
一、简要
本文探索了利用视频进行无监督学习的另一个潜在原理:预测未来图像帧。为了能够预测视觉世界将如何随时间变化,智能体必须至少具有一些对象结构的隐式模型以及对象可能经历的转换。为此,作者设计了一种神经网络架构,并非正式地将其称为“PredNet”,它尝试使用具有自下而上和自上而下连接的深度循环卷积网络来持续预测未来视频帧的出现。作者从神经科学文献中的“预测编码” 获得了特别的启发。预测编码假设大脑不断地预测传入的感官刺激。自上而下的连接传达这些预测,将其与实际观察结果进行比较以生成误差信号。然后误差信号向上传播回层次结构,最终导致预测的更新。
预测编码:是一种大脑功能理论,该理论认为大脑会不断地产生并更新环境的心理模型,预测感觉输入,并与实际感觉输入比较,产生预测误差,进而将这种误差用于更新和修正心理模型。
本文贡献:
1️⃣本文证明了PredNet模型对两种合成序列的有效性,在这两种序列中,可以访问底层的生成模型,并可以研究模型学习到的内容,以及自然视频。
2️⃣与预测需要对象结构知识的观点一致,实验表明这些网络成功地学习了内部表示,这些内部表示非常适合后续识别和解码潜在对象参数(如身份、视图、旋转速度等)。
3️⃣本文架构可以有效地扩展到自然图像序列,通过使用车载摄像机视频进行训练。该网络能够成功地学习预测相机的运动和相机视图中对象的运动。再次支持预测作为无监督学习规则的概念,该模型在该设置中的学习表示支持对当前转向角的解码。
二、PredNet model
1.网络架构👨🏫
PredNet是一个利用神经生物学中的预测性编码(Predictive Coding)原理所构建的视频预测模型,预测过程自顶向下,感知过程自底向上。
PredNet网络由一系列重复堆叠的模块组成,这些模块尝试对模块的输入进行本地预测,然后从实际输入中减去该预测并传递到下一层。PredNet模型架构如下图所示:
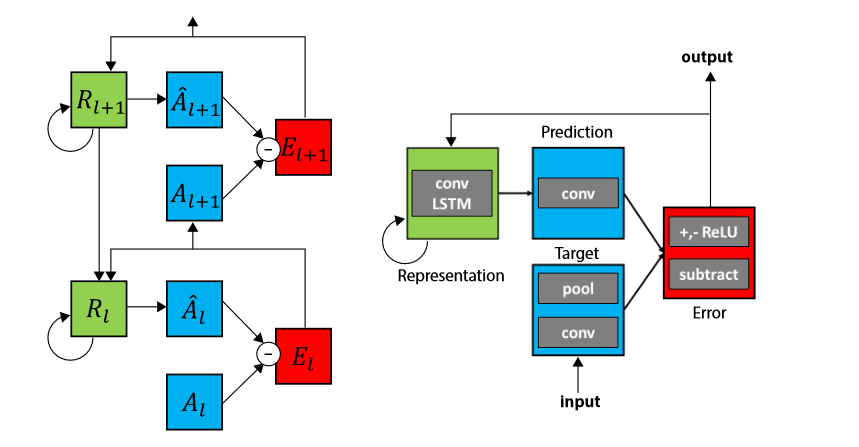
该网络的每个模块由四个基本部分组成:输入卷积层(\(\textcolor{blue}{A_l}\))、循环表示层(\(\textcolor{blue}{R_l}\))、预测层(\(\textcolor{blue}{\hat{A}_l}\))和误差表示层(\(\textcolor{blue}{E_l}\))。
1️⃣循环表示层\(\textcolor{blue}{R_l}\)是一个循环卷积网络,它产生预测\(\textcolor{blue}{\hat{A}_l}\)。网络计算 \(\textcolor{blue}{A_l}\)和 \(\textcolor{blue}{\hat{A}_l}\)之间的差异并输出一个误差表示\(\textcolor{blue}{E_l}\),该误差表示被分成单独的校正正误差总体和负误差总体。
2️⃣然后误差\(\textcolor{blue}{E_l}\)通过卷积层向前传递,成为下一层 \(\textcolor{blue}{A_{l+1}}\)的输入。循环预测层\(\textcolor{blue}{R_l}\)有三个输入,分别是上一帧的接收误差信号\(\textcolor{blue}{E_l}\)的副本,上一帧的表示层\(\textcolor{blue}{R_{l}}\)以及下一层的表示层\(\textcolor{blue}{R_{l+1}}\)。
网络的组织方式是这样的:在操作的第一个步骤中,网络的“右”侧(\(\textcolor{blue}{A_l}\)和 \(\textcolor{blue}{E_l}\))相当于标准的深度卷积网络。同时,网络的“左侧”(\(\textcolor{blue}{R_l}\))相当于每个阶段都有局部递归的生成反卷积网络,并使用梯度下降进行端到端训练。
2.模块更新👩🔬
PredNet架构适用于各种建模的数据,但本文重点关注的是图像序列(视频)数据。
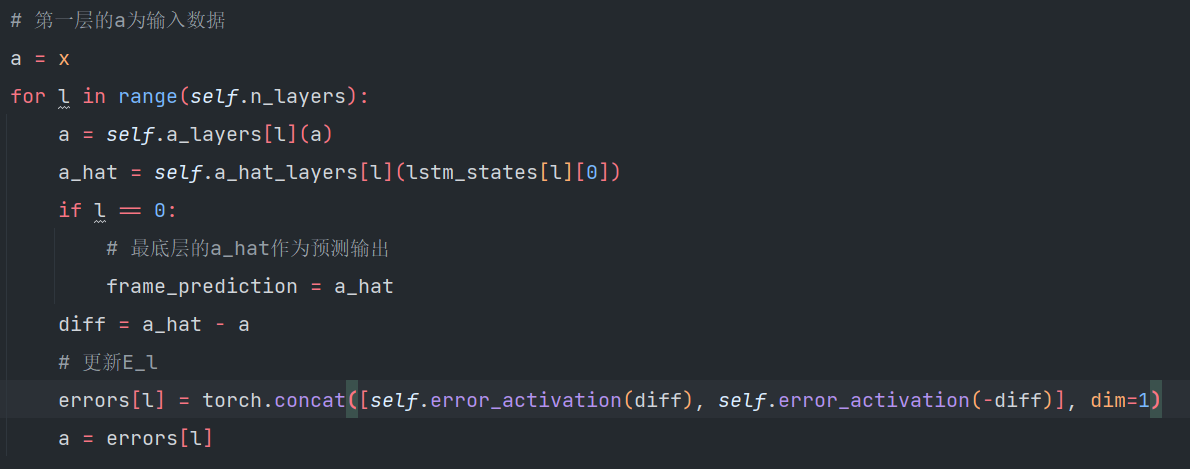
1️⃣考虑图像序列 \(\textcolor{blue}{x_t}\),当layer=0时,最低层的目标设置为实际序列本身,即 \(\textcolor{blue}{A^t_0 = x_t ∀t}\)。当layers>0时,较高层的目标\(\textcolor{blue}{A^t_l(l > 0)}\)通过对下层的误差单元 \(\textcolor{blue}{E^t_{l−1}}\) 进行卷积计算,然后进行修正线性单元 (ReLU) 激活和最大池化(Max pooling)。
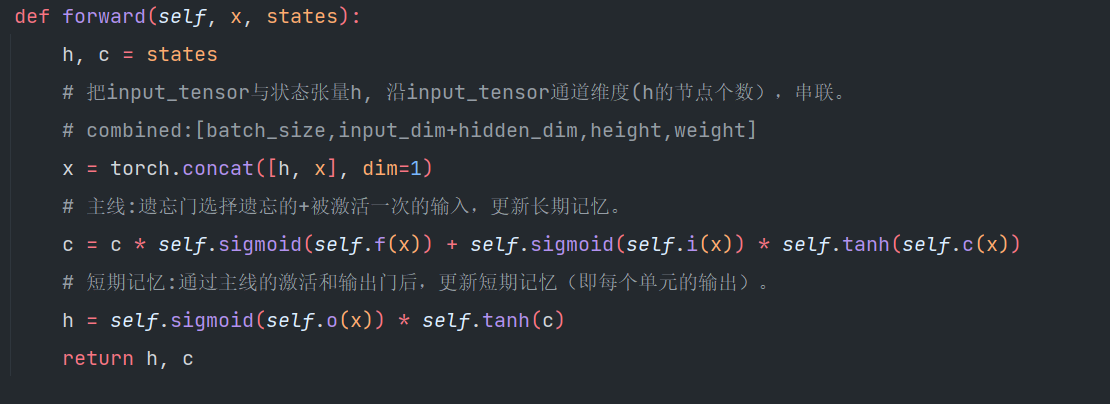
2️⃣循环表示层(\(\textcolor{blue}{R_l}\))使用 LSTM 作为表示神经元。\(\textcolor{blue}{R^t_l}\) 隐藏状态根据 \(\textcolor{blue}{R^{t−1}_l}\)、 \(\textcolor{blue}{E^{t−1}_l}\)以及 \(\textcolor{blue}{R^t_{l+1}}\)进行更新。
3️⃣预测\(\textcolor{blue}{\hat{A}^t_l}\)是通过\(\textcolor{blue}{R^t_l}\)层的卷积和 ReLU 非线性进行的。对于最低层,\(\textcolor{blue}{A^t_l}\)还通过最大像素值处的饱和非线性集:
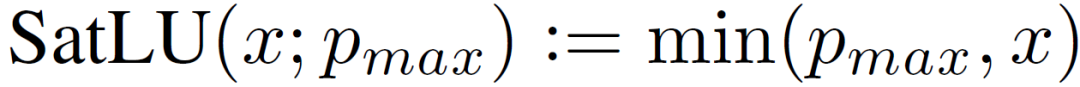
4️⃣最后,误差响应\(\textcolor{blue}{E^t_l}\)是根据\(\textcolor{blue}{\hat{A}^t_l}\)和\(\textcolor{blue}{A^t_l}\) 之间的差异计算的,并分为 ReLU 激活的正预测误差和负预测误差,它们沿特征维度串联。完整的更新公式如下:

该模型经过训练,可以最小化误差单元活动的加权和。训练损失为:
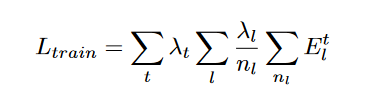
加权因子为时间\(\textcolor{blue}{λ_t}\)和层\(\textcolor{blue}{λ_l}\),其中\(\textcolor{blue}{n_l}\)是第\(\textcolor{blue}{l}\)层中的单元数量。对于由减法和ReLU激活组成的误差单元,每层的损失相当于 L1 误差。
3.算法流程👨🌾
算法 1 中描述了上述该模型的实现流程。状态更新通过两个过程进行:一个自上而下的过程,其中计算\(\textcolor{blue}{R^t_l}\)状态,然后一个向前的过程,以计算预测、误差和更高级别的目标。最后一个值得注意的细节是\(\textcolor{blue}{E^0_l}\)和\(\textcolor{blue}{R^0_l}\)被初始化为零,这是由于网络的卷积性质,意味着初始预测在空间上是一致的。

1️⃣从输入数据中获取当前时间步的数据:\(\textcolor{blue}{A^t_0}\);注:输入数据是个五维数据(t,batch_size,c,w,h)
2️⃣当t=0时,每一层的\(\textcolor{blue}{E^0_l}\)和\(\textcolor{blue}{R^0_l}\)都初始化为0;其中\(\textcolor{blue}{R^0_l}\)包括隐藏状态\(\textcolor{blue}{h^0_l}\)以及\(\textcolor{blue}{c^0_l}\)
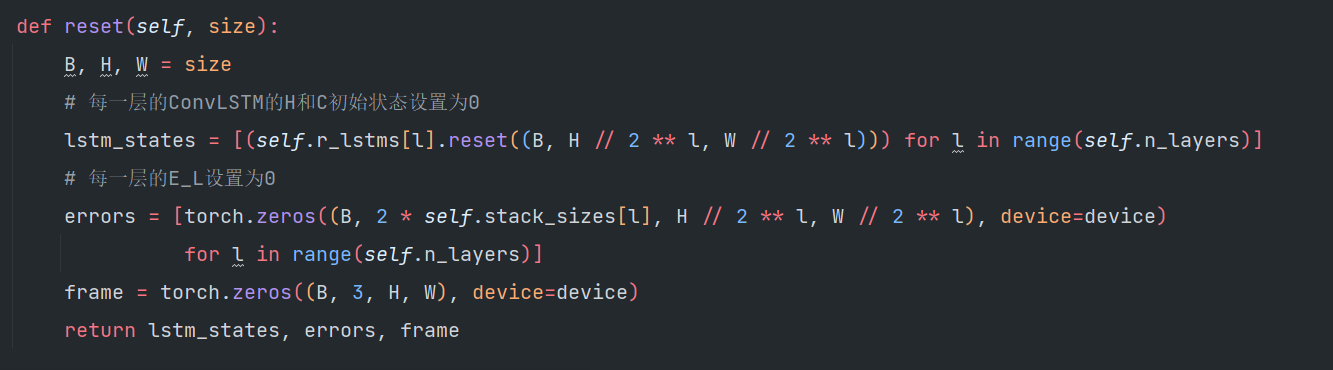

3️⃣在第一层循环下\(\textcolor{blue}{t}\)从1到T,接到第二层循环\(\textcolor{blue}{l}\)从最后一层(L)到0;这一层循环主要是为了更新当前t时刻,每一层\(\textcolor{blue}{R^t_l}\)的隐藏状态。
4️⃣如果当前是最后一层(L),则将上一个时刻的最后一层的\(\textcolor{blue}{E^{t-1}_l}\)和\(\textcolor{blue}{R^{t-1}_l}\)送到ConvLSTM网络当中,如果当前\(\textcolor{blue}{t=1}\)的时候,都初始化为全0矩阵。
5️⃣如果不是最后一层,则将\(\textcolor{blue}{R^t_{l+1}}\)的隐藏状态进行上采样,然后再和\(\textcolor{blue}{E^{t-1}_l}\),\(\textcolor{blue}{R^{t-1}_l}\)的结果拼接起来,并将拼接结果作为输入。经过ConvLSTM后得到更新后的\(\textcolor{blue}{R^{t}_l}\)的隐藏状态。
6️⃣在第一个第二层循环结束以后,进入到第二个第二层循环当中,该层循环是为了更新每一层的\(\textcolor{blue}{\hat{A}^t_l}\),\(\textcolor{blue}{A^t_l}\),\(\textcolor{blue}{E^t_l}\)状态
7️⃣如果l=0时,\(\textcolor{blue}{\hat{A}^t_0}\)要额外通过SatLU激活函数。

8️⃣计算正差值和负差值,分别为\(\textcolor{blue}{\hat{A}^t_l}\)与\(\textcolor{blue}{A^t_l}\)之间的差值和\(\textcolor{blue}{A^t_l}\)与\(\textcolor{blue}{\hat{A}^t_l}\)之间的差值,并更新\(\textcolor{blue}{E^t_l}\)状态。
9️⃣如果当前层小于L,则使用误差\(\textcolor{blue}{E^t_l}\)更新\(\textcolor{blue}{A^t_l}\)
三、实验
1.渲染图像序列🐒
🚀实验设置1:作者创建了沿“平移”和“滚动”轴以两个自由度旋转的渲染面序列。这些面孔以随机方向开始,并以随机恒定速度旋转,总共 10 帧。每个序列都采样了不同的面孔。图像被处理为灰度,值标准化在 0 和 1 之间,大小为 64x64 像素。本次实验使用 16K 序列进行训练,使用 800 个序列进行验证和测试。
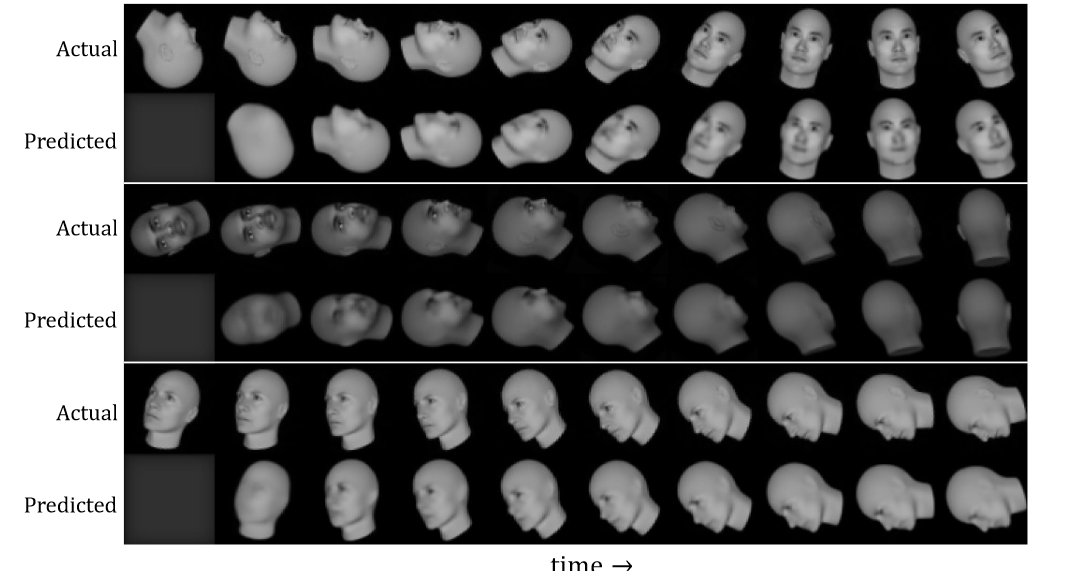
⛄实验结果1:PredNet 模型生成的预测如图所示。该实验表明:PredNet模型能够随着时间的推移积累信息,以便对未来帧做出准确的预测。由于表示神经元被初始化为零,因此第一个时间步的预测是均匀的像素。在第二个时间步长中,还没有运动信息,预测是第一个时间步长的模糊重建。经过进一步迭代后,模型适应底层动态,生成与输入帧紧密匹配的预测。
⛄实验结果2:将 PredNet 与复制最后一帧(Copy Last Frame)的简单解决方案以及共享 PredNet 整体架构和训练方案的CNN-LSTM Enc.-Dnc.模型进行比较。表 1 总结了旋转面部(rotating faces)数据集上所有模型的性能,其中得分计算为第一帧后所有预测的平均值。其中,仅在最低层使用损失训练的 PredNet 模型的结果,表示为 PredNet \(L_0\),以及在上层使用 0.1 权重训练的模型,表示为 PredNet \(L_{all}\)。

⛄实验结果3:平移(\(\alpha_{pan}\))和滚动(\(\alpha_{roll}\))速度、平移初始角度(\(\theta_{pan}\))和PC-1的潜在变量解码精度,如下图的左侧面板所示。首先,经过训练的模型通常比随机初始化的模型(PredNet-Init)能够更好地对潜在变量进行线性解码,其中最明显的是平移旋转速度(\(\alpha_{pan}\))。其次,\(L_{all}\) 和 \(L_0\) 之间最显着的差异发生在PC-1上,其中在所有层上使用损失训练的模型(PredNet \(L_0\))比仅在最低层上使用损失训练的模型(PredNet \(L_{all}\))具有更高的解码精度。
 🚀实验设置2:最后,作者为了表明模型学习到的潜在变量表示可以很好的推广到未明确训练的其他任务上。在静态人脸分类任务中评估模型,将
PredNet
与standard
autoencoder和梯形网络的变体(Ladder
Network Variant)进行比较。这两个模型的构建都具有与 PredNet
相同的层数和通道大小,以及类似的交替卷积/最大池,然后上采样/卷积方案。由于这两个网络都是自动编码器,因此它们都经过重建损失训练,数据集由用于训练
PredNet 的序列中的所有单独帧组成。对于
PredNet,使用表示单元并在处理一个输入帧后提取特征。
🚀实验设置2:最后,作者为了表明模型学习到的潜在变量表示可以很好的推广到未明确训练的其他任务上。在静态人脸分类任务中评估模型,将
PredNet
与standard
autoencoder和梯形网络的变体(Ladder
Network Variant)进行比较。这两个模型的构建都具有与 PredNet
相同的层数和通道大小,以及类似的交替卷积/最大池,然后上采样/卷积方案。由于这两个网络都是自动编码器,因此它们都经过重建损失训练,数据集由用于训练
PredNet 的序列中的所有单独帧组成。对于
PredNet,使用表示单元并在处理一个输入帧后提取特征。
⛄实验结果4:如上图的右侧面板显示了使用\(L_{all}\) 和 \(L_0\) PredNets、标准自动编码器和梯形网络变体所学习到的潜在表示的人脸分类精度。其中\(L_{all}\) 和 \(L_0\) PredNets 都优于其他模型,这表明他们学习到一种对目标转换相对宽容的表示。与第一主成分的解码精度类似,PredNet \(L_{all}\) 模型实际上优于 \(L_0\) 变体。总而言之,这些结果表明,使用 PredNet 进行预测训练可以成为使用更传统的重建或去噪损失训练的其他模型的可行替代方案。
2.自然图像序列🐧
⛅实验设置1:接下来,作者在复杂的真实序列上测试 PredNet 架构。他们选择了车载摄像头视频,因为这些视频具有丰富的时间动态特征,包括车辆的自身运动和场景中其他物体的运动。使用 KITTI 数据集中的原始视频对模型进行训练,这些视频是由在德国城市环境中行驶的汽车上的车顶摄像头拍摄的。训练集总共包含大约 41K 帧。为了评估网络确实学到了稳健的表征,作者在加州理工学院的行人数据集上进行了测试,该数据集由在洛杉矶行驶的车辆上仪表板安装的摄像头拍摄的视频组成。对整个加州理工学院测试分区进行定量评估,分为 10 个帧的序列。
🌨实验结果1:下图显示了 CalTech 行人数据集上的示例 PredNet 预测(针对 L0 模型)。该模型能够在各种场景下做出相当准确的预测。在图中的顶部序列中,一辆汽车朝相反方向驶过,该模型虽然并不完美,但能够预测其轨迹,并填充其留下的地面。类似地,在序列 3 中,模型能够预测车辆完成左转的运动。序列 2 和 5 说明 PredNet 可以判断自己的运动,因为它可以预测阴影和静止车辆接近时的出现。即使在困难的情况下,例如当安装摄像头的车辆转弯时,该模型也能做出合理的预测。在序列 4 中,当车辆转向道路时,模型预测树的位置。转动序列还进一步说明了模型的“填充”能力,因为它能够在看不见的区域进入视野时推断出天空和树木的纹理。

作为附加控制,下图显示了一个序列,其中输入已被暂时扰乱。在这种情况下,模型会生成模糊帧,这些帧大多与前一帧相似。最后,虽然此处显示的 PredNet 经过训练以预测前方一帧,但也可以通过将预测反馈为输入并递归迭代来预测未来的多个帧。

🌨实验结果2:如表2所示,PredNet 模型再次优于 CNN-LSTM EncoderDecoder。为了确保性能差异不仅仅是因为超参数的选择,我们使用其他四组超参数训练模型,这些超参数是从层数、滤波器大小和每层滤波器数量的初始随机搜索中采样的。
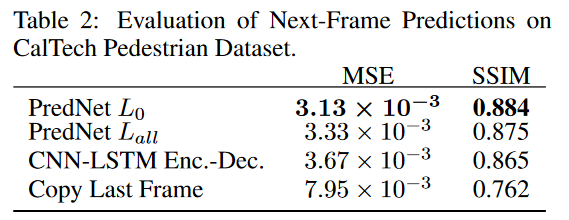
⛅实验设置2:表 3 包含在 KITTI 上训练后在加州理工学院行人数据集上评估的 PredNet 和 CNN-LSTM 编码器-解码器的其他变体的结果。我们根据像素预测来评估模型,因此使用仅在最低层(PredNet \(L_0\))上经过损失训练的 PredNet 模型作为基础模型。除了均方误差 (MSE) 和结构相似性指数测量 (SSIM) 之外,我们还计算峰值信噪比 (PSNR)。**对于每个模型,我们使用原始的超参数集(控制层数、滤波器大小和每层滤波器的数量)以及从初始随机搜索中随机采样的四组附加超参数对其进行评估。以下是附加控制模型的说明:
1️⃣PredNet(no E split):使用基本的PredNet 模型,除了误差响应 (\(E_l\)) 是简单的线性 (\(\hat{A}_l − A_l\)),而不是分为正校正和负校正。
2️⃣CNN-LSTM Enc.-Dec.(2x \(A_l\) filts):CNN-LSTM 编码器-解码器模型(通过 \(A_l\) 代替 \(E_l\)),但\(A_l\)中的滤波器数量加倍。与 PredNet 相比,这控制了模型中的滤波器总数,因为 PredNet 具有在每一层产生 \(\hat{A}_l\)的滤波器,该滤波器被集成到模型的前馈响应中。
3️⃣CNN-LSTM Enc.-Dec.(except pass \(E_0\)):CNN-LSTM Encoder-Decoder 模型,但误差在最低层传递。所有剩余层都通过激活 Al。由于仅在最低层进行训练损失,这种变化使我们能够确定上层的“预测”减法运算(在 \(L_0\) 情况下本质上不受约束且可学习)是否有助于模型的性能。
4️⃣CNN-LSTM Enc.-Dec.(+/- split):CNN-LSTM 编码器-解码器模型,除了激活 \(A_l\) 之外,在传递到网络中的其他层之前被分成正群体和负群体。这隔离了该过程引入的额外非线性的影响。
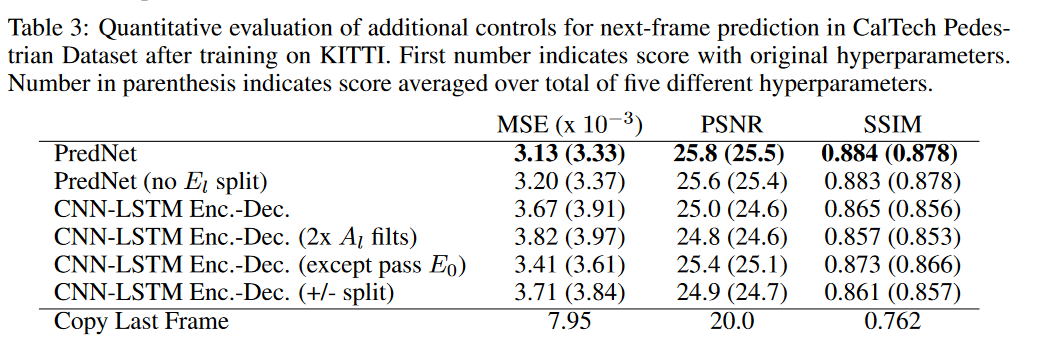
🌨实验结果3:简而言之,这些结果表明 PredNet 的错误传递操作可以提高下一帧预测性能。
⛅实验设置3:为了测试模型中在KITTI数据集中潜在参数的隐式编码,作者使用 PredNet 中的内部表示来估计汽车的转向角。使用了 Comma.ai 发布的数据集,该数据集包含 11 个视频,总计约 7 小时,主要是高速公路驾驶。首先训练网络进行下一帧预测,然后在学习到的表示上拟合线性全连接层,以使用 MSE 损失来估计转向角。我们再次连接所有层的 \(R_l\) 表示,但首先在空间上平均池化下层以匹配上层的空间大小,以降低维度。使用第 10 个时间步长的表示的转向角估计结果如图下所示(左:转向角曲线示例以及测试集中某个路段的模型估计。右:转向角估计的均方误差)。

🌨实验结果4:仅给定 1K 个标记训练示例,PredNet \(L_0\) 表示上的简单线性读数解释了转向角中 74% 的方差,并且优于 CNN -LSTM Enc.-Dec.35%。通过 25K 个标记训练样本,PredNet \(L_0\) 的 MSE为 2.14。有趣的是,在这个任务中,PredNet \(L_{all}\) 模型的MSE分数实际上低于 \(L_0\) 模型,并且略低于 CNN-LSTM Enc.-Dec.,再次表明 \(λ_l\)参数可以影响学习到的表示,并且在不同的最终任务中可能会优选不同的值。总体而言,该分析再次证明,通过预测学习的表示,尤其是具有适当超参数的 PredNet 模型,可以包含有关底层潜在参数的有用信息。
⛅实验设置4:在图 8 中,我们展示了使用 PredNet \(L_0\) 模型学习到的表示,它在 Comma.ai数据集上的转向角估计精度与输入到模型中的帧数的关系曲线。 PredNet 在所有层的表示都是串联的(在空间上将较低层池化到共同的空间分辨率之后),并且使用 MSE 拟合全连接的读数。对于每个级别的训练示例数量,我们平均进行 10 次以上的交叉验证分割。为了作为参考点,设置了两个静态模型的结果。第一个模型是一个自动编码器,通过适当匹配的超参数进行单帧重建训练。全连接层适合自动编码器的表示,以与 PredNet 相同的方式估计转向角。第二个模型是发布的 Comma.ai 代码中的默认模型 ,它是一个五层 CNN。该模型经过端到端训练来估计给定当前帧作为输入的转向角,带有 MSE 损失。除了 25K 示例之外,我们还使用 Comma 数据集(约 396K)中的所有帧训练了一个版本。对于所有模型,最终权重都是在训练期间以最小验证误差选择的。鉴于与每个视频的平均持续时间相比,数据集中的视频数量相对较少,我们使用每个视频的 5% 进行验证和测试,选择作为随机连续块,并丢弃所选片段之前和之后的 10 帧训练集。
🌨实验结果5:如下图所示,正如人们所期望的那样,随着时间的推移,PredNet 的性能会变得更好,因为该模型能够积累更多信息。有趣的是,在与没有动态的 PredNet 训练过程正交的机制中,它仅在一个时间步后就表现得相当好。总而言之,这些结果再次表明该模型在学习潜在参数方面的有用性。

🌨实验结果6:图 9 和图 10 比较了 PredNet \(L_{all}\) 模型的下一帧预测,该模型在所有层上都使用预测损失进行训练(\(λ_0 = 1\),\(λ_l>0 = 0.1\)),而 PredNet \(L_0\)模型则仅在最低层上使用损失进行训练。乍一看,这两者在上面的实验中,表现出预测的差异似乎相当小,然而,经过仔细检查,很明显 \(L_{all}\) 预测缺乏$ L_0 $预测的一些更精细的细节,并且在高方差区域更加模糊。例如,对于旋转的脸部,面部特征不太清晰,而对于加州理工学院,接近的阴影和汽车的细节不太精确。
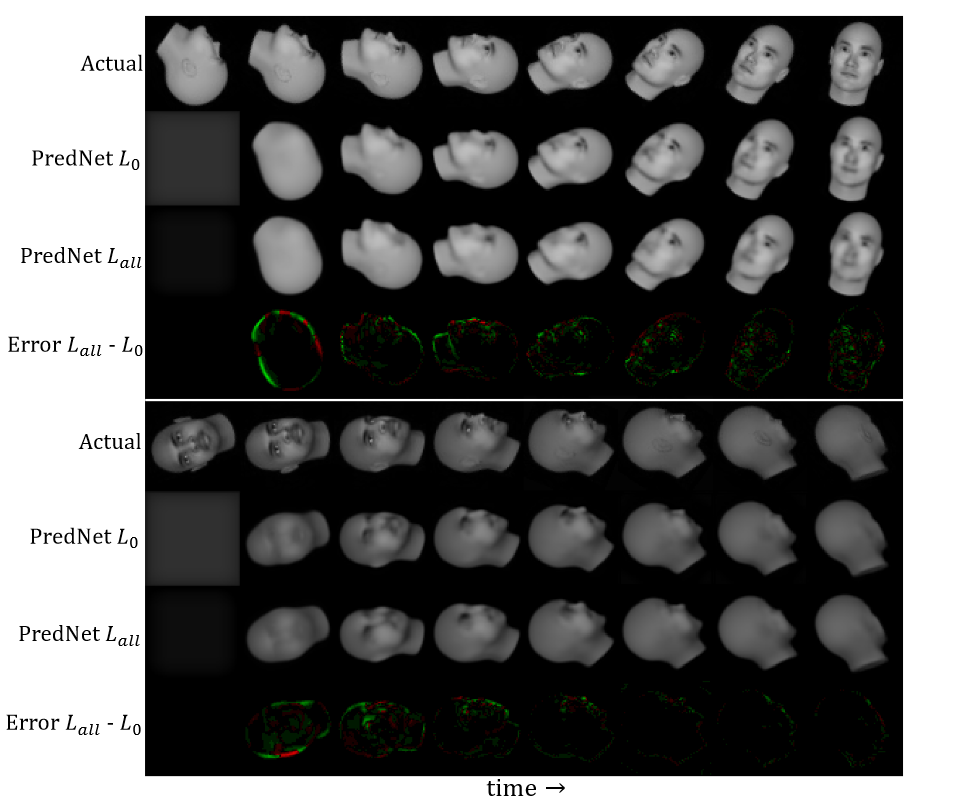
“Error \(L_{all} − L_0\)”可视化显示 \(L_0\) 模型的像素误差小于 \(L_{all}\) 模型的像素误差。绿色区域对应于 \(L_0\) 较好的区域,红色区域对应于 \(L_{all}\) 较好的区域。

四、总结
本文受预测编码启发提出了一个名为PredNet的网络架构,它能够预测合成图像序列和自然图像序列中的未来帧。本文已经证明了,学习预测物体或场景在未来帧中的移动方式,在解码引起物体外观变化的潜在参数(如视角)方面具有优势,并可以提高识别性能。更一般地说,我们认为预测可以作为强大的无监督学习信号,因为准确预测未来帧至少需要构成场景的对象以及它们如何移动的隐式模型。更深入地理解网络所学习的表示的本质,并通过允许采样等方式扩展架构,是未来的重要方向。