
《Synthesizing Contrast-enhanced Computed Tomography Images with an Improved Conditional Generative Adversarial Network》
一、前言
1.CE-CT图像概述以及局限
目前在临床实践中广泛应用的是对比增强计算机断层扫描CT(CE-CT)图像做临床诊断,例如肝癌。
CE-CT也称多时相CT图像,它是由身体注入造影剂,再进行CT扫描所获得的。
注射前的CT图像(NC-CT)一般也称作平扫图像,它是无需注射造影剂的CT扫描。
注射造影剂后获得CE-CT图像,可分为三个阶段:动脉期(ART)、门静脉期(PV)和延迟期(DL)。
简单的来说,不同类型的肝癌的肝脏局灶性病变(FLL)在平扫图像看,看不出什么区别。然而,它们在 ART 和 PV 阶段就能够表现出明显不同的视觉特征,这是放射科医生鉴别肝癌的主要标准。
虽然CE-CT图像对肝癌的诊断有效,但由于造影剂注射和长时间成像,获得CE-CT图像会增加患者的身体负担。
因此,本文的目标就是从 NC 图像合成不同阶段的 CE-CT 图像来解决上述问题。
2.GAN
现有的生成模型有两个缺陷:
第一:卷积神经网络(CNN)的感受野与其理论大小不一致,导致其捕获全局信息的性能较差。
第二:在解码过程中,语义特征由深层向浅层传递,这不可避免地会导致信息丢失。
为了解决上述缺点,作者提出了一种改进的条件生成对抗网络(改进的cGAN)并将其应用于合成高质量的CE-CT图像。更具体地说,为了解决第一个缺点,首先在图像合成任务中引入金字塔池模块(PPM),以提高编码器捕获全局信息的能力。
除此之外,作者构建了一系列信息流路径(IFP)来连接PPM的输出和每个解码器单元,这可以有效防止解码过程中的信息稀释。此外,为了使解码器有效地集成不同的特征(即从PPM、先前的解码器单元和相应的编码器单元中提取的高级、中级和低级语义信息),我们设计了一种新颖的特征融合模块(FFM)。本文主要的贡献如下:
1)提出了一种新颖的图像合成框架,它可以从 NC图像自动合成 ART 和 PV 阶段的 CE-CT 图像。
2)新设计的生成模型在 PPM、IFP 和 FFM 的帮助下,能够有效捕获全局和局部语义信息,并防止解码层中的信息稀释。
二、方法
1.架构
首先,让\(x_i\in X\)和\(y_i\in Y\)分别表示源域图像(NC)和目标域图像(ART或PV阶段的CE-CT图像)当中的训练图像。对于源域中给定的输入图像 x,提出的改进 cGAN 旨在合成 CE-CT 图像 \(\hat{y}\),该图像应尽可能与真实的 CE-CT 图像 y 相似。所提出的改进cGAN由两个模型组成:鉴别器D和生成器G。生成器G以NC图像作为输入并生成相应的CE-CT图像。鉴别器 D 学习区分其输入的类型:真实的或合成的 CE-CT 图像如图1所示:

首先,NC图像输入到编码器,编码器的前四层是在 ImageNet 训练集上预训练的 ResNet,之后添加了两个卷积层。
编码器的输出将被输入到 PPM 中以形成新的特征向量,该向量将沿着 IFP 传递到解码器中的每个 FFM。
合成的 CE-CT 图像 \(\hat{y}\) 和真实的 CE-CT 图像 y 将一起输入鉴别器 D。生成器 G 的目的是欺骗鉴别器 D。相反,鉴别器 D 试图区分其输入的类型:真实的 CE-CT 图像或合成的 CE-CT 图像。对于生成器G,这个过程可以描述如下:

为了稳定训练过程,我们利用带有梯度惩罚的 WGAN 来训练 GAN 的判别器。判别器D的目标函数可以定义为方程2:

\(\hat{x}\)是一个新样本,它是通过输入和合成 CE-CT 图像之间的线性插值生成的
为了保证生成的CE-CT图像\(\hat{y}\)尽可能接近真实的CE-CT图像y,我们采用L1距离作为重建损失,其定义如下:

最后,生成器 G 的目标表述为方程 4:
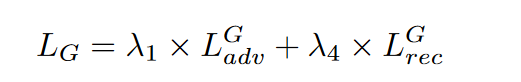
本文中λ1、λ2、λ3、λ4的系数分别为1、1、5、25。生成器 G 和鉴别器 D 尝试分别最小化方程 4 和方程 2。
2.PPM
为了增强编码器捕获不同尺度语义特征的能力,我们将 PPM 引入到跨模态医学图像合成任务中。更具体地说,PPM的概述如图2所示,它可以有效地捕获不同尺度的语义信息。PPM的详细介绍可以参见《Pyramid scene parsing network》
3.FFM
语义特征在解码过程中从解码器的深层传递到浅层,这不可避免地导致特征丢失。为了充分利用语义特征,从 PPM 中提取的特征将沿着 IFP 传递到解码器的每一层。 IFP是一系列具有不同上采样率的上采样层。为了融合不同层次的特征,作者设计了一种新颖的FFM,如图3所示。从 PPM 和之前的解码器单元提取的特征将被馈送到串联层以形成中间特征。中间特征和从编码器单元提取的特征将一起输入注意门以形成最终特征向量。

三、实验
实验中使用的数据集是内部的对比增强CT数据集,并没有向外公开,使用NC-ART图像对和NC-PV图像对分别用于训练两个模型(即ART模型和PV模型),以分别合成ART图像和PV图像。对于测试,仅使用 NC 图像作为输入来合成相应的 CE-CT 图像。
在本文中,结构相似性指数(SSIM)和峰值信噪比(PSNR)用于评估合成图像和真实CE-CT图像之间的差异。为了定量评估合成图像中肿瘤区域的质量,我们计算了估计的CE-CT图像与真实CE-CT图像之间的密度特征的皮尔逊相关系数(PCC),它可以反映合成图像内平均像素密度的比率。病变到肝实质的平均像素密度。
作者将他们所提出的模型与Pix2pix GAN 和 Cycle GAN 在从 NC 图像合成 ART 和 PV 阶段的 CE-CT 图像方面的性能进行了比较。不同的定量结果如下表所展示:
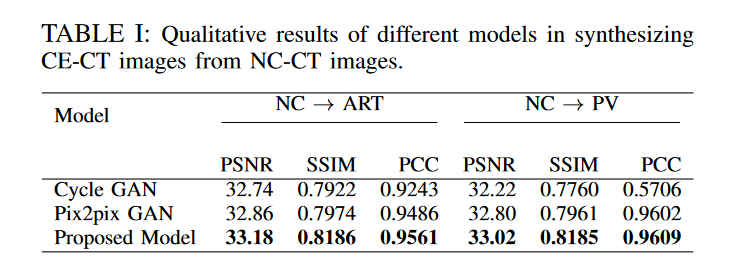
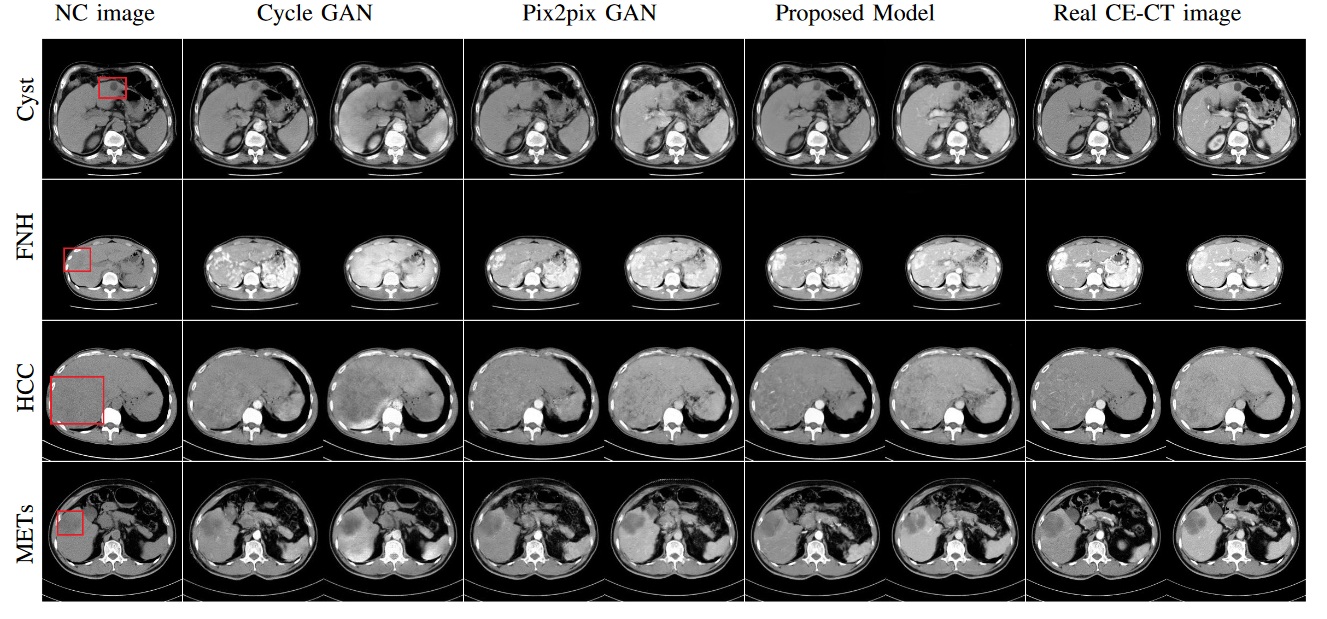
图4显示了不同的定性结果,这表明从所提出的模型生成的CE-CT图像的FFL最接近真实的CE-CT图像。
所提出模型的PCC可视化如图5所示,进一步说明所提出的模型可以学习病变内部平均像素密度与肝实质平均像素密度的比率。

最后,作者进行了消融研究,以测试 PPM、IFP 和提出的 FFM 在合成 CE-CT 图像中的贡献。定量结果如表 2 所示。“模型 1”是我们的基线模型,编码器和解码器之间使用跳跃连接。 “模型2”是我们在编码器和解码器之间添加金字塔池化模块。 “模型3”是我们通过信息流路径在金字塔池化模块和解码器之间添加跳过连接。 “建议模型”是完整模型。定量结果表明,通过引入 PPM、IFP 和提出的 FFM,在 PSNR 和 SSIM 评分方面提高了合成 CE-CT 图像的质量。

《Virtual contrast enhancement for CT scans of abdomen and pelvis》

一、介绍
造影剂通常用于增强图像的诊断测试,例如磁共振成像(MRI)和计算机断层扫描(CT),以突出显示血管、器官和其他结构。然而注射造影剂药物可能会给患者带来高风险。例如初次接触时的过敏反应、药理毒性不良反应、突破性反应、造影剂诱导的肾毒性等等。因此本文尝试采取直接从非造影CT生成虚拟造影增强CT该方案。
但生成虚拟造影增强CT是存在很大的挑战,具体体现在如下几个方面:
1. 增强前和增强后 CT 扫描之间的错位:在临床评估中,每隔一段时间注射造影剂后获得造影后CT图像。姿势运动高度影响重复对比前和对比后增强 CT 对的对齐。在增强前和增强后 CT 对之间观察到两种主要类型的错位。第一种类型是脊状运动,与患者身体在特定方向上的位置移动有关。这种脊状运动可以通过增强的相关系数最大化通过仿射变换来对齐。第二类属于由身体运动(如肠道蠕动)和运动伪影引起的随机呼吸差异。器官位置和方向的变化很难通过图像配准方法来解决。由于基于人工智能的方法是数据驱动的,因此该偏差使任务具有挑战性,特别是在每像素的监督下。
2.腹部和骨盆 CT 扫描的复杂性:腹部和骨盆区域包含比大脑、脊柱和四肢更复杂的器官结构。从非对比域到对比后域的合成,从有限的数据中提取丰富的特征很容易导致模型过度拟合。
本文提出了一种双路径生成对抗网络(GAN),通过保留纹理和增强像素强度,直接从非造影 CT 合成虚拟造影增强 CT。本文的主要贡献概括为以下三个方面:
1️⃣从腹部和骨盆区域的非造影 CT 自动生成动脉期、门静脉期和延迟期的虚拟造影增强 CT 扫描。这是第一个探索所有三个对比阶段的工作。作者收集了腹部和骨盆区域 CT 扫描数据集用于训练和测试,包括临床实践中常用的动脉期、门脉期和延迟期的造影前和造影后 CT。
2️⃣如图 2 所示,本文提出了一种具有高分辨率生成器的基于双路径 GAN 的框架。高分辨率层应用于生成器并跨多分辨率表示交换信息以进行高分辨率图像合成。为了利用重复的对比前和对比后增强 CT 对的错位,与每像素损失相比,应用感知损失来更好地处理错位,这可以学习对比的语义差异通过比较实际和虚拟对比增强 CT 图像之间的高级特征表示来识别区域。
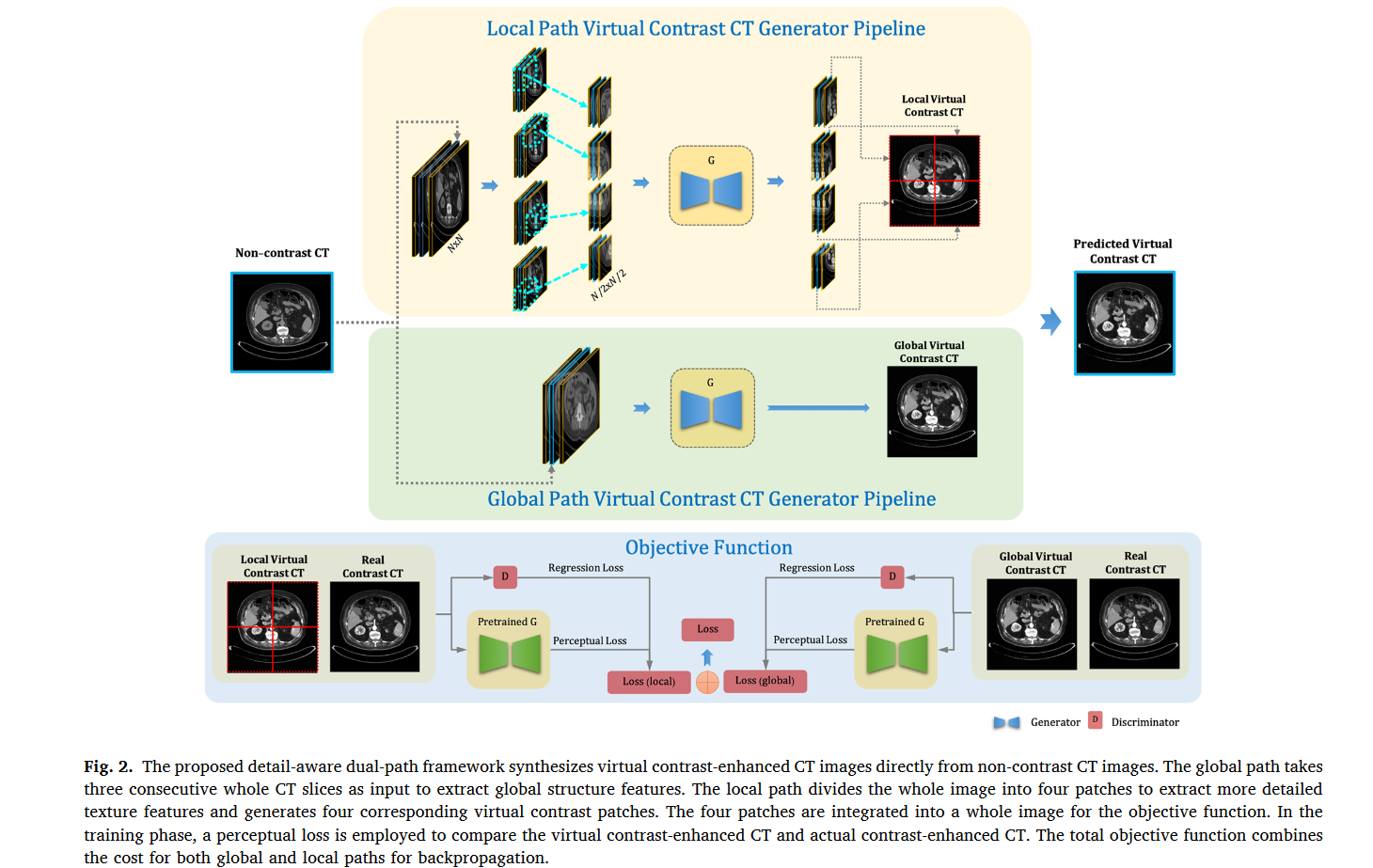
3️⃣为了进一步改进增强细节,作者还设计了一种双路径训练模式,以同时学习全局路径网络的对比度增强区域和局部路径网络的细粒度细节之间的相关性。提出了一种自监督模式,通过采用大型公共国家肺部筛查试验(NLST)数据集(National,2011)来生成具有丰富特征提取的预训练模型,而无需额外注释。预训练模型有助于克服模型在有限数据下的过拟合问题。实验结果证明了直接从非造影 CT 合成虚拟造影增强 CT 的最先进性能。
二、方法
如图2所示,本文提出了一种基于双路径 GAN 的框架,从非造影 CT 生成虚拟造影增强 CT。全局路径以三个连续的 CT 切片作为输入来提取全局结构特征并输出一个虚拟对比 CT 切片,而局部路径则以从 CT 图像中划分出的四个块来提取详细的纹理特征。
1. 虚拟造影CT合成框架
本文遵循条件生成对抗网络(cGAN)来学习从输入图像到输出图像的映射。对于具有轻微像素错位的细粒度对比度 CT 增强,我们的目标是通过结合像素级映射和域自适应来解决该问题。生成器 G 学习非增强 CT 图像 \(\textcolor{blue}{x}\) 和实际对比增强 CT 图像 \(\textcolor{blue}{c}\) 之间的映射。通过根据\(\textcolor{blue}{x}\)预测像素的对比度增强水平来合成虚拟对比度CT \(\textcolor{blue}{c'}\),同时训练鉴别器D以区分实际对比度增强CT图像\(\textcolor{blue}{c}\)和虚拟对比度CT图像\(\textcolor{blue}{c'}\)。
该框架的目标函数如下所示:

其中生成器 G 旨在最小化目标,而判别器 D 则最大化目标。
生成器:生成的增强 CT 需要保留非增强 CT 的结构,并与实际增强 CT 一样突出显示身体结构。 U-net是一个编码器-解码器网络,可用于图像合成。然而,跳跃连接、下采样和最大池化层会导致虚拟对比增强 CT 缺乏细节和过度平滑。因此,作者应用强大的骨干高分辨率网络(HRNet)通过跨多分辨率表示交换信息来保持高分辨率。图 3 显示编码器网络通过多层反向传播来保留高分辨率特征和高语义特征。卷积块 \(\textcolor{blue}{L(i)}\) 与所有先前层 \(\textcolor{blue}{L(i-k)}\) 连接,其中 \(\textcolor{blue}{k}\) 在 \(\textcolor{blue}{(1, i-1)}\) 范围内。

编码器网络包含卷积块 \(\textcolor{blue}{L_d}\),因为 \(\textcolor{blue}{d}\) 指的是 \(\textcolor{blue}{L_d}\) 每个块中的网络深度(即网络层)。当前的卷积层 \(\textcolor{blue}{L_d(i)}\) 集成了先前层的特征。每个卷积块由 2 × 2 最大池化层、3 × 3 内核大小的双卷积层和批量归一化组成,并以整流线性单元(ReLu)作为激活函数。在本文中,实现了五个卷积块。解码器网络采用跳跃连接策略,从高层到低层逐渐组合特征。为了保留非造影 CT 的 CT 图像结构,将输入图像与输出特征图连接起来,然后使用卷积层来优化图像强度级别的权重。
判别器:如图3所示,判别器由以下部分组成:四个卷积(Conv)块,通道大小为(64、128、256、512),特征大小为(256×256、128×128、64×64、32×32)。每个块包含一个 2D Conv 层,后面跟着一个 BatchNorm 层和斜率为 0.2 的 LeakyReLu。 Conv 层将最后一个 Conv 块的特征展平为一维向量。将非造影 CT 域映射到虚拟造影 CT 域可以被视为强度回归任务。通过比较以下两个特征图,应用 MSE 和 BCEwithlogits 损失来优化鉴别器:(1)从输入 CT 中提取的特征图与实际增强 CT 相连接,标记为 1; (2) 从输入 CT 中提取的特征图与虚拟 CT 连接,标记为零。
2. 使用预训练网络的感知损失
预训练模型:提出了一种新颖的自监督训练策略来训练预训练模型,以进行丰富的语义和强度感知特征提取。如图4所示,首先,应用四级图像强度变换。非造影 CT 图像乘以四个强度系数 (α) 级别 [0.5、1.0、1.5、2.0],表示为四个类别 [0、1、2、3]。

其次,引入借口任务训练来对这四个强度级别进行分类。主干网络结构与生成器相同,后面是三个全连接层和一个用于强度级别分类的 Softmax 层。最后,排除最后三个全连接层。应用来自大型公共 NLST 数据集(National,2011)的腹部和骨盆区域 CT 进行训练,无需额外注释。这种预训练模型对强度方差敏感,可以提取丰富的对比度感知特征。损失函数如式(2)所示。

其中,对于输入 CT 切片 \(\textcolor{blue}{c_j}\),通过乘以系数\(\textcolor{blue}{i}\)将其转换为\(\textcolor{blue}{K}\) 个图像强度 \(\textcolor{blue}{I}\) 级别。分类网络 \(\textcolor{blue}{F(⋅ ∣I)}\) 学习强度特征。图像强度变换 \(\textcolor{blue}{G(c_j∣I)}\) 将输入 CT 变换为四个图像强度级别。
感知损失:在图像风格转换中非常流行,它通过在特征级别测量图像之间内容和风格的感知差异来提供准确的结果。每像素目标函数(MSE 和 L1)可能会误导模型关注图像之间的结构偏差。相反,感知损失通过计算所有平方误差之和的平均值来衡量与高级特征的差异,并且比每像素损失更稳健。受人类视觉对图像强度变化的高度敏感性的启发,我们通过预训练模型比较多层特征图,应用感知损失来学习内容信息
预训练模型从虚拟和实际对比 CT 中提取特征。输入 CT 在最后四个卷积块处以 2 × 、 4 × 、 8 × 和 16 × 因子进行下采样。感知热图是通过对虚拟和实际对比 CT 之间的特征水平差异进行平均而生成的,如图 5 所示。虚拟和实际对比 CT 之间的对比区域在肾脏区域的感知热图中突出显示。

生成器的目标函数描述为等式:

其中 \(\textcolor{blue}{λ_1}\) 是权重 MSE 损失的超参数(在训练中设置为 1),\(\textcolor{blue}{j}\) 指的是 (1, 4) 范围内的第 \(\textcolor{blue}{j}\) 个卷积块
3. 双路径培养方案
作者强调必须保留器官和增强区域的整体结构,以及血管和软组织的局部对比度增强细节。提出了双路径训练模式,允许网络同时学习局部和全局特征表示之间的相关性。全局路径的输入CT \(\textcolor{blue}{x}\)(大小为N × N)被分为四个小补丁[x1, x2, x3, x4],局部路径的大小为\(\textcolor{blue}{N∕2 × N∕2}\)。从本地路径生成的四个虚拟 CT patches被组合为虚拟对比 CT \(\textcolor{blue}{c_{local}}\)。全局路径生成虚拟造影CT图像\(\textcolor{blue}{c_{local}}\)。生成器的最终目标函数结合了双路径的损耗,如式(4)所示。

其中,\(\textcolor{blue}{λ_2}\)和\(\textcolor{blue}{λ_3}\)是调整双路网络权重的超参数(设置为0.6和0.4),\(\textcolor{blue}{G*}\)指式(3)
三、实验
1. 数据的收集与预处理
Dataset collection:CT 检查使用双源多探测器 CT(Somatom Force 双源 CT,西门子医疗解决方案,福希海姆,德国)进行。患者仰卧于手术台上。首先,使用 192 × 0.6mm 的探测器配置、90 kVp 的管电流、277 mAs 的质量参考,在吸气屏气时获得从肝顶到髂嵴的腹部预对比成像。静脉注射非离子造影剂350mg/ml(每公斤体重1.5ml,流速4ml/s)后,在腹腔干水平的腹主动脉开始推注追踪,阈值为100HU 。使用基于衰减的管电流调制(CARE Dose 4D,西门子)获得扫描。
该数据集包括动脉期、门脉期和延迟期的造影后的CT和造影前 CT。共有 65 名患者被分配参加该研究。训练和验证中,动脉期48例(5457张CT片),门脉期59例(6269张CT片),延迟期55例(5928张CT片)。选取5例(5名患者)590张CT片进行推断。
Data processing:对比前和对比后CT扫描的数据处理和配对选择策略介绍如下。
相应的CT片对选择:对比前后CT片配对的步骤如下。 (1)根据表格位置选择相应的CT图像; (2)为同一病例、轴平面上同一台位置的CT切片分配唯一的ID。
逐像素对齐:由于身体运动引起的CT错位,需要对CT图像对之间的错配进行校准,这极大地影响了优化过程。基于增强的相关系数最大化,采用仿射和平移变换来对齐对比前和对比后的 CT 图像。此外,排除了错位非常大(大于 6 个像素)的情况。选择具有最大重叠结构的造影前和造影后 CT 成对
窗口大小选择:CT图像中应用亨斯菲尔德单位(HU)来表示测量的衰减系数的线性变换。 HU 值范围从 1000(空气)到大约 2000(非常致密的骨骼)。为了更好地分析腹部和骨盆区域,窗口宽度和窗口级别分别设置为 400 和 30。
2. 实施细节
Pretrained model:预训练模型采用了来自大型公共国家肺部筛查测试 (NLST) 数据集的 41,589 个低剂量 CT 切片。通过应用 [0.5, 1.0, 1.5, 2.0] 系数,将 CT 图像转换为四个 CT 图像强度级别。训练的学习率设置为1e-4,并在8个epoch后下降0.1,由Adam优化器更新。总训练包括使用 Pytorch 1.0 和 Python 2.7 在 GeForce GTX 1080 GPU 上进行 10 个周期,批量大小为 2。
Model training:CT 大小调整为 256 × 256。三个连续的 CT 切片 (256 × 256 × 3) 模拟三个 RGB 通道作为全局路径网络的输入。对于当前切片前后没有相邻切片的 CT 扫描,将复制当前切片以填充空白。图2显示CT图像(256×256×3)被分为四个块(128×128×3)作为局部路径的输入。生成器由五个卷积块组成,输出维度设置为 [32, 64, 128, 256, 512]。解码器网络遵循 U-Net 跳跃连接。最后一层的 32 个通道与输入连接,后面是两个卷积层。生成器由预训练模型的权重初始化。对训练集和验证集应用 5 倍验证,以选择给出最佳结果的超参数设置。训练期间,生成器的学习率设置为 5e-5,鉴别器的学习率设置为 2e-4,40 个 epoch 后学习率降低 0.1,总共 50 个 epoch,批量大小为 2。权重衰减设置为 5e-4。应用 Adam 优化器用于优化。
3. 放射科医生评估
如图 6 所示,我们的框架和现有最先进方法(即不成对的图像到图像传输方法 CycleGAN 和无监督对比损失 基于 GAN Park)的虚拟对比度增强结果。由两名放射科医生根据整体图像质量、器官和血管的图像质量和对比度增强进行盲目评估。成对的预增强 CT 和实际增强 CT 以及预增强 CT 和虚拟增强 CT 用于评估。定性评级基于5点李克特量表,评价分数为差1)、次优(2)、可接受(3)、良好(4)和优秀(5)。由于不同时相的虚拟增强CT图像需要模拟器官和血管的对比增强,与非增强CT图像相比,分数可以认为是“1”:与非增强CT图像没有明显变化,“2” :为轻度虚拟对比度增强,“3”:为中等虚拟对比度增强,“4”:为良好虚拟对比度增强,“5”:为非常好的虚拟对比度增强。

放射科医生对"ours"的结果的平均评估为“3”(见图 6)。请注意,对于动脉期,该框架是通过主要突出动脉血管结构的 CT 图像进行训练的。因此,随着观察到动脉的对比度增强更多,评估分数稍高。我们的方法在所有评估方面都优于 CycleGAN)和 ContrastiveGAN 。尽管基于对比损失的 GAN 在动脉期和门脉期取得了与我们提出的方法相当的结果,但由于延迟期需要详细的对比增强尿路区域,我们的方法在生成更精确的结果方面远远超过了其他两种方法细节增强和更高的图像质量。
4. 与最先进的方法相比
对四个指标的定量评估用于比较虚拟和实际的对比增强 CT。
1️⃣峰值信噪比 (PSNR) :测量体素方面的差异。
2️⃣结构相似度指数(SSIM):根据非局部结构相似度评估图像质量。
3️⃣平均绝对误差 (MSE) 和空间不均匀性 (SNU):测量对比度增强精度。
表 1 显示了所提出方法的性能,并与动脉期 (AP)、门静脉期 (PP) 和延迟期 (DP) 的最新技术进行了比较。

与 CycleGAN 和 ContrastiveGAN 相比,所提出的方法在某些阶段的 PSNR 和 SSIM 性能略低。然而,PSNR和SSIM不能单独代表对比度增强区域的性能。 SNU 和 MSE 计算虚拟图像的对比度质量,并证明我们的方法在所有对比度增强阶段都优于其他方法。图 7 更好地体现了所提出方法的优点。

图 7 显示了"ours"提出的框架(图 7(e))与对比 GAN(图 7(c))和 CycleGAN(图 7(d))相比的对比度增强细节。在动脉期观察到动脉血管结构主要增强。在门脉期,可观察到器官实质和静脉血管结构(如门静脉和肝静脉)。在延迟阶段,当器官和血管逐渐消失时,尿液中造影剂的排泄会突出尿路。
与其他方法相比,我们的结果更清晰并且没有像素化。非增强组织更加清晰可见。所提出的像素级映射显示了生成细粒度增强区域的优势。 CycleGAN 和 Contrastive GAN 在细节方面表现出较差的增强效果,或者无法预测虚拟对比 CT 增强效果,尤其是在门脉期和延迟期。
5. 消融研究
本节描述感知损失、双路径训练模式和判别器的消融研究。定量和定性评价如表2和图8所示。

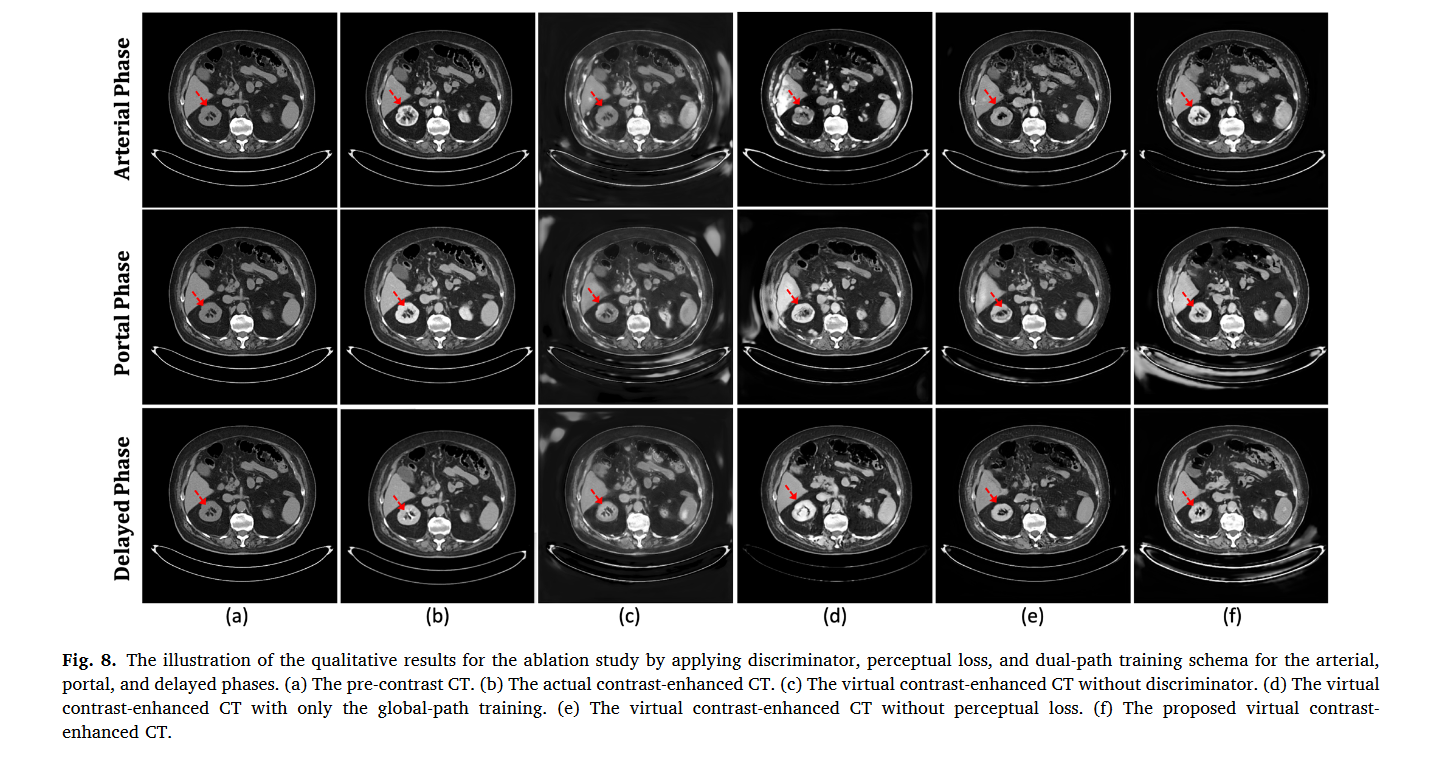
注:(a) 对比前 CT。 (b) 实际的对比增强 CT。 (c) 没有鉴别器的虚拟增强 CT。 (d) 仅进行全局路径训练的虚拟增强 CT。 (e) 无知觉损失的虚拟增强 CT。 (f) 拟议的虚拟增强 CT。
对抗性监督的有效性:每像素 MSE 和 L1 损失可能会忽略高频特征和过度平滑的纹理细节。在表 2 所示的所有评估指标上,对抗性监督优于没有判别器的模型,特别是对于 MSE 和 SNU。如图8所示,与没有鉴别器的方法(图8(c))相比,我们提出的方法(图8(f))在虚拟对比CT上显示出更准确的强度增强和更高的分辨率。
感知损失的有效性:表 2 显示,所提出的模型在所有评估指标上都优于没有感知损失的模型。与没有感知损失的情况相比(图8(d)),图8(f)显示出更好的增强效果和更少的伪影,证明了通过虚拟和实际增强CT之间的特征级别差异进行内容学习的好处。
双路径方案的有效性:实验评估有和没有双路径训练方案的模型。图 8 显示,在具有和不具有双路径模式的模型生成的虚拟增强 CT 中,主动脉得到了很好的增强。然而,图 8(e) 显示仅使用全局路径网络训练的模型未充分增强肾脏区域(由红色箭头突出显示)。图 8(f)展示了双路径模式的虚拟对比 CT 成功突出了详细的肾脏区域。表2表明,在所有评估分数上,使用双路径训练模式训练的模型都显着优于仅使用全局路径网络的模型,尤其是对于SNU。
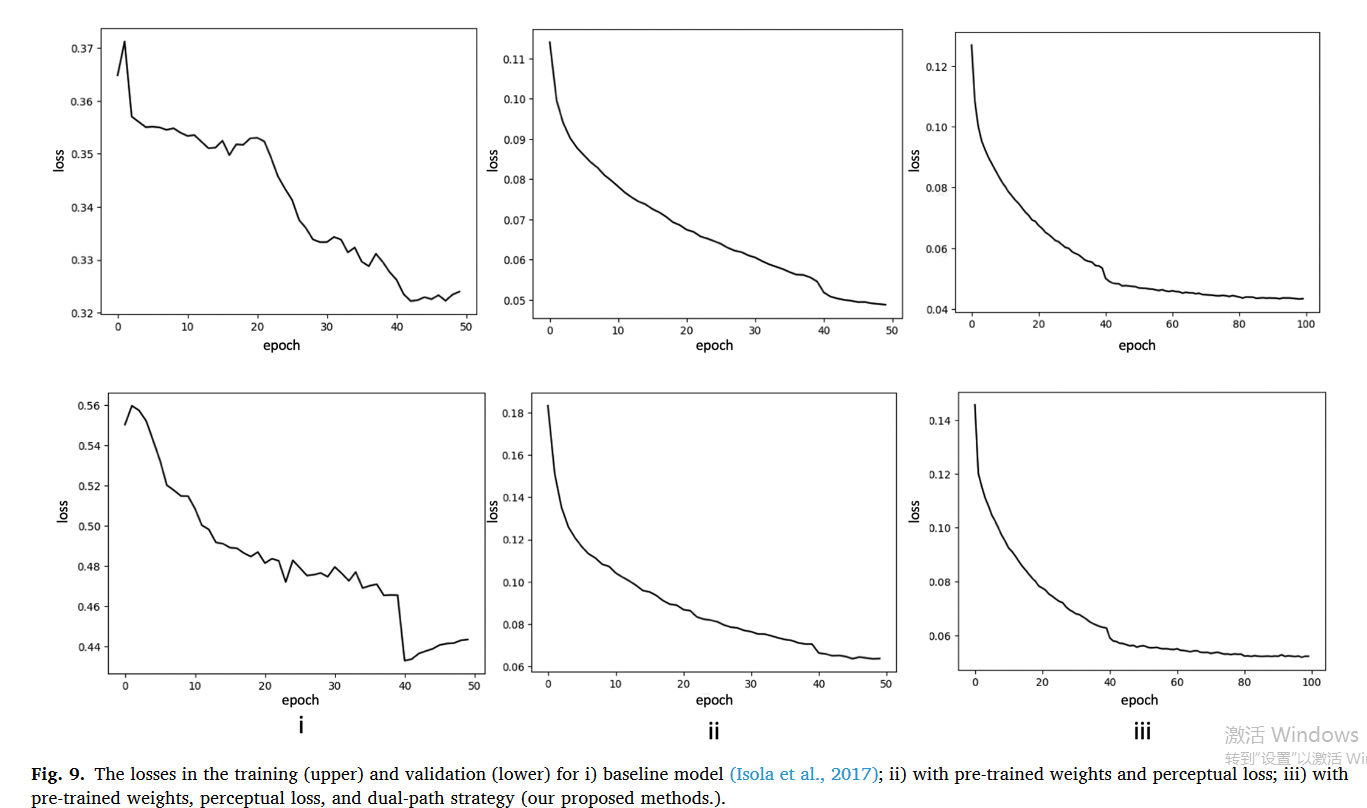
此外,1️⃣图 9 显示了基线模型(图 9(i))、2️⃣具有预训练权重和感知损失的建议模型(图 9(ii))以及3️⃣具有预训练权重、感知损失的建和双路径策略的模型(图 9(iii))。
训练损失(图9(i)上图)表明基线网络很难收敛,需要提前停止。
图9(ii)上图证实了使用预训练权重初始化的模型,感知损失很容易收敛并有效地学习对比增强特征。通过使用预训练模型、感知损失和双路径策略进行训练(图 9(iii) 上图),模型表现出更好的收敛性。
所提出模型的验证损失显示验证和训练之间的差距很小(图 9(ii) 和 (iii) 下图)。图 9(iii) 显示通过训练 50 个 epoch,损失曲线很好地收敛。
6. 剩下的挑战
图10将虚拟对比CT合成的剩余局限性总结为以下三个方面:(1)增强效果差、斑片状、不充分,即对比度不足; (2) 不必要的增强,出现伪影; (3) 不应对区域进行增强。

两个主要挑战导致了这些限制:首先,非增强-增强CT对会对生理运动的错位会严重影响增强的准确性,尤其是在延迟期。尽管前置步骤排除了具有较大错位的 CT 对,并应用仿射变换将错位限制在 3 个像素内,但一些剩余的错位仍然与伪影和不必要的增强相关。其次,腹部和骨盆区域由复杂的器官和解剖结构组成。缺乏训练样本会导致一些虚拟造影CT的增强效果不满意或没有细节增强。
总结
第一篇文章讲的是提出了一种改进的 cGAN,它可以从 NC 图像生成高质量的 CE-CT 图像,而无需注射造影剂。定量和定性实验结果表明,所提出的模型在 PSNR、SSIM 和 PCC 评分方面优于对比模型。除此之外,还进行了消融研究,分析金字塔池化模型、信息流路径和特征融合模型在合成 CE-CT 图像中的有效性。然而,为了获得ART和PV阶段的CE-CT图像,需要训练两个生成器模型,这增加了训练时间。作者也提出了未来会尝试通过生成器从 NC 图像合成不同阶段的 CE-CT 图像。
第二篇则是通过基于 GAN 的框架直接从腹部和骨盆的非对比 CT 扫描生成虚拟对比增强 CT 的概念。提出了一种双路径训练策略来保持高级结构特征和局部纹理特征,以产生具有细节的真实虚拟对比CT。使用对比感知预训练模型进行感知损失,以比较虚拟对比 CT 和实际对比增强 CT 之间的特征水平差异。所提出的框架成功地预测了虚拟增强CT密度,同时保留了非增强图像的结构信息,并取得了良好的性能,并在临床应用中展现了良好的潜力。