最初是在768×768分辨率下使用v-Prediction进行训练的。LCM模型进行了10万次迭代训练,512分辨率设置下的批量大小为72,768分辨率设置下的批量大小为16,学习率和EMA率与Song等人的研究保持一致。在增强的PF-ODE求解器\(\textcolor{blue}{Ψ}\)和跳跃步长\(\textcolor{blue}{k}\)的设置上,使用了DDIM-Solver,并将跳跃步长设置为20。指导尺度范围设置为[2, 14]。
📡基线和评估:本文使用DDIM、DPM、DPM++和Guided-Distill作为基线模型,采用FID和CLIP分数评估生成图像的多样性和质量。
📈结果:表1和表2中的定量结果显示,LCM在512和768分辨率下明显优于基准方法,尤其是在低步长范围(1∼4)下,突显了其效率和优越性能。与需要更多峰值内存的DDIM、DPM、DPM++不同,LCM每个采样步骤只需要一次前向传递,节省了时间和内存。此外,与Guided-Distill中采用的两阶段蒸馏过程相比,LCM只需要一阶段引导蒸馏,更简单和实用。

图2中的定性结果进一步展示了LCM在2步和4步推理中的优越性。

2. 消融实验
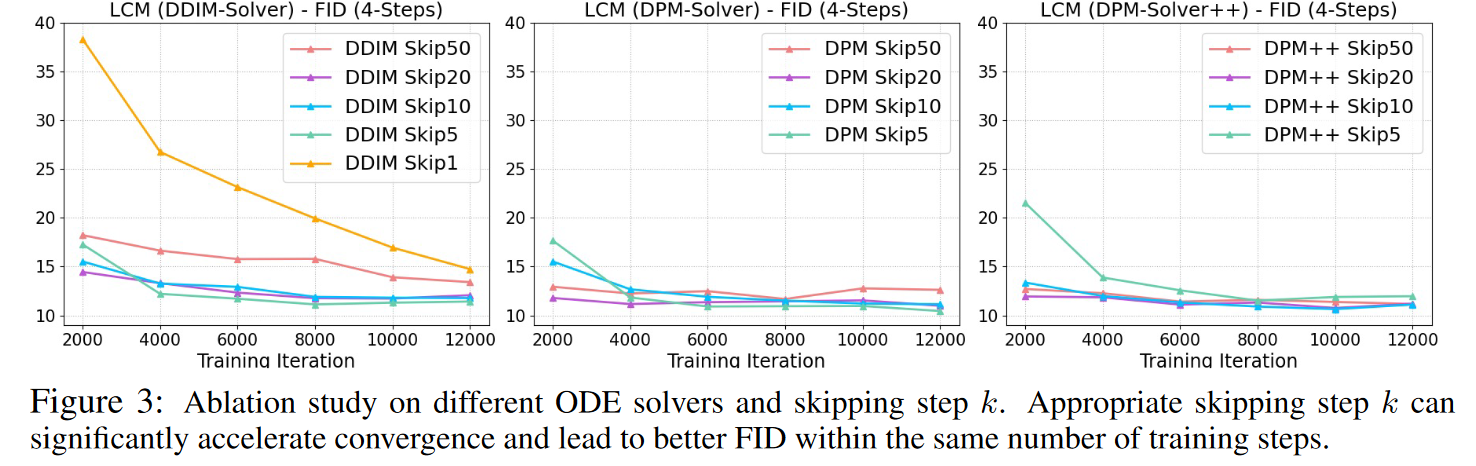
🔴ODE求解器和跳步调度:本文比较了不同ODE求解器在解决增强型PF-ODE问题时的表现,并探索了不同跳步计划。结果表明,跳步技术可以加速收敛,DDIM求解器在k=1时收敛较慢,而k=5、10、20时收敛更快;但是当 k=50 时,FID 也一直很高,说明一下子跳过太多步时,DDIM 解 ODE 的误差太大了。DPM和DPM++求解器在k=50时表现更好;k值过小或过大都会导致收敛缓慢或结果较差,因此我们选择k=20作为主要实验的参数。
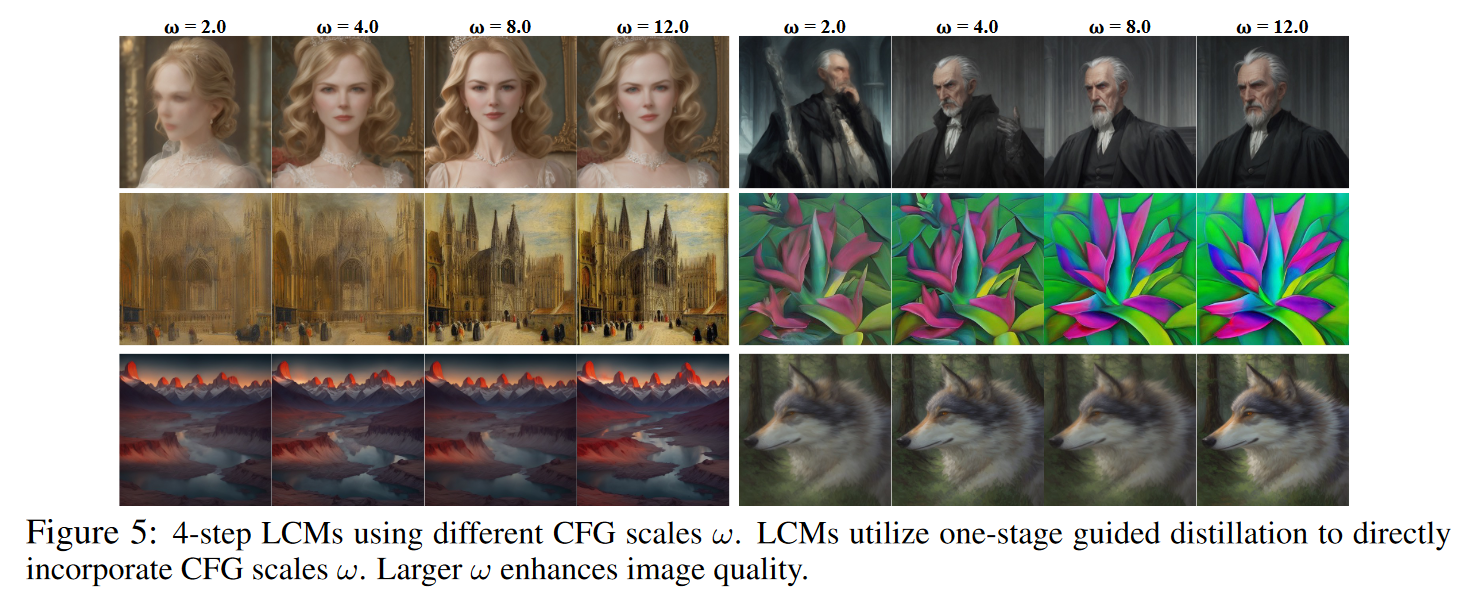
🟠引导效应ω:本文研究了在LCM中使用不同的CFG尺度ω的效果。
图4 显示了不同推理步骤中不同 ω 的结果。结果表明,使用较大的ω可以提高样本质量,但可能会降低样本多样性。LCM 迭代次数为 2、4、8 时,CLIP Score 和 FID 相差都不大,说明了 LCM 的蒸馏性能确实非常强悍,两步前向的效果可能都足够好了,只是一步前向的结果还差些。

在图 5 中展示了不同 ω 的可视化效果。可以清楚地看到,较大的 ω 提高了样品质量,验证了单阶段引导蒸馏方法的有效性。
四、总结
本文提出了潜在一致性模型 (LCM) 和一种高效的单阶段引导蒸馏方法,可以对预训练的 LDM 进行几步甚至一步推理。 LAION-5B-Aesthetics 数据集上的大量实验证明了 LCM 的卓越性能和效率。未来的工作包括将我们的方法扩展到更多图像生成任务,例如文本引导的图像编辑、修复和超分辨率。