
一、前言
对于DDPM一个最大的缺点:需要设置较长的扩散步数T才能得到比较好多效果,生成过程可能有数千步骤,这导致了生成样本的速度较慢。我们可以把问题关注到两个问题方面,第一点就是DDPM为什么一定要这么多次采样,是否能减小T?第二点为什么非要一步步降噪,跳步行不行?
1) 是否能减小T?
回到DDPM的扩散过程公式:\(x_t=\sqrt{\bar{a}_t}x_0 + \sqrt{1-\bar{a}_t}\epsilon-(1)\)。其中\(\textcolor{blue}{\bar{\alpha}_T = \prod_{i=1}^T\alpha_i}\),我们希望在T时刻,\(\textcolor{blue}{x_T}\)尽量服从标准正态分布。因此希望\(\textcolor{blue}{\sqrt{\bar{\alpha}_T}}\)接近于0,\(\textcolor{blue}{\sqrt{1-\bar{\alpha}_T}}\)接近于1。在\(\textcolor{blue}{\bar{\alpha}_T}\)接近0的前提下,因为\(\textcolor{blue}{\beta_t}\)的值是会T的增大越来越小,从而导致累乘之后\(\textcolor{blue}{\bar{\alpha}_T}\)也越来越小,所以只能让T尽可能的大,才能满足我们最终的需求。这就是为什么T的取值不能太小的原因。
2) 为什么非要一步步降噪,跳步行不行?
注意,我们的优化目标虽然是噪声\(\textcolor{blue}{\epsilon}\)的MSE,但实际这只是重参数化(reparameterization)的结果。我们的优化终极目标实际上是去拟合概率分布\(\textcolor{blue}{q(x_{t-1}|x_t,x_0)}\)。而我们求得这个分布均值的方法是用的贝叶斯公式:
\[\textcolor{blue}{\huge q(x_{t-1}|x_t,x_0) = q(x_t|x_{t-1}) * \frac{q(x_{t-1}|x_0)}{q(x_t|x_0)}-(2)}\]
注意右边第一项的\(\textcolor{blue}{q(x_t|x_{t-1})}\)是\(\textcolor{blue}{q(x_t|x_{t-1},x_0)}\)根据马尔可夫性质得来,因此我们的采样必须要严格遵照马尔可夫性质,是必须从\(\textcolor{blue}{x_t}\)到\(\textcolor{blue}{x_{t-1}}\)一步步来,不能跳步
3)如果我们用神经网络预测出了噪音,由于DDPM的扩散公式,我们是否可以倒推一下,直接移向由\(x_t\)直接得出\(x_0\)行不行?
\[\huge \textcolor{blue}{x_0 = \frac{1}{\sqrt{\bar{a}_t}}(x_t - \sqrt{1-\bar{a}_t}\epsilon)-(3)}\]
这个问题和第二个是一样的,就是我一开始刚刚认识DDPM的时候也时常有这个问题,所以一并在这解释一下做个记录,这是由于\(x_t=\sqrt{\bar{a}_t}x_0 + \sqrt{1-\bar{a}_t}\epsilon\)也是在DDPM中由马尔可夫推导出来的,如果直接从\(x_t\)到\(x_t\)是不符合马尔可夫性质的。
由于DDPM定义的前向是马尔科夫链,但是这使得反向采样时也必须是马尔可夫过程,使得每一个状态都只受前一个状态的影响,所以训练多少步,就需要采样多少步,从而速度十分缓慢。而不能跳步是由于马尔可夫性质,那么作者就设想我们是否可以采用非马尔可夫性质的前向过程。
DDIM的初衷是希望在保留原有训练目标的前提下尽可能加速DDPM的采样生成过程。在具体的建模上,DDIM使用了非markov链的前向过程来重新建模DDPM的训练目标,得到了同一训练目标的不同建模方式。通过新的非markov链的建模方式,DDIM可以高效地进行采样生成,并且采样生成的过程是具有确定性的,即同样的初始隐变量生成的图片在high-level的特征上是相似的,因此可以通过操纵隐变量来进行图像的插值,而DDPM没有这一性质,隐变量是完全没有含义的。虽然训练目标与DDPM一致,但DDIM可以很好地权衡采样生成的效率和质量,在通过减少逆向步数而加速10~100倍的情况下在生成质量上大幅超过DDPM,不过从实验结果来看,在不进行加速时DDIM的效果与DDPM相差不大。
二、DDIM的基本原理
1、DDIM是如何去掉马尔可夫化的?
如果保持现有的建模方式不变的话,那逆向过程的框架是无法改变的,至多通过加大生成时的采样间隔(例如每隔10步采样一次,总采样次数从1000变为100)来加速,但会大幅牺牲采样质量。因此我们希望找到一种新的建模前向和逆向过程的方式,使得最后的目标函数不变,但可以在生成时有加速效果。我们回到这个公式当中:
\[\huge \textcolor{blue}{q(x_{t-1}|x_t,x_0) = q(x_t|x_{t-1}) * \frac{q(x_{t-1}|x_0)}{q(x_t|x_0)}}\]
如果我们想要去马尔可夫化,则代表\(\textcolor{blue}{q(x_t|x_{t-1},x_0) \neq q(x_t|x_{t-1})}\),我们可以回顾在DDPM当中的\(\textcolor{blue}{q(x_t|x_{t-1},x_0) = q(x_t|x_{t-1})=\mathcal{N}(x_t;\sqrt{\alpha_t}x_{t-1},(1-\alpha_t)I)}\)去发现一个细节,就是其实在DDPM中没有直接用到\(\textcolor{blue}{q(x_t|x_{t-1})}\),而是用边缘分布\(\textcolor{blue}{q(x_t|x_0)}\)一步到位的,所以作者这里提出了很大胆的假设:就是其实前向过程\(\textcolor{blue}{q(x_t|x_{t-1},x_0)}\)长什么样并不重要,我们只要设法推出\(\textcolor{blue}{q(x_{t-1}|x_t,x_0)}\)就可以了,当然,这个分布也不能随便设,必须要满足一定条件,而这个条件就是我们必须让(1)式依然成立。因为我们的前向训练过程是用到了(1)式的,所以为了让前向过程不变,我们要确保(1)式依然成立。
那么问题就简化了,我们可以用待定系数法求解,假设:
\[\huge \textcolor{blue}{q(x_{t-1}|x_t,x_0)=\mathcal{N}(kx_0+mx_t,\sigma^2I)-(4)}\]
根据重参数化技巧,我们有:
\[\huge \textcolor{blue}{x_{t-1} = kx_0+mx_t+\sigma\epsilon-(5)}\]
由于我们假设了等式1成立,于是乎我们可以得到:\(\textcolor{blue}{x_t=\sqrt{\bar{a}_t}x_0 + \sqrt{1-\bar{a}_t}\epsilon^\prime}\),其中\(\textcolor{blue}{\epsilon^\prime,\epsilon}\)都服从标准正态分布,将这个式子代入到式(5)我们可以得到:
\[\huge \textcolor{blue}{x_{t-1} = kx_0+m(\sqrt{\bar{a}_t}x_0 + \sqrt{1-\bar{a}_t}\epsilon^\prime)+\sigma\epsilon}\]
合并同类项:
\[\huge \textcolor{blue}{x_{t-1} = (k+m\sqrt{\bar{a}_t})x_0 + m\sqrt{1-\bar{a}_t}\epsilon^\prime+\sigma\epsilon}\]
由于\(\epsilon^\prime,\epsilon\)都服从标准正态分布,因此两者可合并为同一个正态分布且服从\(\textcolor{blue}{\mathcal{N}(0,m^2(1-\bar{\alpha}_t)+\sigma^2)}\)
\[\huge \textcolor{blue}{x_{t-1} = (k+m\sqrt{\bar{a}_t})x_0 + \sqrt{m^2(1-\bar{\alpha}_t)+\sigma^2}\epsilon}\]
接下来求解k,m,因为要满足\(\textcolor{blue}{x_t=\sqrt{\bar{a}_t}x_0 + \sqrt{1-\bar{a}_t}\epsilon}\),所以有:
\[\huge \textcolor{blue}{\left\{\begin{array}{c}k+m\sqrt{\bar{a}_t}=\sqrt{\bar{\alpha}_{t-1}}\\\sqrt{m^2(1-\bar{\alpha}_t)+\sigma^2}=\sqrt{1-\bar{\alpha}_{t-1}}\end{array}\right.}\]
我们可以进一步得到:
\[\Large \textcolor{blue}{m=\frac{\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}}{\sqrt{1-\bar{\alpha}_t}},k=\sqrt{\bar{\alpha}_{t-1}}-\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}\frac{\sqrt{\bar{\alpha}_t}}{\sqrt{1-\bar{\alpha}_t}}}\]
将m,k都代入到式(4)中:
\(\begin{aligned} \end{aligned}\)\(\begin{aligned}kx_0+mx_t&=\sqrt{\bar{\alpha}_{t-1}}x_0-\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}\frac{\sqrt{\bar{\alpha}_t}}{\sqrt{1-\bar{\alpha}_t}}x_0 + \frac{\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}}{\sqrt{1-\bar{\alpha}_t}}x_t\\&=\sqrt{\bar{\alpha}_{t-1}}x_0 + \sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}\frac{x_t-\sqrt{\bar{\alpha}_t}x_0}{\sqrt{1-\bar{\alpha}_t}}\end{aligned}\)
最终,我们可以得到新分布:
\[\huge \textcolor{blue}{q(x_{t-1}|x_t,x_0)=\mathcal{N}(\sqrt{\bar{\alpha}_{t-1}}x_0 + \sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}\frac{x_t-\sqrt{\bar{\alpha}_t}x_0}{\sqrt{1-\bar{\alpha}_t}},\sigma^2I)-(6)}\]
这就是我们新的反向生成分布,也就是我们新的要去拟合的“终极目标”。在式(1)的前提下,我们不借助马尔可夫性质成功推出了反向生成分布\(\textcolor{blue}{q(x_{t-1}|x_t,x_0)}\),这样如此我们就可以顺理成章的把前向过程改成非马尔可夫过程如下所示:
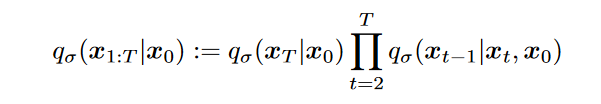
其中,\(\textcolor{blue}{\sigma \in R_{\geq 0}^T}\)代表了每步扩散的随机程度(即方差)。其中\(\textcolor{blue}{q_\sigma(x_T|x_0) = \mathcal{N}(x_T;\sqrt{\bar{\alpha}_T}x_0,(1-\bar{\alpha}_T)I)}\),注意其实论文的\(\textcolor{blue}{\bar{\alpha}_t}\)被\(\textcolor{blue}{\alpha_t}\)取代了,而我这里方便与DDPM的形式对应方便理解,就采用了DDPM中一样的表达形式。而 \(\textcolor{blue}{q_\sigma(x_{t-1}|x_t,x_0)=\mathcal{N}(\sqrt{\bar{\alpha}_{t-1}}x_0 + \sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}\frac{x_t-\sqrt{\bar{\alpha}_t}x_0}{\sqrt{1-\bar{\alpha}_t}},\sigma^2I)}\)
此时前向过程已不一定是markov链,而是每一步都可能与\(x_0\)有关,图1展示了和原来的建模的对比。

图1:Markov与non-Markov的diffusion过程对比
不同的\(\textcolor{blue}{\sigma \in R_{\geq 0}^T}\)取值对应了不同的过程。当\(\textcolor{blue}{\sigma \rightarrow 0}\)时,整个过程达到一个极端,随机性消失,\(\textcolor{blue}{x_t}\)和\(\textcolor{blue}{x_0}\)有唯一的映射关系,中间变换的路径也是唯一确定的,模型变为Implicit probabilistic model 。这也是DDIM名字的由来。在论文中,DDIM特指\(\textcolor{blue}{\sigma}\)为0的特例,但为了后续说明方便,我们将\(\textcolor{blue}{\sigma}\)取其他值的模型也称为DDIM。后面我们也会证明,当\(\textcolor{blue}{\sigma}\)为某个特定值时,DDIM模型会退化为DDPM模型。而前向的过程虽然变得复杂了,但因为目标函数与DDPM是一致的,且只依赖边际分布\(\textcolor{blue}{q_\sigma(x_t|x_0)}\),而这一分布是容易计算的,所以生成训练数据\(\textcolor{blue}{x_t}\)和训练的过程仍然和DDPM一样方便。
2、模型拟合的逆过程
虽然\(\textcolor{blue}{q_\sigma(x_{t-1}|x_t,x_0)}\)是有解析式,但生成过程中我们并不知道\(\textcolor{blue}{x_0}\),所以模型仍然在逆向过程中建模的是\(\textcolor{blue}{p_\theta^{(t)}(x_{t-1}|x_t)}\),并通过单向的Markov链采样生成最后的\(\textcolor{blue}{x_0}\)。在原DDPM的推导当中,实际上我们模型预测的是噪声\(\textcolor{blue}{\epsilon_\theta(x_t,t)}\),因此我们可以根据式(3)得到模型预测的\(\textcolor{blue}{x_0}\):
\[\Large \textcolor{blue}{\hat{x}_0 = \frac{1}{\sqrt{\bar{a}_t}}(x_t - \sqrt{1-\bar{a}_t}\epsilon_\theta(x_t,t))-(7)}\]
之后我们再通过\(\textcolor{blue}{q_\sigma(x_{t-1}|x_t,x_0)}\)得到模型预测的\(\textcolor{blue}{\hat{x}_{t-1}}\):
\[\Large \textcolor{blue}{\hat{x}_{t-1}=\sqrt{\bar{\alpha}_{t-1}}\hat{x}_0 + \sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}\frac{x_t-\sqrt{\bar{\alpha}_t}\hat{x}_0}{\sqrt{1-\bar{\alpha}_t}} + \sigma_t z -(8)}\]
由于文中指定\(\textcolor{blue}{\bar{\alpha}_0=1}\),而\(\textcolor{blue}{\sigma_t>0}\),因此这里在\(\textcolor{blue}{t=1}\)时需要处理一下边界,否则\(\textcolor{blue}{\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}}\)一项低数是负数。处理的方法文字是直接把这项给去除,在t=1时最终预测\(\textcolor{blue}{x_0 = \hat{x}_0 + \sigma_1z}\)。综合起来我们可以得到:
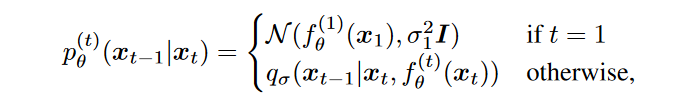
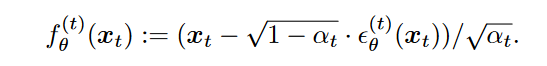
将式(7)代入到式(8)当中,最终我们可以得到采样\(\textcolor{blue}{x_{t-1}}\)的公式:

3、目标函数
我们也可以推导出这样的建模下的目标函数与DDPM的\(\textcolor{blue}{\mathcal{L}_\gamma}\)是一致的,模型预测分布\(\textcolor{blue}{p_\theta(x_0)}\)和真实数据分布\(\textcolor{blue}{q_\sigma(x_0)}\)的交叉熵仍然和DDPM的推导过程一致:
\[\Large \textcolor{blue}{\mathcal{L}_{ce}=-E_{x_0 \sim q_\sigma(x_0)}[logp_\theta(x_0)] \leq E_{x_{0:T} \sim q_\sigma(x_{0:T})}[log\frac{q_\sigma(x_{1:T}|x_0)}{p_\theta(x_{0:T})}]=J_\sigma(\epsilon_\theta)}\]
而由于,之前提到的前向公式以及预测模型的联合分布:

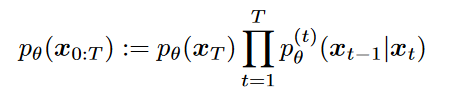
将这两个等式代入到\(\textcolor{blue}{J_\sigma(\epsilon_\theta)}\)来对其进行变形,并把与参数无关项并入C:

其中对于t>1有:
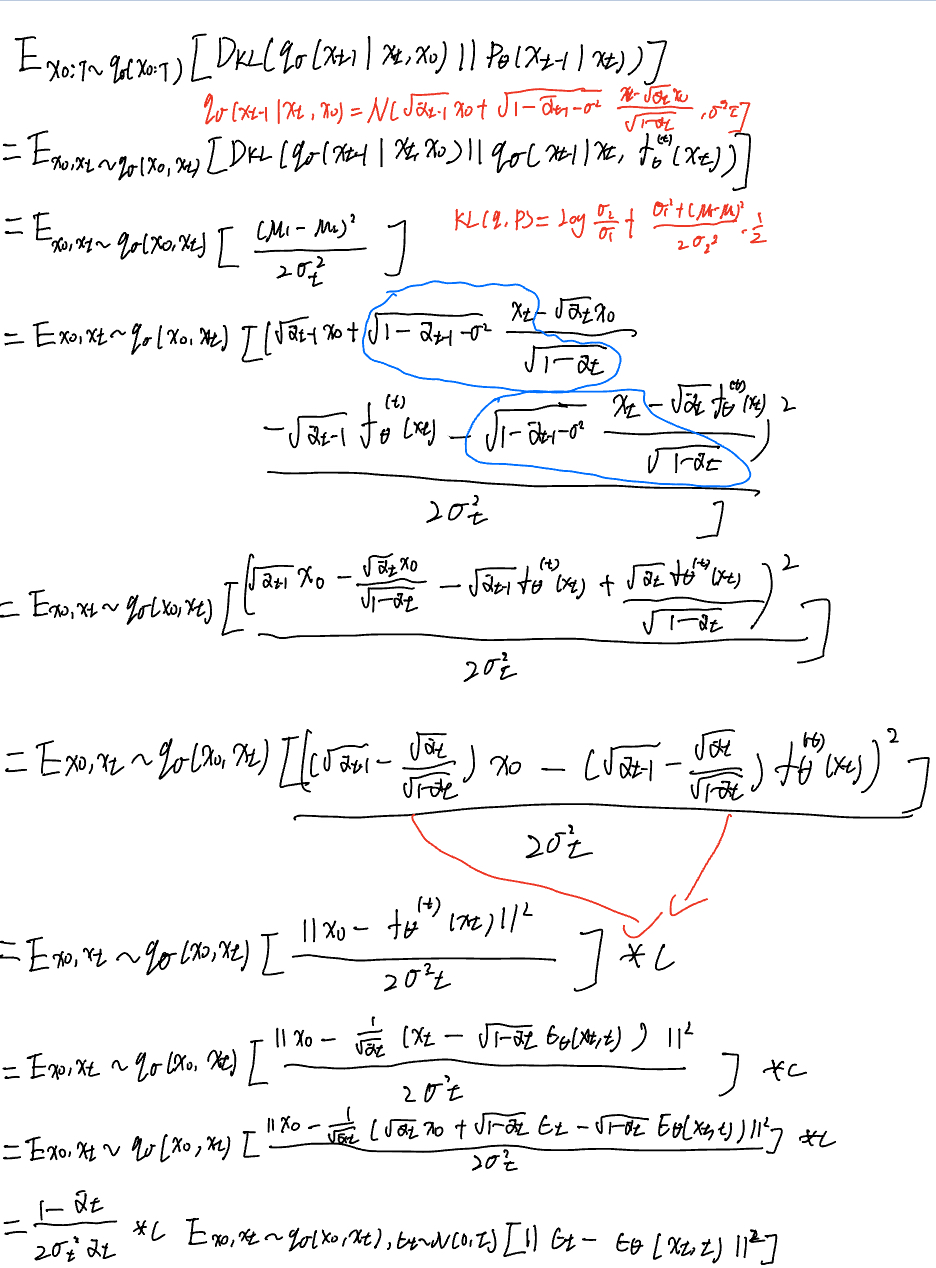
对于t=1有:
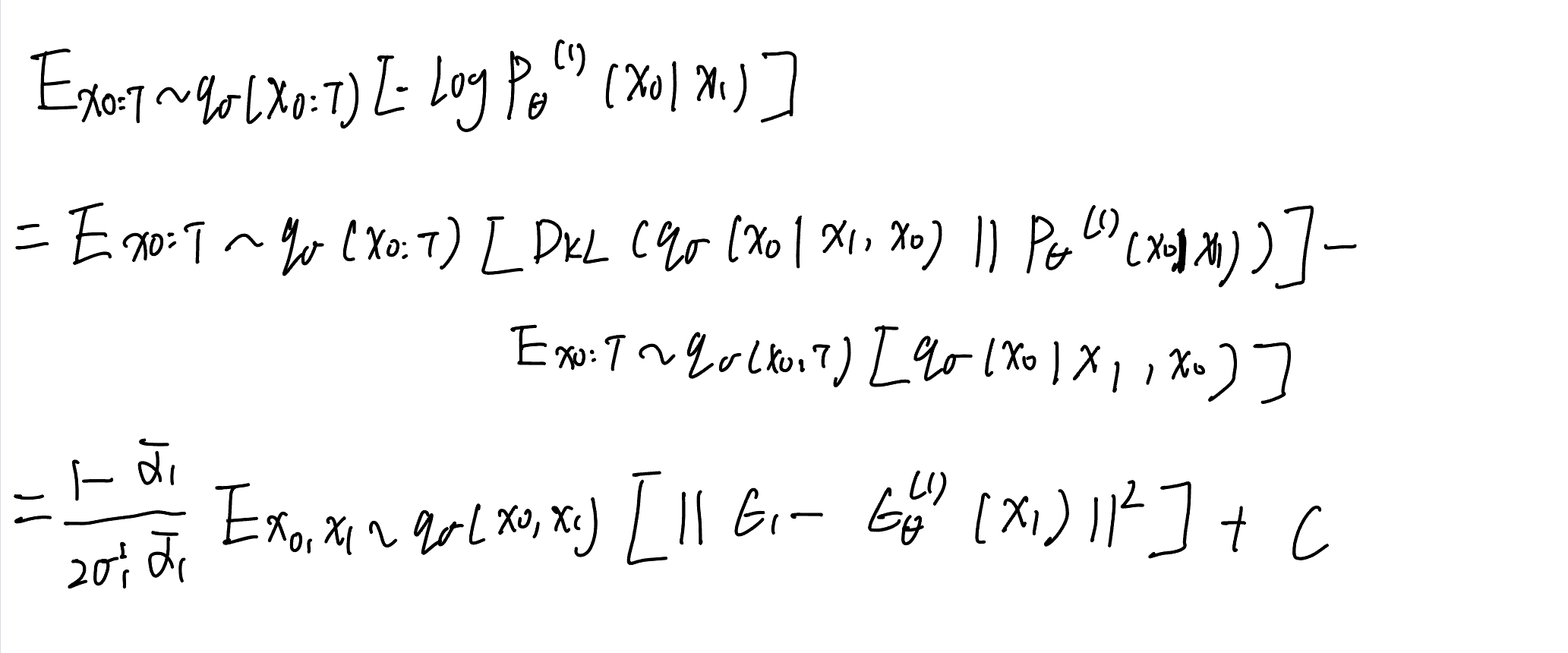
所以整体有:
\[\Large \textcolor{blue}{J_\sigma(\epsilon_{\theta})=\sum\limits_{t=1}^T\frac{1-\bar{\alpha}_t}{2\sigma_t^2\bar{\alpha}_t}E_{x_0,x_t \sim q_\sigma(x_0,x_t),\epsilon_t \sim \mathcal{N}(0,I)}[||\epsilon_t-\epsilon_\theta^{(t)}(x_t)||^2]+C = \mathcal{L}_\gamma(\epsilon_\theta)+C}\]
其中\(\textcolor{blue}{\gamma_t=\frac{1-\bar{\alpha}_t}{2\sigma_t^2\bar{\alpha}_t}}\),去掉常数C之后即\(\textcolor{blue}{J_\sigma(\epsilon_{\theta})}\)与\(\textcolor{blue}{\mathcal{L}_\gamma(\epsilon_\theta)}\)等价。而DDPM中直接将\(\textcolor{blue}{\gamma_t}\)简化为1,因为从优化角度而言,每步t对应的参数是相互独立的,因此最小化所有项加权求和的最优解等价于单独最小化每一项得到的最优解。而不同的\(\textcolor{blue}{\sigma}\)取值产生的目标函数的区别只在于不同的\(\textcolor{blue}{\gamma_t}\),也就是说令\(\textcolor{blue}{\gamma_t=1}\)得到的简化目标函数\(\textcolor{blue}{\mathcal{L}_1(\epsilon_\theta)}\)所训练出来模型是对于任意\(\textcolor{blue}{\sigma}\)通用的!因此我们可以用DDPM论文中训练的模型结合DDIM的采样方式进行采样,并且可以尝试选取不同的\(\textcolor{blue}{\sigma}\)(这代表不同的过程,但都满足DDIM的框架)。
4、与DDPM的关系
其实我们从目标函数的推导中可以看出,DDPM和DDIM的训练目标其实都是让预测的分布\(\textcolor{blue}{p_\theta(x_{t-1}|x_t)}\)尽可能与分布\(\textcolor{blue}{q_\sigma(x_{t-1}|x_t,x_0)}\)接近。我们比较在DDPM的markov链建模以及DDIM的非markov链建模下的\(\textcolor{blue}{q_\sigma(x_{t-1}|x_t,x_0)}\):
DDPM:\(q_\sigma(x_{t-1}|x_t,x_0)=\mathcal{N}(\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0,\frac{1-\bar{a}_{t-1}}{1-\bar{a}_t}\beta_t I)\)
DDIM:\(q_\sigma(x_{t-1}|x_t,x_0)=\mathcal{N}(\sqrt{\bar{\alpha}_{t-1}}x_0 + \sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}\frac{x_t-\sqrt{\bar{\alpha}_t}x_0}{\sqrt{1-\bar{\alpha}_t}},\sigma_t^2I)\)
如果我们取\(\textcolor{blue}{\sigma_t=\sqrt{\frac{1-\bar{a}_{t-1}}{1-\bar{a}_t}\beta_t}}\)的话,我们就可以发现两者的\(\textcolor{blue}{q_\sigma(x_{t-1}|x_t,x_0)}\)变成一样的了:
\[\Large \textcolor{blue}{\sigma_t^2 = \frac{1-\bar{a}_{t-1}}{1-\bar{a}_t}\beta_t}\]

理所当然地,生成过程每步更新的方程也会一致。通过以上证明其实DDPM只是DDIM在取\(\textcolor{blue}{\sigma_t=\sqrt{\frac{1-\bar{a}_{t-1}}{1-\bar{a}_t}\beta_t}}\)时得到的特例。
5、加速采样过程
之前的分析告诉我们,只要我们选定一种满足DDIM定义的过程,在T固定的情况下,训练的过程是一致的,模型可以在不同过程间复用而不用重新训练。我们更希望使用同样的模型在更小的T下进行生成,而这其实也是可行的,我们只需要定义一个步数小于T的过程,并且保证边际分布仍然与原来相同即可。例如我们考虑原本生成序列的一个子序列\(\textcolor{blue}{(x_{\tau_{1}},x_{\tau_{2}},...,x_{\tau_{S}})}\),其中{\(\tau_i\)}是长度为S的[1,...,T]的升序子序列。我们可以找到特殊的\(\textcolor{blue}{\sigma \in R_{\geq 0}^T}\)来定义一个过程,使得\(\textcolor{blue}{q(x_{\tau_i}|x_0)=\mathcal{N}(\sqrt{\bar{\alpha}_{\tau_i}}x_0,(1-\bar{\alpha}_{\tau_i})I)}\)此时我们仍可以使用总步长为T下训练的模型来进行生成,因为新的过程的训练目标其实是原始的\(\textcolor{blue}{\mathcal{L}_1}\)求和中对应的S项的和,而每一项之间又是参数独立、互不影响的,因此训练完步长为T的模型其实包含了步长为S的模型。例如文中就取了原始T=1000的DDPM模型,测试了S∈{10,20,50,10}的结果,并且比对了选取不同的\(\textcolor{blue}{\sigma}\)时的结果。为了方便,文中固定\(\textcolor{blue}{\sigma}\)的形式为\(\textcolor{blue}{\eta\sqrt{\beta_{\tau_i}(1-\bar{\alpha}_{\tau_{i-1}})/(1-\bar{\alpha}_{\tau_i})}}\),通过调节\(\textcolor{blue}{\eta}\)的值来调整\(\textcolor{blue}{\sigma}\)(即调整模型的随机性),当\(\textcolor{blue}{\eta=0}\)时为确定性的DDIM,当\(\textcolor{blue}{\eta=1.0}\)是为DDPM,\(\textcolor{blue}{\hat{\sigma}}\)是DDPM论文中调参得出的超参。实验的结果在下表中:
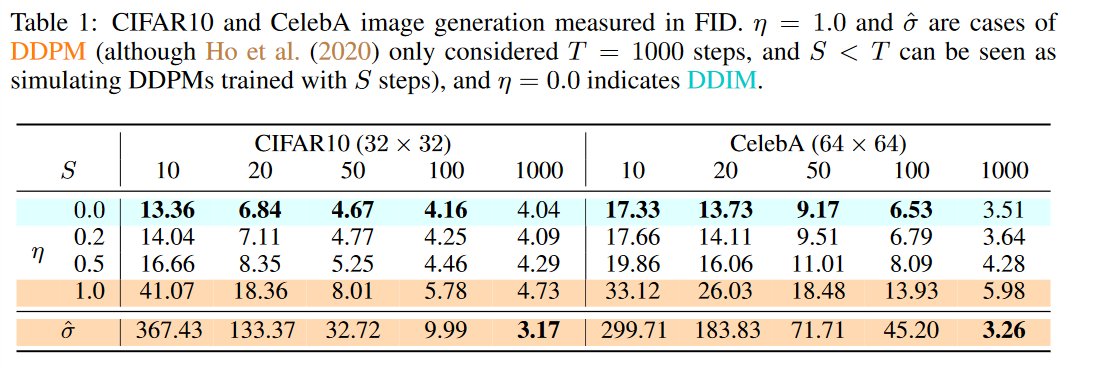
可以看到的是在减小S大小,即加速生成时,生成的质量都在下降,只是DDPM的下降速度会快很多,而DDIM则下降慢很多。这个实验其实告诉我们DDIM可以通过调控采样步数S来权衡采样的速度和质量,且随机性\(\sigma\)会对这个权衡造成影响,确定性的DDIM看起来是最好的,DDPM在这个权衡下则是最差的。
6、采样的一致性与插值
前面也提到,在DDIM的架构中,\(\textcolor{blue}{\sigma}\)的大小其实代表的是整个过程的随机性。当\(\textcolor{blue}{\sigma=0}\)时,整个过程完全没有随机性,为Implicit probabilistic model,即同样的\(\textcolor{blue}{x_t}\)只能解码出同样的\(\textcolor{blue}{x_0}\)。而\(\textcolor{blue}{\sigma_t=\sqrt{\frac{1-\bar{a}_{t-1}}{1-\bar{a}_t}\beta_t}}\)时,为DDPM,从实验结果来看是随机性非常大的,同样的\(\textcolor{blue}{x_T}\)几乎每次解码的结果都大相径庭。对于\(\textcolor{blue}{\sigma=0}\)的情况,即使我们取不同的解码路径{\(\tau_i\)},按理说同一\(\textcolor{blue}{x_T}\)解码出的\(\textcolor{blue}{x_0}\)仍然会有一定的一致性(相似性),从而说明\(\textcolor{blue}{x_T}\)对应的隐空间具有了语义信息。文中就对这一推论进行了验证,通过编码教堂的图片得到的\(\textcolor{blue}{x_T}\)进行多次解码(选取不同的{\(\tau_i\)}),得到的图片基本都是教堂,在high-level的特征上是非常相似的:

当隐空间具有语义之后,就可以进行图片的插值,对于DDIM,两个不同的随机噪音会产生不同的图像,但是如果我们对这两个随机噪音进行插值生成新的\(\textcolor{blue}{x_T}\),那么将生成融合的图像。这里采用的插值方法是球面线性插值( spherical linear interpolation):
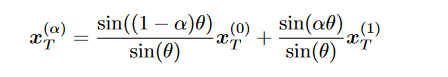

三、总结
由于DDPM是基于马尔可夫链建立起来的前向/逆向过程,因此不能“跳步”生成图像,且为了保证 \(\textcolor{blue}{x_T \sim \mathcal{N}(0,1)}\), T不能过小,因此自然会导致采样慢、出图效率低的缺点。而DDIM这篇文章介绍的方法,巧妙地通过自行设计优化目标\(\textcolor{blue}{q_\sigma(x_{t-1}|x_t,x_0)}\),将马尔可夫的限制取消,在不影响DDPM中的边界分布的情况下大大缩短了采样步数。这样做的好处是,训练好的DDPM可以直接拿来通过DDIM的采样方法进行采样,不需要再去训练一次。