
本文所介绍的内容是来自《Diffusion Probabilistic Models beat GANs on Medical Images》。
一、介绍
在本文中,作者提出了 Medfusion,一种用于医学图像的条件潜在 DDPM。通过使用来自眼科、放射学和组织病理学的图像,将基于 DDPM 的模型与基于 GAN 的模型进行比较,并证明 DDPM 在所有相关指标上都击败了 GAN。
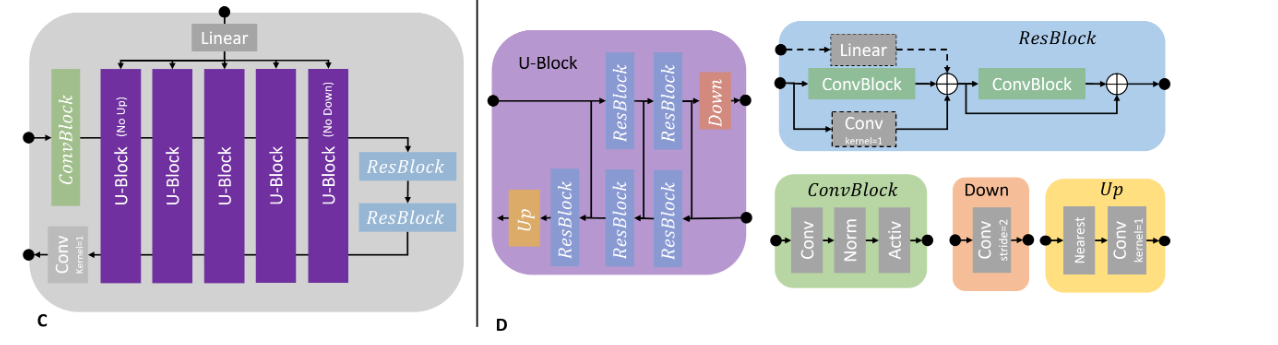
二、模型架构以及训练细节
Medfusion是基于stable diffusion模型,由两部分组成:
1.Autoencoder:将图像空间进行编码作为压缩的潜在空间。Autoencodr的损失由嵌入损失和重建损失组成。我们采用嵌入空间和高斯白噪声之间的 Kullback-Leibler 散度作为嵌入损失。输入图像和重建输出图像之间的重建损失计算为绝对距离(L1)、学习感知图像补丁相似度(LPIPS)、结构相似性指数度量(SSIM)和PatchGAN判别器的总和。
2.DDPM

因此,训练部分也分成了两个阶段分别训练Autoencoder和DDPM。
第一个训练阶段:训练自动编码器,解码器将图像空间编码为 8 倍压缩的潜在空间,比如将大小分别为 256x256 和 512x512 的输入空间压缩为 32x32 和 64x64。的潜在空间,之后解码器,将潜在空间直接解码回到图像空间,并由多分辨率损失函数进行监督,下面是自动编码器的框架图:

第二个训练阶段:在之前预训练的自动编码器将图像空间编码为潜在空间后,然后使用 t=1000 步将其扩散为高斯噪声。UNet模型用于对潜在空间进行去噪,自动编码器的权重在第二训练阶段被冻结。最后使用去噪扩散隐式模型 (DDIM) 和 t=150 步生成样本。UNet模型以及各模块架构如下所示:
三、实验结果
文章当中使用了三个公开可用的数据集,分别是:
1.AIROGS 挑战训练数据集,包含来自约 60,357 名受试者的 101,442 张 256x256 RGB 眼底图像,其中 98,172 名受试者患有“无可参考青光眼”,3,270 名受试者患有“可参考青光眼”。受试者的性别和年龄未知。
2.CRCDX数据集,包含 19,958 个颜色归一化的 512x512 RGB 组织学结直肠癌图像,分辨率为 0.5 μm/px。一半的图像分别是微卫星稳定的和微卫星不稳定的。受试者的性别和年龄未知。
3.CheXpert训练数据集,包含 64,540 名患者的 223,414 张灰度胸片。排除侧位拍摄的图像,留下来自 64,534 名患者的 191,027 张图像。所有图像均缩放至 256x256 并在 -1 和 1 之间标准化。在其余的 X 光片中,23,385 例显示心脏扩大(心脏肥大),7869 例未显示心脏肥大,159,773 例状态未知。状态未知的标签重新标记,分别有 160,935 张图像没有心脏扩大,30,092 张图像有心脏扩大。
文章当中的实验部分两项:
1.研究了 Medfusion 模型中自动编码器的容量是否足以将图像编码到潜在的、高度压缩的空间中,并将潜在空间解码回图像空间而不丢失相关的医疗细节。还研究了稳定扩散模型的自动编码器(在自然图像上预先训练)是否可以直接用于医学图像,即无需对医学图像进行进一步训练并且不会丢失医学相关图像细节。
2.其次,定量和定性地比较了 Medfusion 和 GAN 生成的图像。对于定量评估,使用各个指标进行对比。对于进行定性评估,并排比较了真实图像、GAN 生成的图像和 Medfusion 生成的图像。
1.评估自动编码器的重建能力
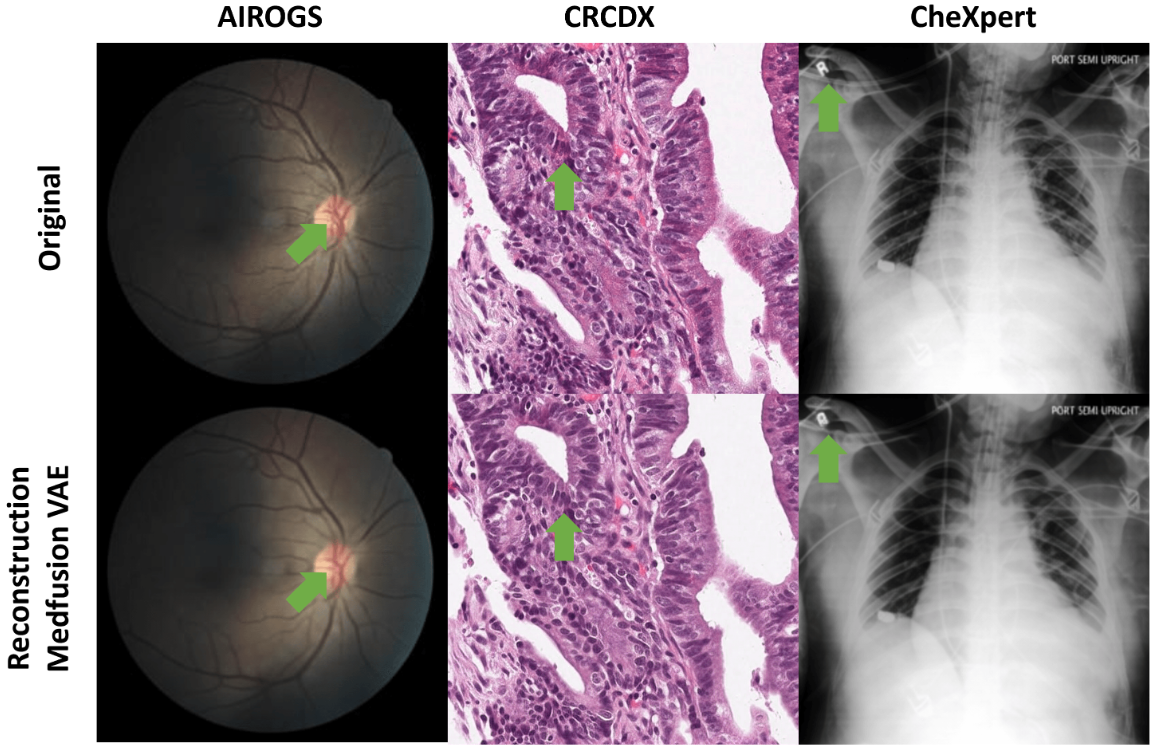
作者首先研究了由于自动编码器架构而可能造成的图像质量损失。这里采用的VAE应该是压缩为8通道的潜在空间。为了评估最大可能的质量,参考批次中的样本由自动编码器进行编码和解码。随后,计算并平均输入图像和重建图像之间的MS-SSIM和均方误差(MSE),如下图所示。这两个指标都表明 AIROGS 和 CheXpert 数据集中的图像重建近乎完美(MS-SSIM = 1,MSE=0)。 该实验表明,DDPM 的自动编码器架构不会限制在数值指标方面合成的图像质量。

下面的实验是比较了原始图像和重建图像,以调查自动编码过程中是否存在定性自动编码器重建错误。
为了调查是否可以在自动编码阶段通过较少的压缩来解决这个问题,通过由进行了以下的实验:
与从稳定扩散模型中取出的自动编码器进行比较表明,使用在自然图像上预训练的自动编码器可以很好地重建医学图像,如下表所展示。

当并排比较图像时,当使用 Stable Diffusion 的默认 VAE(具有 4 个通道)时,Stable Diffusion 在 CheXpert 数据集中显示出特征重建错误(图 3)。尽管不太严重,但在 Medfusion 的 VAE 重建中重建错误也很明显。可训练参数数量的进一步增加似乎并不合理,因为 Stable Diffusion 4 通道 VAE 的参数数量大约是 Medfusion 4 通道 VAE(2400 万)的三倍。因此,作者将通道数量从 4 个增加到 8 个,以牺牲压缩比为代价获得了显着的质量增益。这些结果表明,DDPM 的自动编码架构可以在自动编码阶段受益于更多数量的通道。

2.Medfusion与GAN进行比较
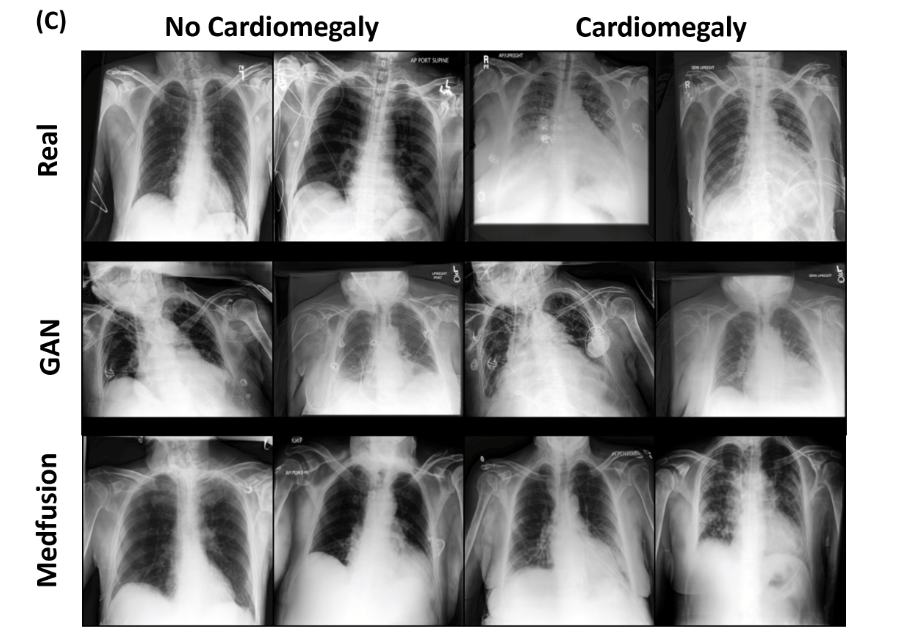
下表展示出Medfusion 在所有三个数据集中生成的图像比相应的 GAN 模型更逼真。数值指标证实了这一点:精确率和召回率值表明,与 GAN 模型相比,Medfusion 具有更高的保真度,同时保持了图像之间更大的多样性。

下图给出了用于定性比较的样本图像。我们发现 DDPM 始终生成比 GAN 更真实、更多样化的合成图像。
四、总结
本文提出了一个Medfusion架构模型,该模型本质上是应用于2d医学图像任务的条件潜在扩散模型,而这里的条件在代码中看只是简单的标签条件,该模型在三个数据集AIROGS 、CRCDX和 CheXpert上生成图像的质量都击败了GAN。并且作者还评估了自动编码器在这些数据集上自动重建能力,表明使用在自然图像上预训练的自动编码器虽然可以很好地重建医学图像,但无论是定性还是定量结果来看都还是比不过直接用医学图像数据训练的自动编码器的效果要好,但作者并没有使用stable diffsuion自然图像上预训练的自动编码器(通道为8),所以是否哪种效果好,还需要进一步实验去发现。