
本文所介绍的内容是来自《Med-DDPM: Conditional Diffusion Models for Semantic 3D Medical Image Synthesis》。
本文代码已开源:med-ddpm。
一、介绍
本文使用了扩散模型做语义3D医学图像生成,命名为Med-DDPM。 本文的创新点是它在 3D 图像合成中对扩散模型使用语义条件。通过像素级掩模标签控制生成过程,它有助于创建逼真的医学图像。实证评估强调了 Med-DDPM 在准确性、稳定性和多功能性等指标方面优于 GAN 技术。此外,Med-DDPM 在提高分割模型的准确性方面优于传统增强技术和合成 GAN 图像。它解决了数据集不足、注释数据缺乏和类别不平衡等挑战。
二、方法原理
在原始DDPM的基础上,作者做出了如下的改进:
1)将线性噪声序列改成余弦噪声序列(详细可参考第三篇Improved DDPM);
2)在原始的U-Net架构中,将所有2D操作(如层、噪声输入)替换成3d项;
3)通过将加噪后的图像\(x_t\)的通道与分割掩模的通道进行级联,从而修改U-Net模型的输入图像 \(x_t\) ,该掩模指导生成过程,从而能够合成有意义的图像,例如精确定位肿瘤的大脑病理 MRI。
4)将原始DDPM的L2损失改为L1损失:
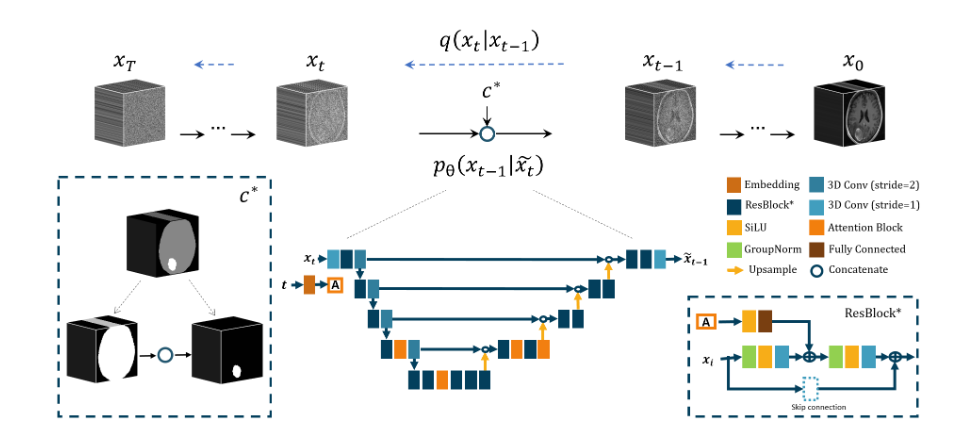
由于本文的创新点以及模型改进主要集中在第三点以及第四点上,所以下面逐步展开细说第三点以及第四点的改进:
本文使用的训练图像和分割掩模是具有三个维度的单通道体积图像:宽度(w)、高度(h)和深度(d)。而文中所使用的是原始临床脑部 MRI 数据集,该数据集的分割掩模由三个类别标签组成:0代表背景,1对应大脑区域,2代表肿瘤区域。为了将掩模图像与类标签对齐,作者执行了 one-hot 编码操作,排除背景类标签 0,因为它不相关。该操作产生了具有两个通道的掩模图像,其中通道 0 代表大脑区域,通道 1 代表肿瘤区域。然后应用通道级联来组合图像和掩模,从而产生具有三个通道的级联图像,表示为:
\[\huge \textcolor{blue}{\tilde{x}_t^{(3,w,h,d)}:=x_t^{(1,w,h,d)} \bigoplus c^{(2,w,h,d)}}\]
在作者的研究当中, L2 损失函数由于计算的是估计值和目标值之间的平方差,因此对异常值很敏感。另一方面,L1损失计算估计值与目标值之间的绝对差,使其对异常值的敏感度相对较低。因此,在本文的主要实验中,将利用 L1 损失代替原本L2损失:

最后,Med-DDPM的训练以及采样分别如下:


三、实验
本文进行实验的目的如下:
1)证明Med-DDPM 在准确性、稳定性和多功能性等指标方面优于 GAN 。
2)证明Med-DDPM 在增强分割模型性能和作为数据增强替代方案方面的功效。
为了验证实验想要达到的预期效果,作者从主数据集创建了两个子数据集。第一种模式涉及 1292 个图像的训练集和 208 个图像的测试集。在第二种模式中,随机选择 100 张图像进行训练,100 张图像进行验证,100 张图像进行测试,创建一个小型数据集(创建小型数据集的原因,是为了挑战扩散模型在数据稀缺情况下所展现的潜力)。并且选择 Pix2Pix GAN和 DiscoGAN 作为基线模型,并将其架构调整为 3D 模型。
1.Med-DDPM合成的质量评估
在第一种模式中,作者使用 1292 个图像训练Med-DDPM和基线 GAN 模型,历时 100,000 个epoch,batch-size为 1(称为主模型),然后在 208 张测试图像上评估了这些模型。本文采用定量和定性措施来评估合成图像。
定量结果:下表展示了MedDDPM 与基线 DiscoGAN 和 Pix2Pix 相比的性能。

结果证明了 Med-DDPM 的优越性能。它实现了 0.0548 的最低 MSE,表明其在输出中保留更精细细节和结构的强大能力。此外,Med-DDPM 在 MMD 方面表现优于 GAN,值为 4.1909,表明其匹配目标域分布的能力很强。而Med-DDPM模型在的3D-FID指标显示得分明显较低,值为249.713,这一结果表明 Med-DDPM 在生成逼真且高质量 3D 结构方面的熟练程度。尽管模型的 MS-SSIM 得分 (0.4358) 与真实数据的 MS-SSIM 得分 (0.4728) 不太接近,但与 Pix2Pix 相比,它使模型更接近真实数据。
下图展示的是真实图像的冠状面、矢状面和轴向切片以及Med-DDPM和基线 GAN 模型生成的样本。
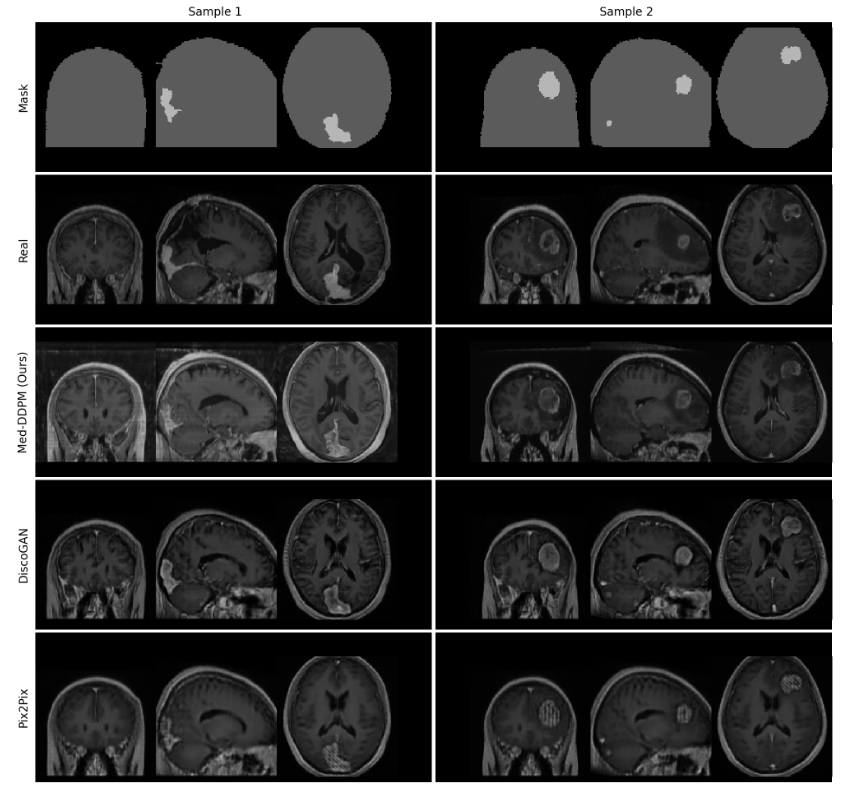
从图中可以观察到,Pix2Pix 模型生成的图像较模糊。与 Pix2Pix 模型相比,DiscoGAN 模型表现更好,生成更真实的图像,肿瘤区域清晰。然而,值得注意的是,DiscoGAN 生成的图像未能清楚地描绘大脑的独特特征。此外,它们会产生粗糙的脑回和脑沟,这看起来不自然。相比之下,本文所提出的 Med-DDPM 模型生成高度逼真和高质量的图像,显示出大脑特征和肿瘤区域的清晰可见性。
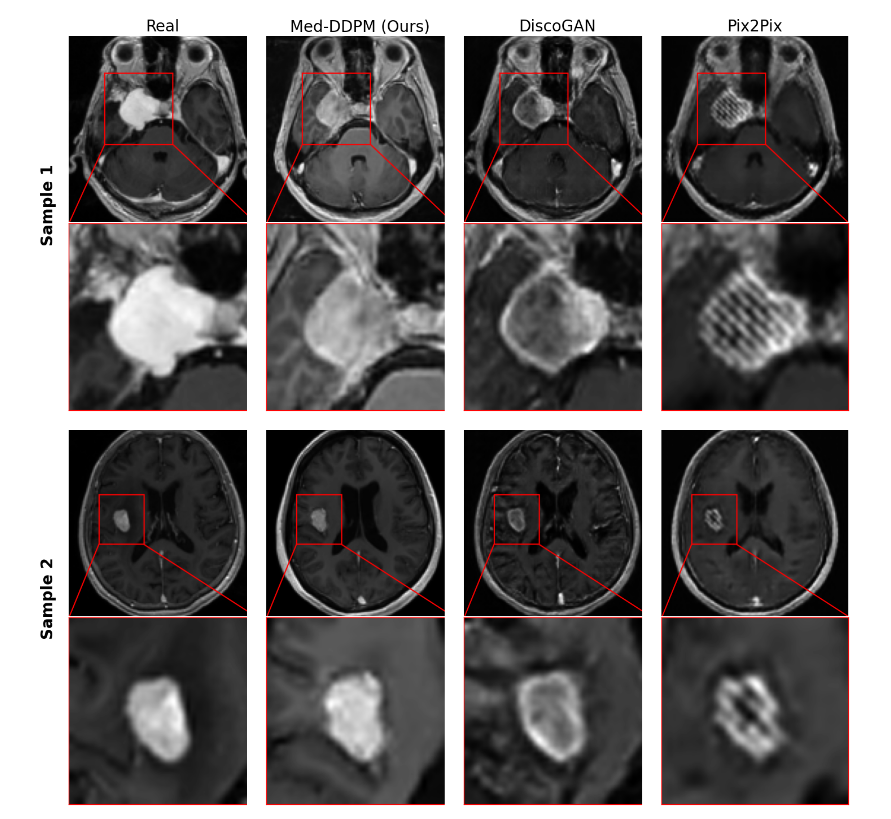
下图展示的是真实图像和合成图像的轴向平面中肿瘤区域的放大图像。
下图展示了使用操纵掩模生成的合成图像

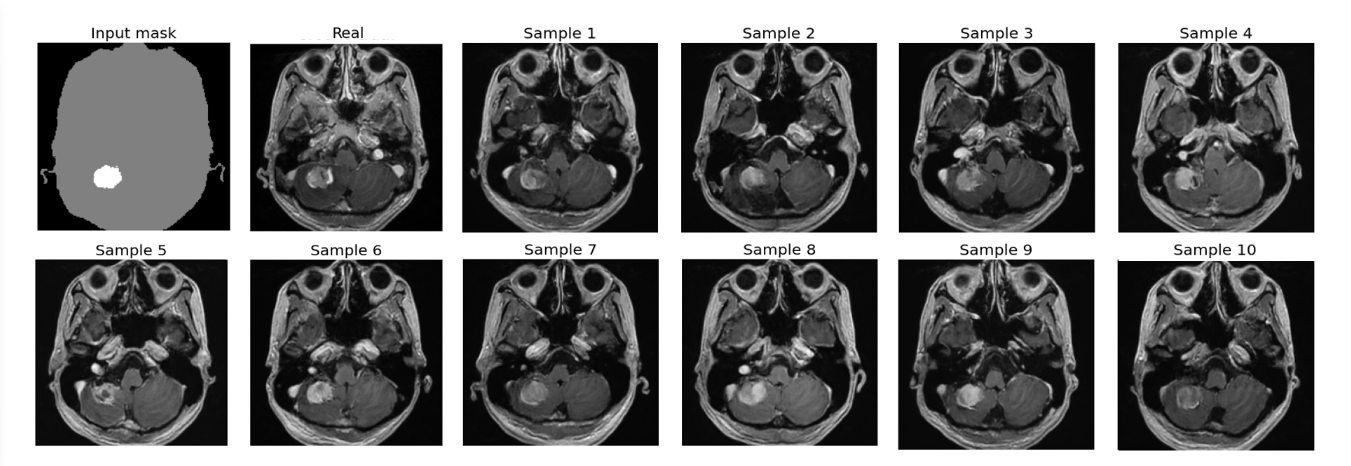
下图展示了为单个输入掩模生成的合成图像的多样性。
2.在合成图像上训练的分割模型的比较
在第二种模式中,使用小型数据集从头开始训练所有模型,历时 50,000 个epoch,batch-size为 1(称为玩具模型)。此外,作者使用该小型数据集和玩具模型生成的合成图像去训练了 3D U-Net 分割模型。为了评估合成图像作为数据增强替代方案的性能,作者还使用各种训练数据组合来训练 U-Net 模型,包括中当前最先进的医学图像增强。分割模型使用 BCE 损失进行 100 个时期的训练,批量大小为 4。使用 Dice 系数和 IoU 分数评估模型性能。
下表展示了各种数据样本组合进行训练的 3D U-Net 在玩具数据集上进行肿瘤分割的实验结果,这些数据样本包括真实图像、增强图像以及由Med-DDPM 玩具模型和在同一数据集上训练的基线模型生成的合成图像。其中,真实图像是指来自玩具数据集的 100 张训练图像。增强图像通过应用最先进的 nnU-Net 增强来操作玩具数据集中的训练图像来创建。下表的评估分数代表分割模型在测试集上的性能,测试集由玩具数据集中的 100 张图像组成。 Syn 1000、Syn 2000 和 Syn 5000 表示用于训练分割模型的合成图像的数量。
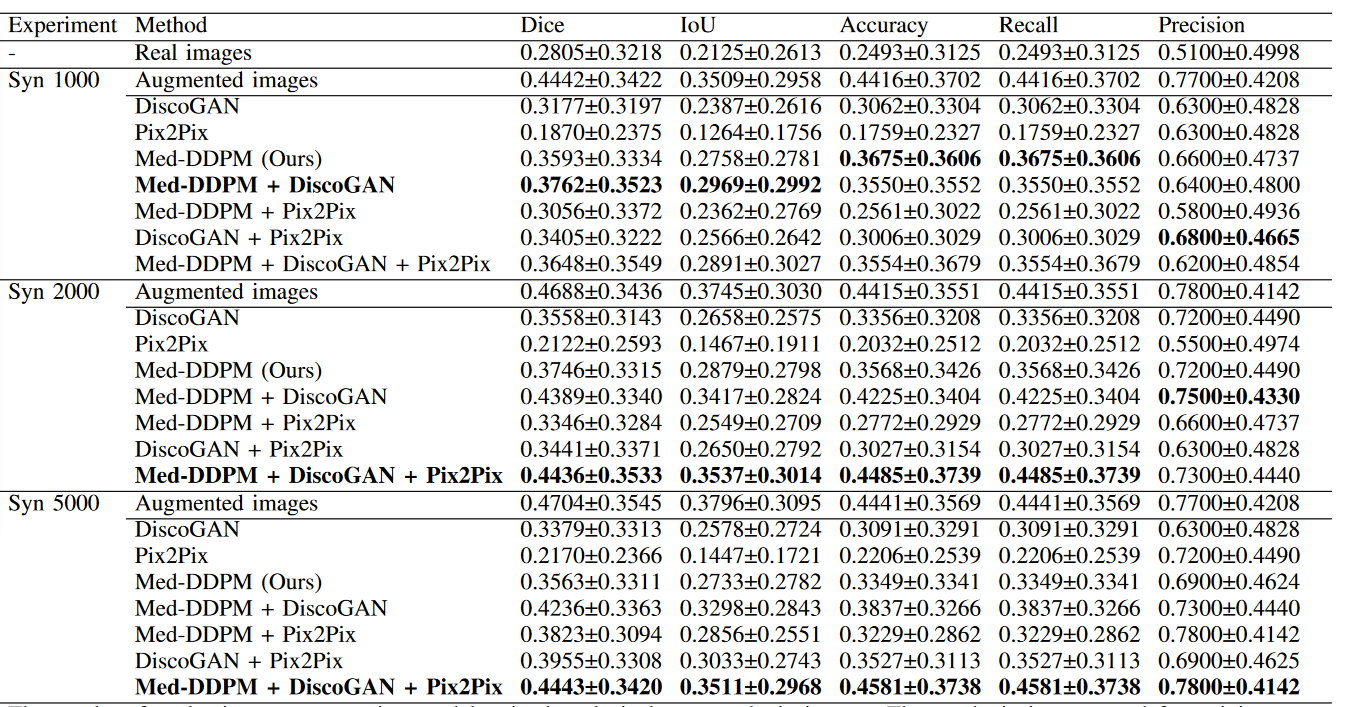
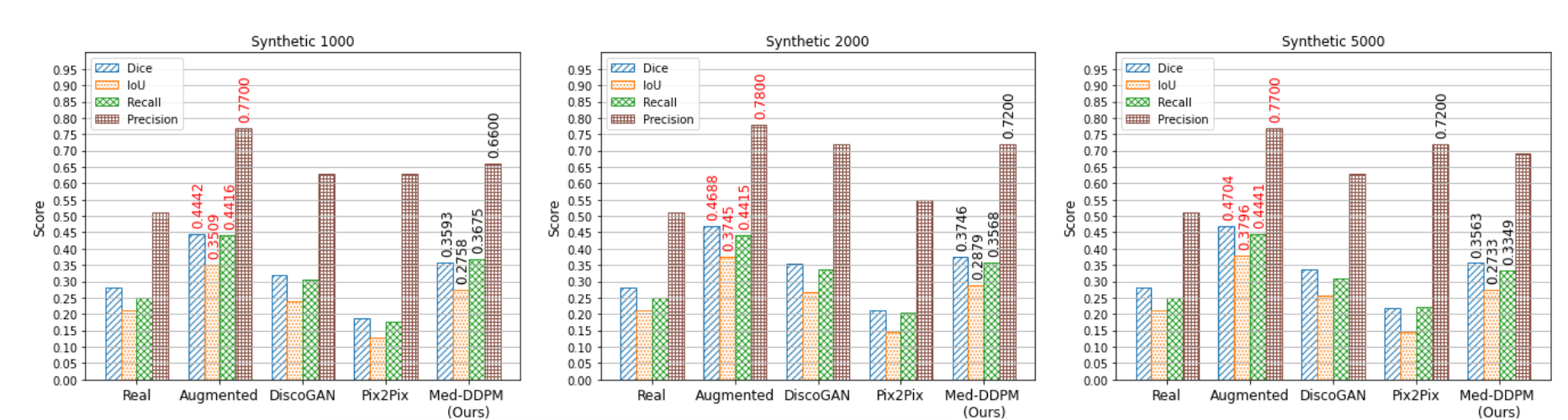
首先,我们可以看到使用合成图像进行训练(Pix2Pix 模型除外)的分割模型,其性能始终优于使用真实图像进行训练。另外,使用最先进的增强生成的图像始终能够实现最高的性能。对于 1000、2000 和 5000 张图像,Dice 分数分别增加到 0.4442、0.4688 和 0.4704。这种提高可能是由于增强图像源自对真实训练图像的操作,捕获了真实肿瘤图像的复杂且相关的特征,同时增加了训练数据的多样性。
Med-DDPM 相对于基线和其他 GAN 模型提供了显着的改进,1000、2000 和 5000 个图像集的 Dice 分数分别为 0.3593、0.3746 和 0.3563,如下图所示。这一改进意味着 Med-DDPM 方法比其他 GAN 模型更好地捕捉了分割任务的复杂性,并且更接近最先进的增强技术所实现的性能。
当 Med-DDPM 与 DiscoGAN 和 Pix2Pix 结合时(具体如何结合,本文没有明说),结果变得更加有希望,这表明这些方法在生成用于肿瘤分割的有效合成图像方面相辅相成。特别是在 5000 张合成图像的实验中,Med-DDPM 与 DiscoGAN 和 Pix2Pix 相结合,获得了 0.4443 的 Dice 分数和 0.3511 的 IoU,几乎与最先进的增强技术一样好。总的来说,这些结果说明了使用合成图像训练 U-Net 进行肿瘤分割的有效性,以及所提出的方法 Med-DDPM,特别是与 DiscoGAN 和 Pix2Pix 结合使用时,展示了与最先进的增强技术相比的竞争性能。
四、总结
在本文中,我们提出了 Med-DDPM,这是一种利用条件去噪扩散概率模型生成高质量、多样化 3D 医学图像的新方法。我们在训练和采样阶段都将条件掩模图像作为先验。我们的结果证实了 Med-DDPM 生成 3D 医学图像的能力,这些图像不仅具有卓越的质量,而且还包含广泛的可变性。使用在 Med-DDPM 生成的合成图像上训练的分割模型进行的实验证明了分割性能的显着提高。这一成功凸显了 Med-DDPM 作为医学成像数据增强的强大工具以及医学成像领域先进数据匿名化工具的潜力。另外,本文使用的是最原始DDPM的框架进行实验,作者提出未来的工作可以通过潜在扩散模型的集成来增强其图像生成能力。