
本文所介绍的内容是来自Medical Diffusion: Denoising Diffusion Probabilistic Models for 3D Medical Image Generation。 注:该文章与第一篇的文章是同一团队写的。
本文代码已开源medicaldiffusion。
一、介绍
本文主要是用于探究扩散模型是否能够用于生成医学3D图像。作者提出了一种适用于潜在空间的扩散模型的新架构,并在四个公开可用的数据集上对其进行训练,这些数据集包含来自广泛解剖范围的数据:脑 MRI、胸部 CT、乳腺 MRI 和膝部 MRI。
该框架可以看作是潜在扩散模型的扩展:将扩散概率模型附加到 VQ-GAN 的潜在空间中以生成高分辨率 3D 图像。作者表明了该方法与将扩散模型直接应用于 3D 数据相比的几个好处:
- 1)可以减少训练模型所需的计算资源,因为它应用于维度较小的压缩潜在空间。
- 2)通过在较低维度的潜在空间中对图像进行采样,我们可以减少生成新样本所需的时间。
- 3)潜在空间封装了有关覆盖图像整个区域的图像内容的更抽象信息,而不是像素级信息,从而使其可用于高级应用程序,例如预测未来图像外观,而不管图像旋转或平移如何。
二、方法
该医学扩散模型架构由两步组成。
1️⃣第一步,将图像编码到低维潜在空间:在整个数据集上训练 VQ-GAN 模型,以学习数据的有意义的低维潜在表示。由于输入扩散模型的输入应标准化为 -1 和 1 之间的范围,因此我们必须保证图像的潜在表示也在该范围内。假设 VQ-GAN 模型中的向量量化步骤强制学习的码本向量在量化之前接近潜在特征向量,我们通过学习的码本中的最大值来近似未量化特征表示的最大值。类似地,我们用学习的码本中的最小值来近似未量化特征表示的最小值。因此,通过对未量化的特征向量执行简单的最小-最大归一化,我们获得了值接近 -1 和 1 范围的潜在表示。
2️⃣第二步,根据数据的潜在表示训练扩散模型:将数据的潜在表示用于训练 3D 扩散模型。然后,我们可以从标准高斯采样的噪声开始,通过反向运行扩散过程来生成新图像。然后使用 VQ-GAN 学习的码本对该过程的输出进行量化,然后将其输入解码器以生成相应的图像。
1.VQGAN
VQGAN是一种基于GAN的生成模型,由两个核心部分所组成:
🔸VQ是一种数据压缩技术,是指将连续数据表示为离散化的向量。输入的图像或文本被映射到VQ空间中的离散化表示,然后,离散化向量被送到GAN模型中进行图像生成。
🔸GAN是由生成器和判别器两个模型组成的,生成器负责生成图像,判别器负责判断生成的图像是否为真实的图像。在训练的过程中,生成器和判别器相互博弈,不断优化各自的参数,以使生成图像更加逼近真实图像。

1.1 模型运作机制
一张RGB三通道的图像\(\textcolor{blue}{x \in R^{H\times W\times 3}}\),通过CNN Encoder编码器得到潜在变量\(\textcolor{blue}{z_e \in R^{(H/s) \times (W/s) \times n_z}}\),其中 H 表示高度,W 表示宽度,\(n_z\) 表示潜在特征图的数量,s 表示压缩因子。
预先生成一个离散数值的codebook \(\textcolor{blue}{\mathcal{Z}=\{z_k\}^K_{k=1}\in R^{n_z}}\),在\(\textcolor{blue}{z_e}\)的每一个编码位置都去\(\textcolor{blue}{\mathcal{Z}}\)中去寻找其距离最近的code,生成具有相同维度的变量\(\textcolor{blue}{z_q \in R^{(H/s) \times (W/s) \times n_z}}\),此时这一步离散编码的过程可以表示为:
\[\huge z_q = q(z_e):=(\arg\min\limits_{z_k \in \mathcal{Z}}||z_e^{ij} - z_k||)\]
这样就可以将已经数值离散化的\(\textcolor{blue}{z_q}\)输入解码器CNN Decoder来重建图像:
\[\huge \hat{x} = G(z_q)=G(q(E(x)))\]
1.2 扩展VQGAN视频生成框架
本文的3D VQGAN是参考这篇文章《Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer》。所以下面将介绍该论文当中的3D VQGAN以便于对其有更好的理解。
⬛训练VQGAN: 在一开始用于生成视频的VQGAN,通过用 3D 卷积替换其 2D 卷积运算来调整 VQGAN 架构用于视频生成。给定一段视频\(\textcolor{blue}{x \in R^{T\times H\times W\times 3}}\),若是由编码器\(\textcolor{blue}{f_\varepsilon}\)和解码器\(\textcolor{blue}{f_\mathcal{G}}\)所组成的VQVAE,可以先使用解码器将输入视频变成潜在向量\(\textcolor{blue}{z_e}\)。之后可以利用可训练codebook \(\textcolor{blue}{\mathcal{C}=\{c_i\}^K_{i=1}}\),通过最近邻搜索找到\(\textcolor{blue}{z_e}\)其距离最近的code,生成具有相同维度的变量\(\textcolor{blue}{z=q(f_\varepsilon(x)) \in R^{t\times h\times w}}\),然后将其输入到解码器当中重建图像\(\textcolor{blue}{\hat{x} = f_\mathcal{G}(c_z)}\)。那么VQVAE的训练损失如下:

其中,sg是停止梯度操作,按照VQGAN的论文当中\(\textcolor{blue}{\beta = 0.25}\),使用EMA更新去优化\(\textcolor{blue}{\mathcal{L}_{codebook}}\)。
VQGAN在此基础上还采用感知损失和判别器\(\textcolor{blue}{f_\mathcal{D}}\)来提高重建质量。在该模型当中会采用两种类型的判别器:
◾空间判别器\(\textcolor{blue}{f_\mathcal{D_s}}\):它随机重建某一帧\(\textcolor{blue}{\hat{x} \in R^{H\times W\times 3}}\),来提高帧质量。
◽时间判别器\(\textcolor{blue}{f_\mathcal{D_t}}\):它重建一整个视频\(\textcolor{blue}{\hat{x} \in R^{T\times H\times W\times 3}}\),惩罚不合理的运动。
因此判别器的损失如下:

作者还使用特征匹配损失来稳定 GAN 训练:

其中,\(\textcolor{blue}{f_{\mathcal{D}_{s/t}/VGG}^{(i)}}\)表示一个经过训练的VGG网络的第\(\textcolor{blue}{i}\)层,或者是具有缩放因子\(\textcolor{blue}{p_i}\)的判别器。当使用 VGG 网络时,这种损失称为感知损失,\(\textcolor{blue}{p_i}\)是 VGG 的学习常数,也是判别器层中元素数量的倒数。因此, VQGAN 总体训练目标如下:
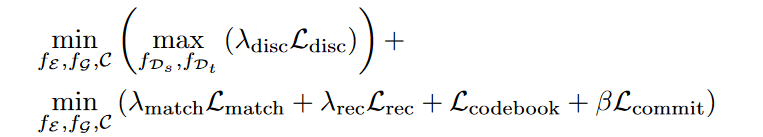
⬜自回归先验模型:在训练视频 VQGAN 后,在生成的时候,每个视频都可以编码为其离散表示\(\textcolor{blue}{z=q(f_\varepsilon(x))}\) 。遵循 VQGAN,使用行主序逐帧将这些token展开为一维序列。
VQGAN的作者使用了自回归图像生成模型的常用做法,给图像的每个像素从左到右,从上到下规定一个顺序(行主序)。有了先后顺序后,图像可以被视为一个一维句子,之后可以用Transformer生成句子的方式来生成图像。如在第\(\textcolor{blue}{i}\)步,Transformer会根据前\(\textcolor{blue}{i-1}\)个像素\(\textcolor{blue}{s_{<i}}\)生成第\(\textcolor{blue}{i}\)个像素\(\textcolor{blue}{s_{i}}\)。
然后,我们训练Transformer\(\textcolor{blue}{f_\mathcal{T}}\)以自回归方式对数据集中 z 的先验分类分布进行建模:

其中,\(\textcolor{blue}{p(z_{i+1}|z_{0:i}) = f_\mathcal{T}(z_{0:i})}\),而\(\textcolor{blue}{z_0}\)作为序列标记的开头。训练Transformer以最小化训练样本的负对数似然:

在推理的时候,根据预测的分类分布\(\textcolor{blue}{p(z_{i+1}|z_{0:i})}\),按顺序随机采样视频token,并将它们输入解码器以生成视频\(\textcolor{blue}{\hat{x} = f_\mathcal{G}(c_z)}\)。
在本文当中根据VQGAN所定义的,作者使用感知损失作为重建损失,\(\textcolor{blue}{\mathcal{L}_{commit}}\)被定义为未量化的潜在特征向量和相应的码本向量之间的均方误差。请注意,仅针对连续潜在特征向量计算梯度,以强制与量化码本向量更加接近。通过在映射到它的所有潜在向量上维护指数移动平均值来优化可学习的码本向量。此外,在输出处使用基于patch的鉴别器以获得更好的重建质量。为了扩展此架构以支持 3D 输入,用3D卷积替换2D卷积。此外,我们将原始 VQ-GAN 模型中的判别器替换为切片(空间)判别器(将图像体积的随机切片作为输入)和 3D时间判别器(将整个重建体积作为输入),并添加特征匹配损失以稳定 GAN 训练。
2.扩散模型
扩散模型 ,通过潜在变量 \(\textcolor{blue}{x_1 · · · x_T}\) 上的马尔可夫链定义。主要思想是,从图像 \(\textcolor{blue}{x_0}\)开始,我们通过在\(\textcolor{blue}{T}\)个时间步长内添加方差逐渐增加的高斯噪声来连续扰动图像。然后训练以时间步\(\textcolor{blue}{t}\)处图像的噪声版本和时间步本身为条件的神经网络,以学习用于扰动图像的噪声分布,以便时间\(\textcolor{blue}{t-1}\)处的数据分布\(\textcolor{blue}{p(x_{t-1}|x_{})}\)可以推断。当\(\textcolor{blue}{T}\)变得足够大时,我们可以通过先验分布\(\textcolor{blue}{\mathcal{N}(0,1)}\)来近似\(\textcolor{blue}{p(x_T)}\),从该分布中采样,然后反向遍历马尔可夫链,以便我们可以从学习的分布\(\textcolor{blue}{p_\theta}\)中采样新图像\(\textcolor{blue}{x_0}\) 。用于对噪声建模的神经网络通常选择 U-Net。为了支持 3D 数据,我们用 3D 卷积替换 U-Net 中的 2D 卷积。此外,遵循Video Diffusion Model的方法仅在高分辨率图像平面上使用卷积(即大小为 1x3×3 的内核),然后在该高分辨率平面上使用空间注意力块(从而将深度维度视为批量大小的扩展)以增加计算效率。然后,空间注意块后面是深度注意块,其中高分辨率图像平面轴被视为批处理轴。
综合起来,在整个数据集上训练 VQ-GAN 模型,以学习数据的有意义的低维潜在表示。由于输入扩散模型的输入应标准化为 -1 和 1 之间的范围,因此我们必须保证图像的潜在表示也在该范围内。假设 VQ-GAN 模型中的向量量化步骤强制学习的码本向量在量化之前接近潜在特征向量,我们通过学习的码本中的最大值来近似未量化特征表示的最大值。类似地,我们用学习的码本中的最小值来近似未量化特征表示的最小值。因此,通过对未量化的特征向量执行简单的最小-最大归一化,我们获得了值接近 -1 和 1 范围的潜在表示。然后可以将这些表示用于训练 3D 扩散模型。然后,我们可以从标准高斯采样的噪声开始,通过反向运行扩散过程来生成新图像。然后使用 VQ-GAN 学习的码本对该过程的输出进行量化,然后将其输入解码器以生成相应的图像。
三、结果
作者将来自四个不同解剖领域的公开数据集用于训练扩散模型,其分别来自:阿尔茨海默病神经影像计划 (ADNI) 的脑 MRI 检查、癌症成像档案 (LIDC) 的胸部 CT 检查、杜克大学 (DUKE) 的乳腺 MRI 检查、以及斯坦福大学 (MRNet) 的膝部 MRI 检查。作者为了展示该方法对于小数据集的能力,这四个模型仅在 1,250 张(膝盖 MRI)、998 张(脑部 MRI)、1,844 张(乳房 MRI)和 1,010 张(胸部 CT)图像上进行训练。(每一例患者当中挑选出一张图片。
1.医疗扩散模型可以进行稳健训练
尽管数据集相对较小,但每个模型都会收敛并生成逼真的合成图像,而无需微调任何超参数,如下图所示:

2.医学扩散模型能够生成高质量医学3D数据
我们根据三个不同的类别评估了人类专家的合成图像:1)整体图像外观的质量,2)切片之间的一致性和3)解剖正确性。两名分别具有 9 年(读者 A)和 5 年(读者 B)经验的放射科医生被要求以李克特量表对四个数据集中各 50 张图像进行评分,见表 1。

更有经验的放射科医生(读者A)对 200 项检查中的 189 项进行了评分,认为总体上比较现实,只有少量不切实际的区域(ADNI 为 50/50,LIDC 为 40/50,DUKE 为 50/50,MRNet 为 49/50)。 200 项检查中的 191 项被评定为在大多数切片中表现出切片之间的一致性(ADNI 为 50/50,LIDC 为 41/50,DUKE 为 50/50,MRNet 为 50/50),而 185/200 仅表现出轻微或无解剖学不一致(ADNI 为 50/50,LIDC 为 40/50,DUKE 为 50/50,MRNet 为 45/50)。具有 5 年经验的放射科医生也给出了类似的评级。这些数据共同表明,我们的架构可以生成对于该领域专家来说显得逼真的合成图像。
对用于训练医学扩散模型的四个数据集的图像合成能力进行定量评估。两名拥有 9 年经验(读者 A)和 5 年经验(读者 B)的放射科医生的任务是根据李克特量表评估每个数据集的一组 50 张合成图像。用于评估图像的三个类别是“真实图像外观”、“切片之间的一致性”和“解剖正确性”。



3.潜在空间的维度对于高质量图像生成的重要性
为了分析潜在维度对图像生成质量的影响,作者使用两种不同的压缩因子训练 VQ-GAN 自动编码器。我们发现,当将每个空间维度压缩 8 倍时(即大小为 256x256x32 的图像的潜在维度为 32x32x4),相关的解剖特征会丢失。

当使用较小的压缩因子 4(即大小为 256x256x32 的图像具有 64x64x8 的潜在尺寸)训练 VQ-GAN 自动编码器时,可以更准确地重建解剖特征。
4.医疗扩散模型在图像多样性方面优于 GAN
作者将他们提出的扩散模型与已建立的 GAN 进行比较,选择带有梯度惩罚的 Wasserstein GAN (WGAN-GP) 作为基线。作者通过对同一数据集的 1000 个合成样本对的结果进行平均,根据多尺度结构相似性度量(MS-SSIM) 来比较这两个模型。因此,较高的 MS-SSIM 分数表明该模型生成的合成图像彼此更相似,而较低的 MS-SSIM 分数则表明相反。我们发现,GAN 模型无法生成多样化的图像,正如其 0.9996 的高 MS-SSIM 分数所表明的那样,导致合成图像通常是相同的。相比之下,扩散模型的 MS-SSIM 得分为 0.8557,更接近原始数据的 MS-SSIM 得分 (0.8095)。这些数据共同表明,扩散模型能够生成代表原始数据分布的更多样化的样本,因此这些模型可能更适合后续项目,例如用于分类模型的训练或教育。
5.合成数据可用于训练神经网络
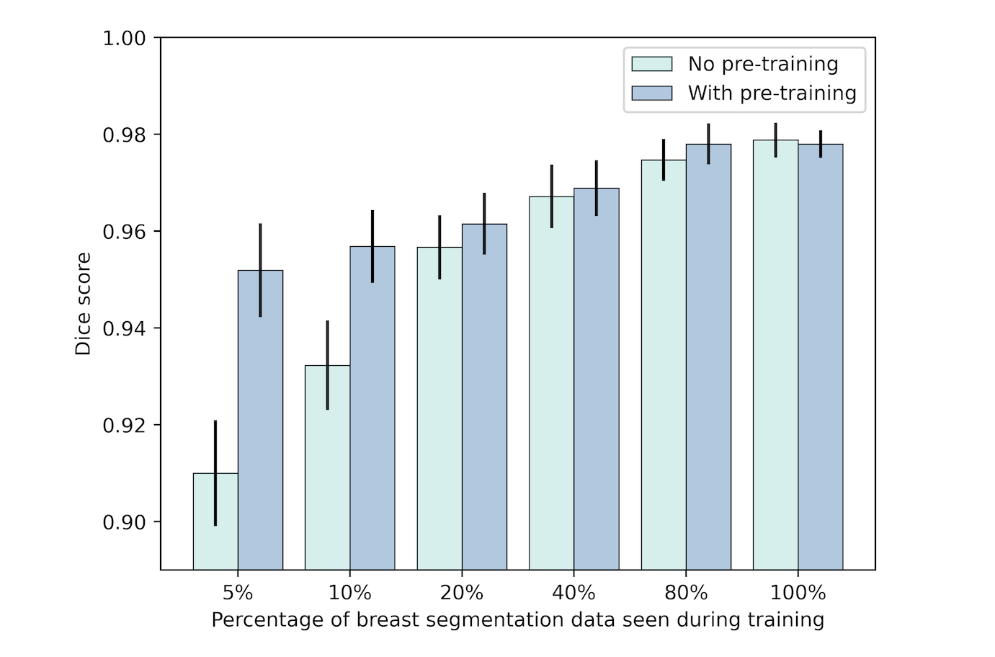
我们在机构 A 希望与机构 B 合作以提高神经网络的性能而不共享任何原始数据的情况下评估合成数据的可用性。为此,我们使用在 DUKE 数据集上训练的扩散模型生成了 2000 个合成图像,并在合成数据的自监督设置中预训练了 Swin UNETR 。然后,我们使用机构 B 的可用分割数据对预训练网络进行微调,以分割 MRI 扫描中的乳房区域。为了展示有限数据设置中的性能提升,我们进行了多次训练,其中使用了越来越多来自机构 B 的可用数据(5%、10%、20%、40%、80% 和 100%) 。为了进行比较,我们训练了相同的神经网络来执行相同的任务,但没有使用合成数据进行预训练。我们发现,使用来自其他机构的合成数据进行预训练可以在很大程度上提高 Dice 分数方面的分割性能 - 特别是在可用标记训练较小的情况下(无预训练时为 0.91,而预训练为 5% 时为 0.95)数据,见图4和5)。
在自监督预训练设置(“有预训练”)期间和没有预训练时提供合成图像数据 (n=2000) 时,Swin UNETR 在乳房分割的 Dice 分数方面的性能比较进行训练(“无预训练”)。在可选的自监督预训练步骤之后,使用 5%、10%、20%、40%、80% 或 100% 的可用内部数据以及乳房分割掩模的相应地面实况对模型进行微调(n= 200)。我们发现,当只有很少的数据可用于训练时,使用另一个机构的数据集生成的合成数据可以很大程度上提高内部数据集的 Dice 分数。
三种不同情况(行)的乳房分割性能的可视化。原始图像和地面真实分割显示在前两列中。第三列显示了在训练期间使用内部数据集中 5% 的可用数据时 Swin UNETR 神经网络的分割。最右边的列显示了 Swin UNETR 在使用使用来自另一个设施的数据集生成的 2,000 个合成图像以自监督方法进行预训练时的分割,然后使用内部数据集中的 5% 的可用数据进行微调。绿色区域表示正确的分割,而红色区域表示与真实情况的偏差。

四、总结
在本文中,作者首次对 MRI 和 CT 数据的潜在扩散模型进行了大规模评估。证明了,此类模型可以生成真实的 3D 体积数据,该数据在连续 3D 结构的合成中保持一致,并且能够准确反映人体解剖结构。并表明,即使模型是在大约 1,000 个样本的相对较小的数据集上进行训练,这种复杂数据的训练也能稳健地收敛。这与 GAN 形成鲜明对比,GAN 通常需要大量的超参数调整和大型数据集才能成功训练。更重要的是,即使 GAN 能够成功训练,我们发现我们的扩散模型能够更准确地涵盖医疗实践中遇到的图像的多样性。这对于在人工智能方法的开发中使用此类合成图像非常重要。我们还通过对合成数据进行人体乳腺 MRI 检查的分割模型进行预训练,展示了潜在扩散模型的潜在医学应用,并表明这种预训练有助于使分割模型更加稳健。总之,与 GAN 相比,潜在扩散模型是一种生成合成 3D 医学数据的优越方法,并且可以为开发合成 MRI 或 CT 数据的 AI 方法奠定基础。